从零复现Llama3代码库爆火 Karpathy大神称赞作者是个有品的人
最近,一个教你从头开始实现Llama3的代码库在网上爆火,吸引了无数开发者的关注。知名AI专家Andrej Karpathy一键三连(点赞、转发、评论),这个项目在社交媒体X上的转赞收藏量超过6.8k,GitHub上更是收获了超过2k的星标。
这个代码库的作者是Nishant Aklecha(以下简称“纳哥”),他详细解释了Llama3模型的实现过程,包括注意力机制中多个头的矩阵乘法、位置编码及所有中间层的详细展开和解释。换句话说,他解释了每行代码的功能。
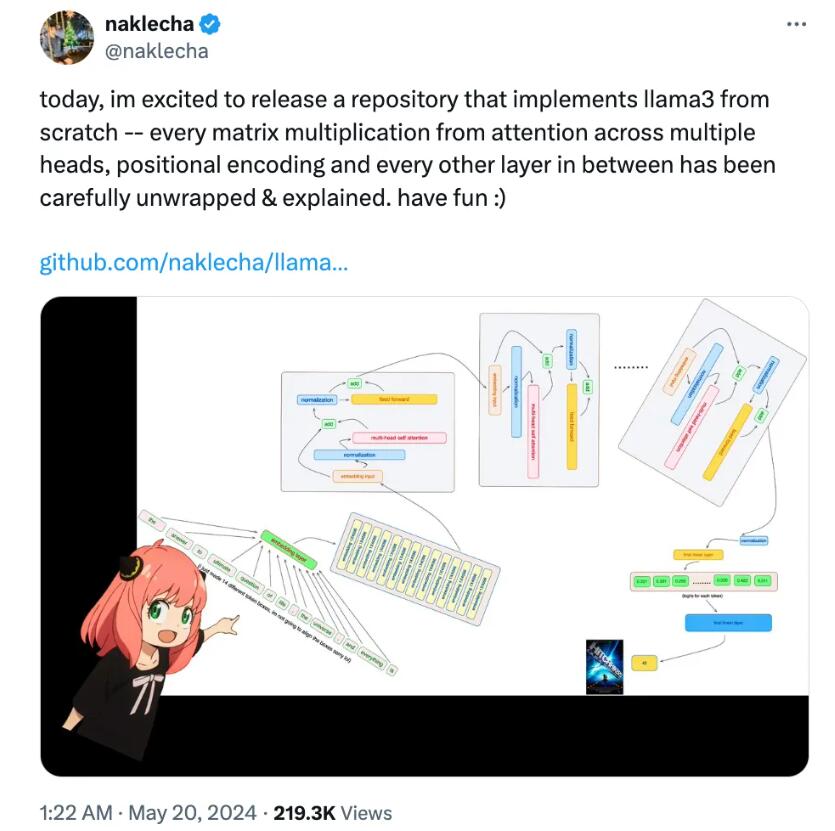
Karpathy称赞纳哥是个“有品的人”,并指出这样的详细展开比起模块相互嵌套和调用时更容易理解每一步具体在做什么。
在运行纳哥提供的文件前,需要预先下载Meta官方提供的Llama3模型权重。纳哥建议使用Karpathy的简洁版BPE代码进行分词。字节级(byte-level)BPE算法在UTF-8编码的字符串上运行,广泛应用于大模型分词。Karpathy提供的代码库包含两个分词器,都能在给定文本上训练分词器的词汇表和合并规则、将文本编码为token、将token解码为文本。
读取模型文件的方式通常取决于模型类的编写方式以及类中变量的命名。但由于纳哥是从头开始实现Llama3,所以将逐个张量地读取文件内容,通过此配置推断出模型的结构和参数信息。
纳哥详细展示了如何将token转换为高维的嵌入表示,并进行RMS归一化。然后,他构建了Transformer的第一层,进行归一化处理和注意力头的加载。接着,纳哥详细解释了query、key和value向量的生成和操作,包括位置编码的使用和注意力得分矩阵的生成与掩码处理。最后,他展示了如何将这些向量进行矩阵乘法,得到最终的注意力值。
接下来,纳哥对每个注意力头执行相同的数学运算,并将所有注意力得分合并成一个大的qkv_attention矩阵。然后通过矩阵乘法获得注意力机制后的嵌入值,并将其添加到原始的token嵌入中,进行归一化处理,并通过一个前馈神经网络进行处理。
纳哥使用最终的嵌入预测下一个token值,并希望预测结果是42,这个数值对应《银河系漫游指南》中“生命、宇宙及一切的终极问题的答案”。模型预测的token编号为2983,对应的正是42。
Nishant Aklecha是Glaive AI的研究员,负责构建和改进定制语言模型平台,曾任职于摩根士丹利,负责训练和微调大语言模型。他还和朋友共同创立了一个研究实验室A10,其目标是让研究变得更加触手可及。
除了发布这个代码库,Nishant还上传了一个YouTube视频详细解释代码库内容,并撰写了一篇博客详解潜在一致性模型(LCM)。
感兴趣的开发者可以访问GitHub链接了解更多信息:https://top.aibase.com/tool/llama3-from-scratch
曾让“三只羊”年营收上亿的直播切片,现在也能用AI做了?
AI剪辑,一条闷声赚大钱的赛道。传统制作中,一条视频的生产流程大致包括前期策划、中期拍摄、后期制作和剪辑分发等环节。AI对这一生产流程的颠覆,行业头部玩家往往把目光放在了前景远大的Sora们身上,却忽略了更为落地且能够解决用户痛点的应用:短视频切片。站长网2024-11-21 09:09:260000巨人网络:计划构建 AI 游戏开发平台 降低开发门槛
巨人网络表示,在2024年春季招聘中首次重点招募AI算法实习生,标志着公司在游戏和人工智能深度融合领域的新动向。招聘对象为2025届海内外高校在校生,涵盖多个技术岗位,旨在培养新一代游戏AI人才加速公司发展。站长网2024-03-19 16:45:500000腾讯:混元大模型已接入180多个业务进行内测
腾讯副总裁蒋杰在2023年世界互联网大会上表示,腾讯混元大模型已接入180多个业务进行内测。腾讯混元大模型在文化沟通、生产提效、科技普惠等领域的应用正在不断深化。在文化沟通方面,腾讯混元大模型的多语种翻译和文生图、文生3D等能力可以帮助人们更好地跨文化交流。在生产效率方面,腾讯混元大模型可以提升素材创作的效率,例如辅助生成原画和设计logo。站长网2023-11-10 09:30:010000List 集合,如何优雅地返回给前端?
1.业务背景业务场景中,一个会话中存在多个场景,即一个session_id对应多个scene_id和scene_name如果你写成如下的聚合模型类publicclassSceneVO{privateStringsessionId;privateStringsceneId;privateStringsceneName;//省略对应的getter和setter方法}0000群智感知 为桥梁延寿——使用智能手机监测桥梁结构健康
美国麻省理工学院的研究人员开发了一款基于Android系统的手机应用程序,并在金门大桥上成功完成测试。用手机程序可在车辆通过桥梁时采集有效数据,然后与桥梁健康监测传感器收集到的数据进行比对,结果表明,两组数据抓取的桥梁振动信息完全相同。预计,智能手机监测可使桥梁结构寿命延长15%至30%,成为一种潜在的桥梁养护监测工具。低廉且高效的数据采集方法站长网2023-05-24 22:56:490002