GPT-4o深夜炸场!AI实时视频通话丝滑如人类,Plus功能免费可用,奥特曼:《她》来了
不开玩笑,电影《她》真的来了。
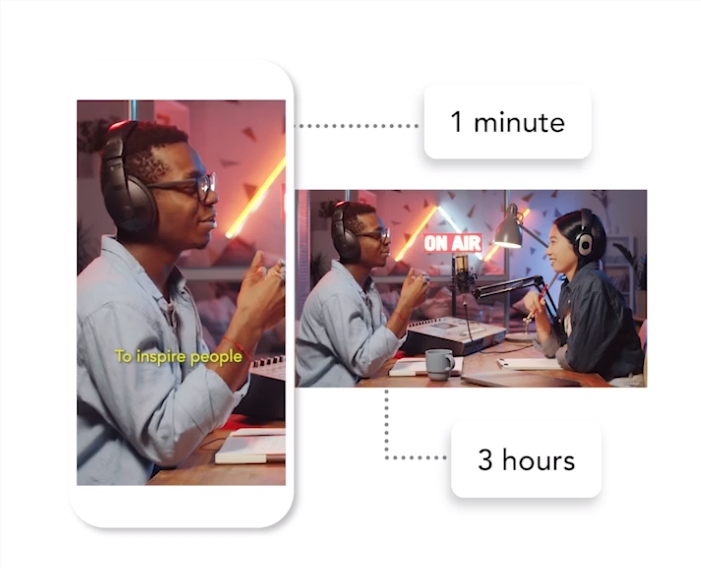
OpenAI最新旗舰大模型GPT-4o,不仅免费可用,能力更是横跨听、看、说,丝滑流畅毫无延迟,就像在打一个视频电话。
现场直播的效果更是炸裂:
它能感受到你的呼吸节奏,也能用比以前更丰富的语气实时回复,甚至可以做到随时打断。

GPT-4o里的“o”是Omni的缩写,也就是“全能”的意思,接受文本、音频和图像的任意组合作为输入,并生成文本、音频和图像输出。
它可以在短至232毫秒、平均320毫秒的时间内响应音频输入,与人类在对话中的反应速度一致。
这还是一份给所有人的大礼,GPT4-o与ChatGPT Plus会员版所有的能力,包括视觉、联网、记忆、执行代码、GPT Store……
将对所有用户免费开放!
(新语音模式几周内先对Plus用户开放)
在直播现场,CTO Murati穆姐说:这是把GPT-4级别的模型开放出去,其实她还谦虚了。
在场外,研究员William Fedus揭秘,GPT-4o就是之前在大模型竞技场搞A/B测试的模型之一,im-also-a-good-gpt2-chatbot。
无论从网友上手体验还是竞技场排位来看,都是高于GPT-4-Turbo级别的模型了,ELO分数一骑绝尘。
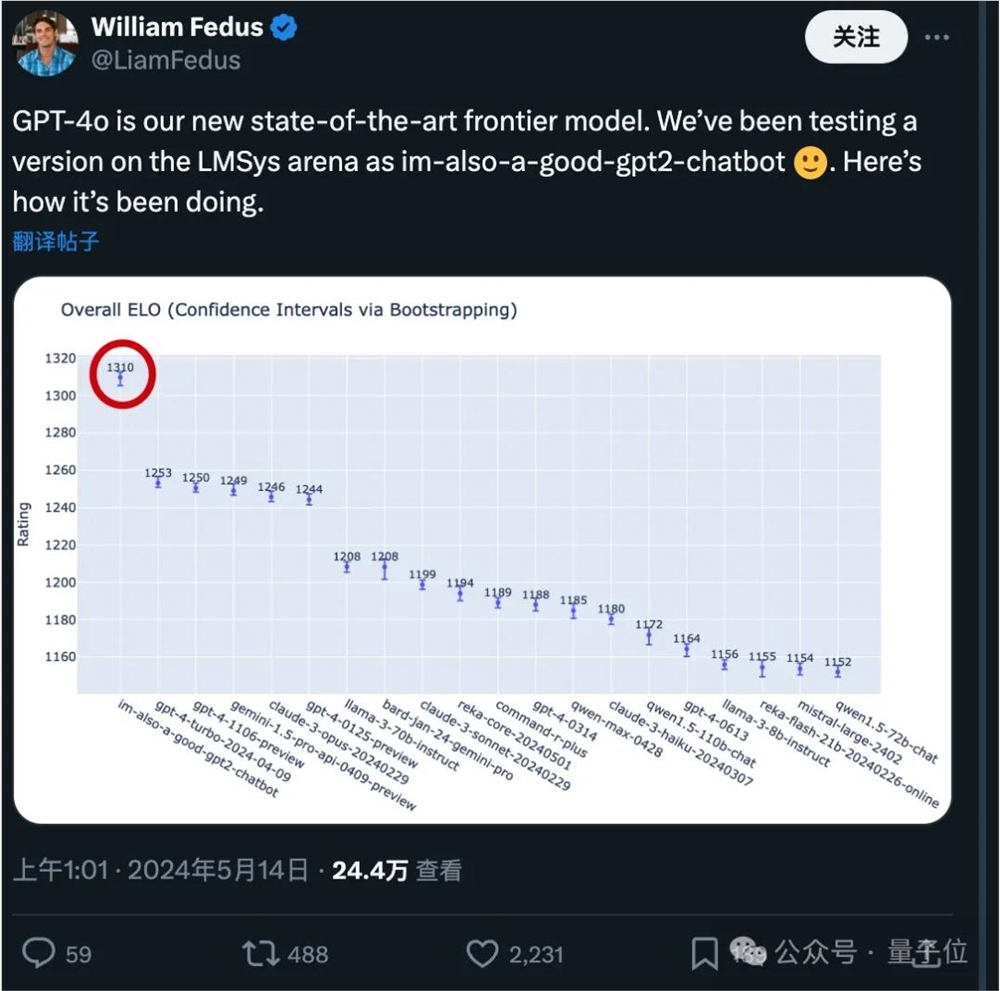
而这样的超强模型也将提供API,价格打5折,速度提高一倍,单位时间调用次数足足是原来的5倍!

追直播的网友已经在设想可能的应用,可以替代盲人看世界了。以及确实感觉比之前的语音模式体验上强上不少。
鉴于之前不少人就已经和ChatGPT语音模式“谈恋爱”了,有大胆想法的朋友,可以把你们的想法发在评论区了。
总裁Brockman在线演示
知道OpenAI发布会为什么定在谷歌I/O前一天了——打脸,狠狠打脸。
谷歌Gemini发布会需要靠剪辑视频和切换提示词达成的伪实时对话效果,OpenAI现场全都直播演示了。
