腾讯开源DiT 图像生成模型 可根据对话上下文生成并细化图像
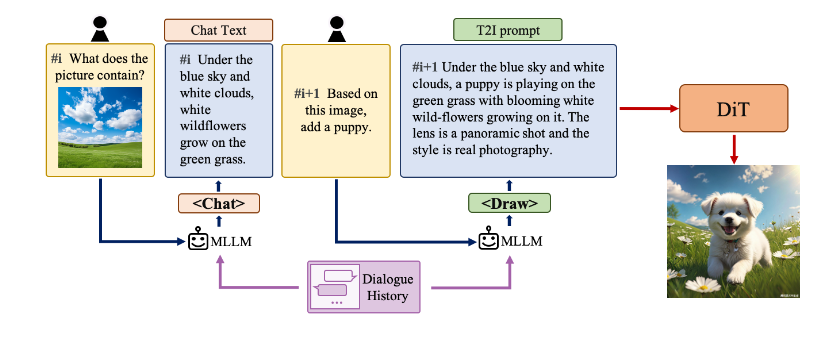
腾讯开源了混元 DiT 图像生成模型,对英语和中文都有着精细的理解能力。Hunyuan-DiT能够进行多轮多模态对话,根据对话上下文生成并细化图像。
Hunyuan-DiT是一种强大的多分辨率扩散变换器,具有细粒度的中文理解能力。它结合了Transformer结构、文本编码和位置编码,并通过训练一个多模态大型语言型来改进图像的描述,从而实现了对中英文的细粒度理解。通过建立完整的数据管道,可以对模型进行迭代优化。
项目地址:https://github.com/Tencent/HunyuanDiT
在Hunyuan-DiT中,采用了Transformer结构,结构在自然语言处理领域取得了巨大的成功。通过多层的自注意力机制和前馈神经网络,Transformer可以有效地捕捉文本之间的关系和上下文信息。
为了更好地理解中文,Hun-DiT采用了文本编码和位置编码。文本编码使用了预训练的词嵌入模型,将文本转化为向量表示。位置编码则是为了捕捉文本中的位置信息,通过给不同的词语分配不同的编码,使得模型能够感知词语的位置关系。
为了改进图像描述,Hunyuan-DiT训练了一个多模态大型语言模型。该模型通过学习文本和图像间的关联,可以生成更准确、更具描述性的图像描述。通过将这个模型与扩散变换器相结合,Hunyuan-DiT可以实现多轮的多模态文本到图像的生成。
Hunyuan-DiT的应用前景非常广泛。它可以用于自然语言处理、图像生成等领域,为这些任务提供了一个强大的工具。同时,Hunyuan-DiT还可以应用于文本编辑、文档生成等任务,提高文本的质量和确性。
综上述,Hunyuan-DiT是一种强大的多分辨率扩散变换器,具有细粒度的中文理解能力。它通过结合Transformer结构、文本编码和位置编码,以及训练一个多模态大型语言型,实现了对中英文的细粒度理解,并在图像生成等任务中取得了显著的效果。
腾讯文档3.0发布:所有类型文件可一站式深度编辑
快科技12月8日消息,腾讯文档客户端3.0发布,无论何时何地,都能畅享强大的Office功能,一站式便捷处理各种格式文件。全新升级的腾讯文档客户端3.0涵盖了Word、Excel、PPT这三大品类,还有doc、docx、xls、xlsx、ppt、pptx这六种格式。站长网2023-12-09 09:26:350000GPT-4o mini实力霸榜,限时2个月微调不花钱,每天200万训练token免费薅
Llama3.1405B巨兽开源的同时,OpenAI又抢了一波风头。从现在起,每天200万训练token免费微调模型,截止到9月23日。Llama3.1开源的同一天,OpenAI也open了一回。GPT-4omini可以免费微调了,每天畅用200万训练token,限时2个月(截止9月23日)。收到邮件的开发者们激动地奔走相告,这么大的羊毛一定要赶快薅。站长网2024-07-27 13:42:550001长推:十大超级加密工具推荐
免责声明:本文旨在传递更多市场信息,不构成任何投资建议。文章仅代表作者观点,不代表MarsBit官方立场。小编:记得关注哦来源:MarsBit这些加密货币研究工具如此优秀,它们能给你带来了超乎寻常的优势。@ReveloIntel-项目分解更多我见过的最深入的项目分解,但我最喜欢的部分是重要行业空间/播客的摘要。现在我可以直接得到摘要,而不是坐在那里听一小时的空间!站长网2023-05-25 03:07:280000入股、整合、价格战,量贩零食进入下半场
2023年,量贩零食成为最炙手可热的明星赛道之一。量贩零食行业发生多起融资,多起融资金额超过千万。一方面,量贩零食行业的行业竞争与整合加剧,赵一鸣零食与零食很忙合并,合并后门店总数突破6500家。行业规模位列量贩零食领域第一与第二的零食很忙集团与万辰集团的“商战”蔓延至社交平台,争夺加盟商,明面开战。站长网2024-02-18 15:52:230002全球大型网站正在阻止 OpenAI 等人工智能爬虫访问其内容
根据人工智能内容检测器Originality.AI的最新数据,全球前1000个网站中有近20%阻止爬虫机器人收集网络数据用于AI服务。在缺乏明确法律或监管规定管理AI使用版权材料的情况下,大小不一的网站都自行采取措施。站长网2023-09-03 09:13:190002