比如让ChatGPT在语言不通的两个人之间充当翻译机,听到英语就翻译成意大利语,听到意大利语就翻译成英语。
发布会直播之外,总裁哥Brockman还发布了额外的5分钟详细演示。
而且是让两个ChatGPT互相对话,最后还唱起来了,戏剧感直接拉满。
这两个ChatGPT,一个是旧版APP,只知道对话,另一个则是新版网页,具备视觉等新能力。(我们不妨取Old和New的首字母,分别叫TA们小O和小N)

Brockman首先向小O介绍了大致情况,告诉她要和一个拥有视觉能力的AI对话,她表示很酷并欣然接受。
接着,Brockman让她稍作休息,并向小N也介绍情况,还顺带展示了小N的视觉能力。
只见打完招呼后,小N准确地说出了Brockman的衣着打扮和房间环境。而对于要和小O对话这件事,小N也感到很有趣。
接下来就是小O和小N相互对白的时间了,TA们依然是从Brockman的衣着开始聊起,小O不断提出新的问题,小N都一一解答。
接着,他们又谈论了房间的风格、布置和光线,甚至小N还意识到了Brockman正站在上帝视角凝视着TA们。
如果你看了这段视频就会发现,画面中出现了一个女人在Brockman身后做了些恶搞的手势。
这可不是乱入,是Brockman和女人串通好,专门给小N设计的一道“考题”。
就在小O和小N聊的正开心的时候,Brockman选择加入,直接问有没有看到什么不正常的地方。
结果是小N直接识破了Brockman的小伎俩,直接复述出了女人在他身后做小动作的场景,小O听了之后直接感叹原来在这里享受乐趣的不只有我们两个。
Brockman把这句话当成了夸赞,并对小O表示了感谢,还愉快地加入了TA们的对话。
之后是最后也是最精彩的部分,在Brockman的指挥下,小O和小N根据刚才聊天的内容,直接开启了对唱模式。
只过了简单几轮,衔接地就十分密切,而且旋律悠扬,音色也是和真人毫无二致。
最后视频以Brockman唱出的一句Thank you结束,在视频外的推文中他还透露新的语音对话功能将在数周内向Plus用户开放。
端到端训练,一个神经网络搞定语音文本图像
正如奥特曼在发布会前所说,GPT-4o让人感觉像魔法一样,那么它是如何做到的呢?
非常抱歉,这次非但没有论文,连技术报告也不发了,只在官网Blog里有一段简短的说明。
在GPT-4o之前,ChatGPT语音模式由三个独立模型组成,语音转文本→GPT3.5/GPT-4→文本转语音。
我们也可以让旧版ChatGPT语音模式自己讲一下具体是怎么个流程。
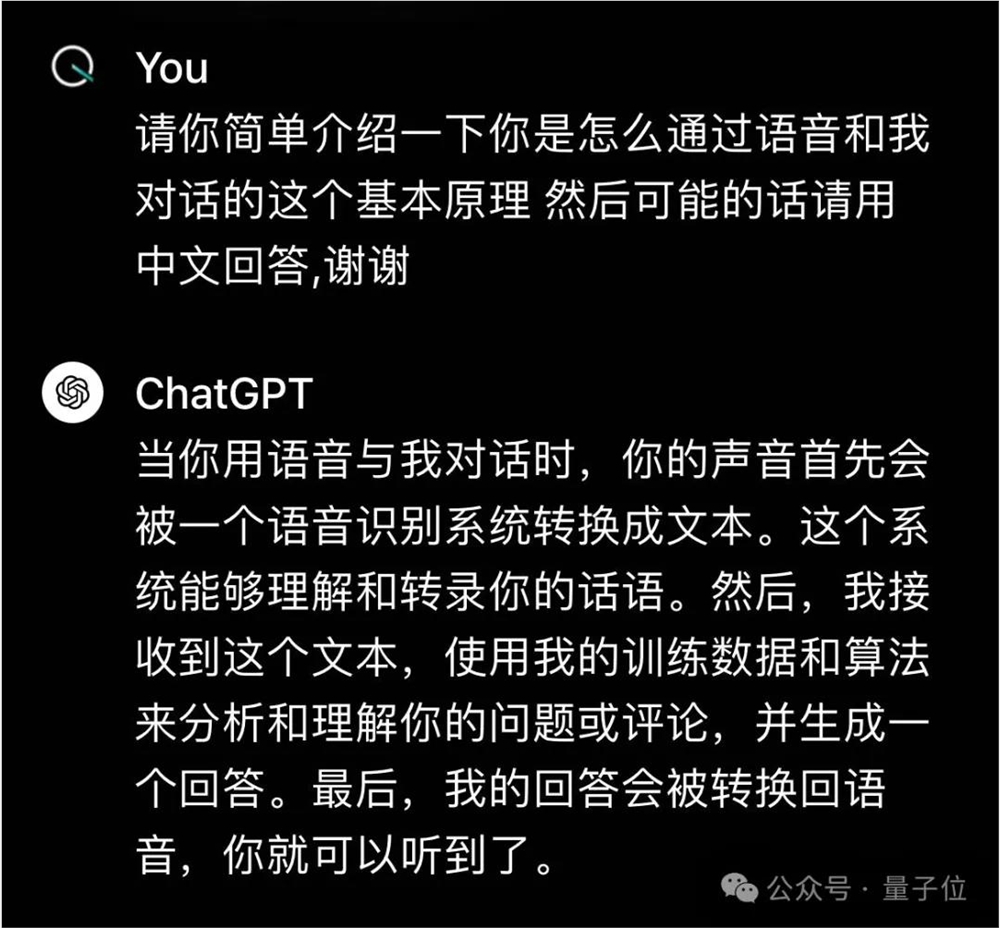
这样一来,整个系统的延迟足足有2.8秒(GPT-3.5)和5.4秒(GPT-4),而且丢失了大量的信息,它无法直接感受音调、多个说话者或背景噪音,也无法输出笑声、唱歌声,或表达情感。
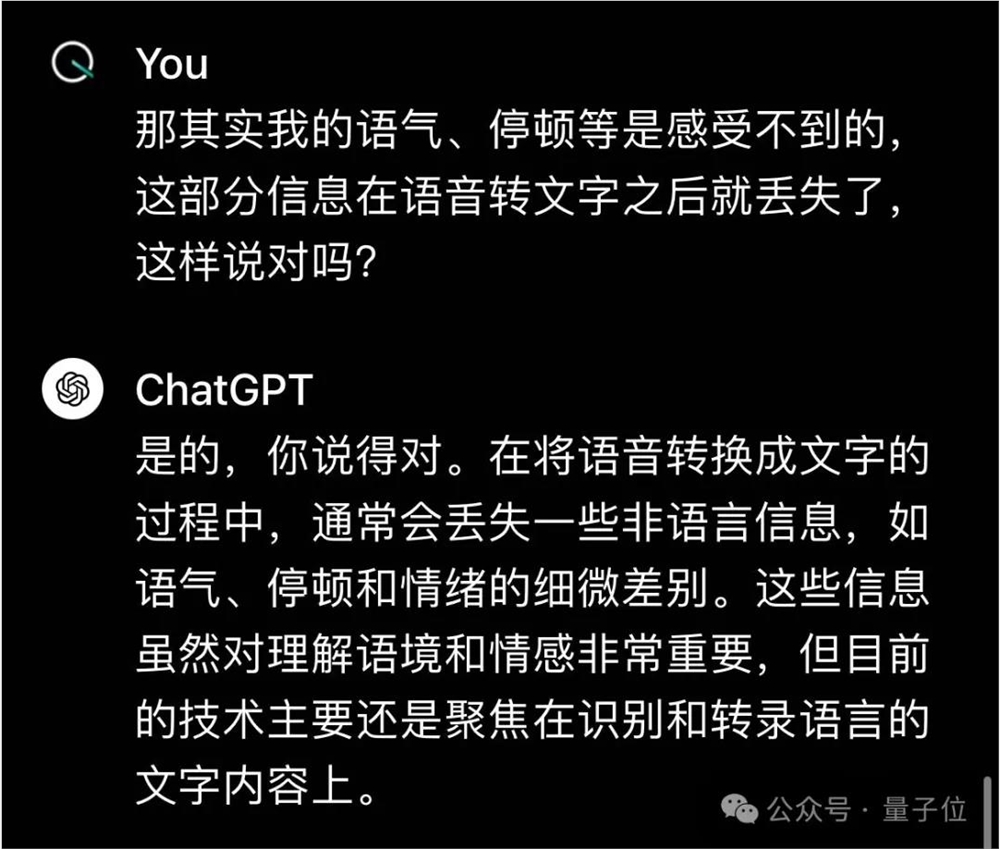
GPT-4o则是跨文本、视觉和音频端到端训练的新模型,这意味着所有输入和输出都由同一个神经网络处理。
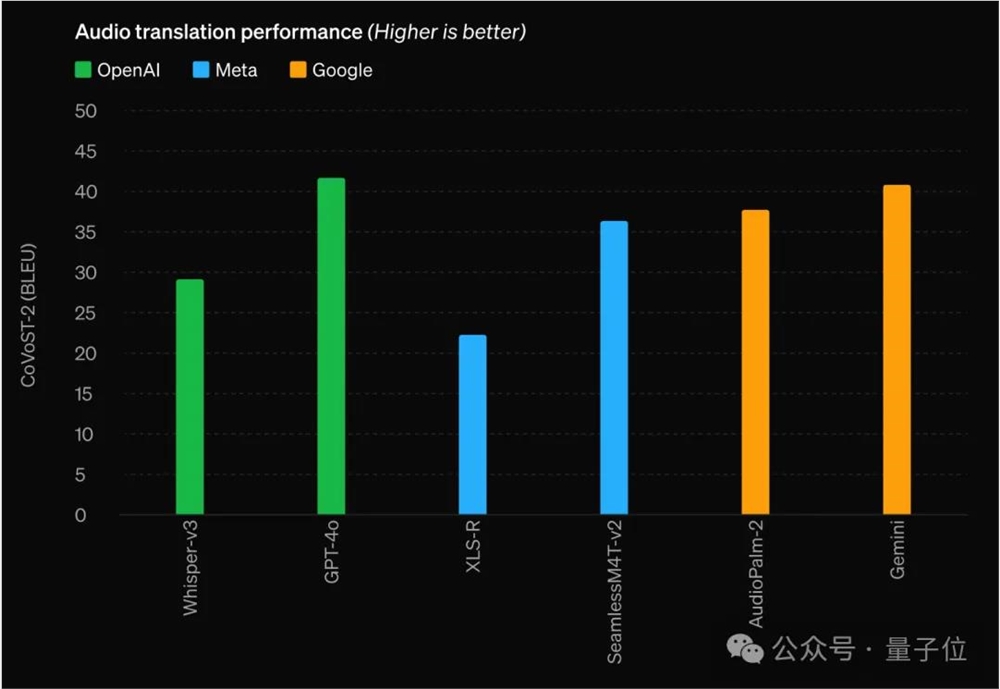
在语音翻译任务上,强于OpenAI专门的语音模型Whisper-V3以及谷歌和Meta的语音模型。
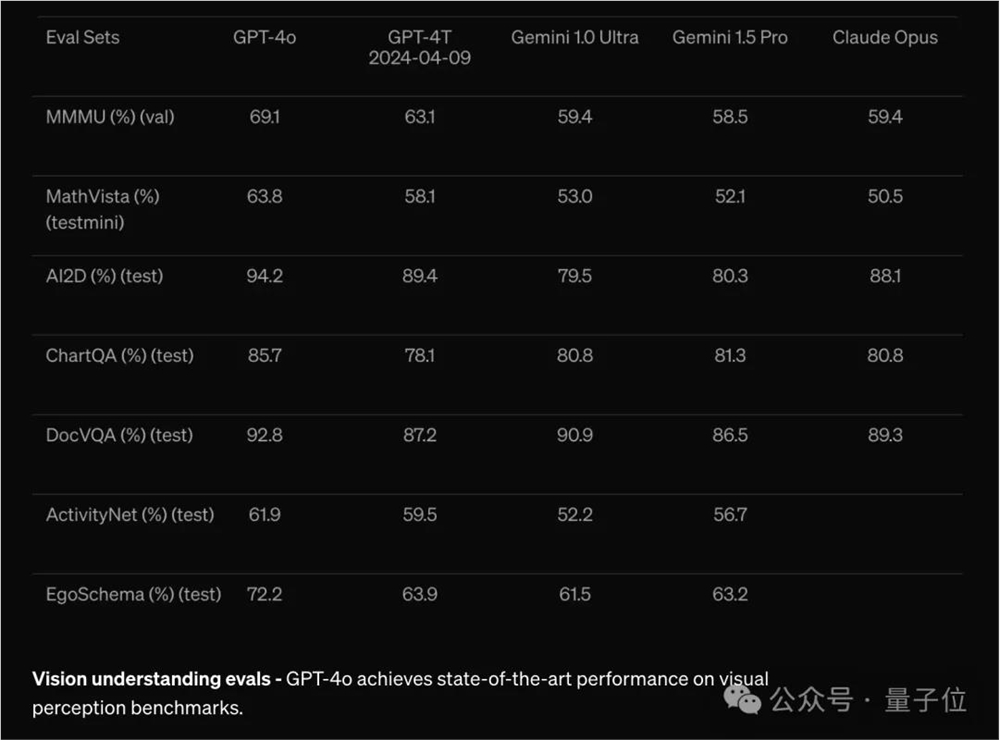
在视觉理解上,也再次反超Gemini1.0Ultra与对家Claude Opus
虽然技术方面这次透露的消息就这么多了,不过也有学者评价。
一个成功的演示相当于1000篇论文。

One More Thing
除了OpenAI带来的精彩内容之外,也别忘了北京时间5月15日凌晨,谷歌将召开I/O大会。
到时量子位将继续第一时间带来最新消息。
另外根据网友推测,GPT-4o这么强,全都免费开放了,这是劝大家不续订ChatGPT Plus了的意思吗?
那肯定不是啊~
鉴于OpenAI春节期间在谷歌发布Gemini1.5Pro后半小时左右用Sora狙击了一把,明天OpenAI还有新活也说不定呢?
直播回放
https://www.youtube.com/watch?v=DQacCB9tDaw
参考链接:
[1]https://openai.com/index/hello-gpt-4o/
AI视频编辑器Wisecut获100万美元投资 拥有35万用户
AI驱动的自动视频编辑平台Wisecut宣布获得了知名投资人TimDraper的100万美元投资。该公司计划利用这笔资金扩展团队、加强研发工作、推出更多功能,并扩大市场范围。Wisecut的目标是通过使用生成式人工智能简化视频编辑流程,帮助企业进行市场营销视频编辑,协助教育机构转型为在线课程,以及帮助视频内容创作者制作更吸引人、简洁的视频内容。站长网2023-08-02 11:00:270000OpenAI、微软押注,大模型应用的尽头是AI Agent ?|对话面壁智能
你见过Agent们“吵架”么?“这个产品需要具备XX需求,为什么没有?”,“你提出的需求完全不合理,技术上达不到!”,现场顿时乱作一团,越来越多的“员工”也被卷进了这场大乱斗中。激烈的争吵声越过了屏幕外,面壁智能的测试人员通过后台日志,发现Agents正在上演一场“职场大戏”。站长网2023-11-16 14:04:060005中国知网发布AI智能写作平台等“大模型+AIGC”产品
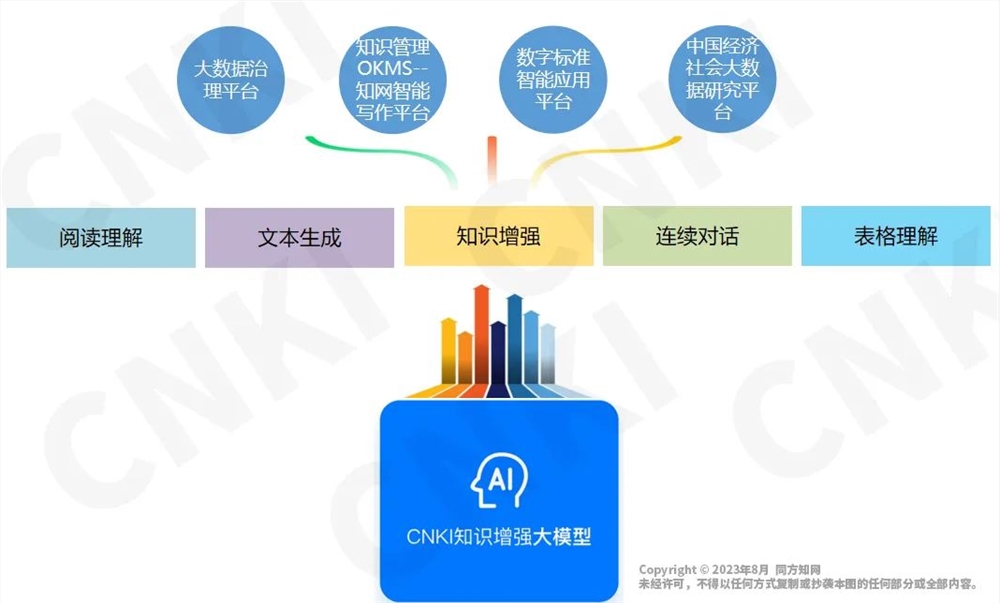
近日,中国知网正式发布基于“大模型AIGC”的大数据知识管理系列产品。此次知网发布的基于“大模型AIGC”的大数据知识管理系列产品包括大数据治理平台、数字标准智能应用平台、知网智能写作平台、中国经济社会大数据研究平台。站长网2023-08-24 23:31:460000抠脚大汉秒变可爱萝莉!实时换脸工具DeepFacelive让你在直播中一秒变脸
近日,一款名为DeepFaceLive的工具引起了广泛关注。这款工具可以在直播过程和视频通话时进行实时换脸,为用户提供了全新的视觉体验。DeepFaceLive是建立在DeepFaceLab的基础上的。DeepFaceLab是当前领先的面部交换框架,能够产生接近电影质量的面部合成效果,提供高保真的视觉体验。这一技术的引入,使得DeepFaceLive在实时换脸方面具有更高的准确性和真实性。站长网2024-04-26 12:13:010001元乘象ChatImg大模型完成千万元天使轮融资
近日,多模态大模型初创企业“智子引擎”宣布完成千万元天使轮融资,旗下拥有参数规模约150亿的大模型“元乘象ChatImg”,关注微信公众号“元乘象”即可体验。该模型的训练集主要包括图文对数据和视觉问答(VQA)数据,已经在图文匹配、图文检索、图像描述生成和文本描述生成等多个任务上进行了训练,表现出了出色的多模态处理能力。站长网2023-05-23 11:17:010000