AI作品会侵权吗?我花了一个月时间,调研了你想知道的一切。
在AI越来越被普及之后,有越来越多的创作者下场,开始使用AI,来创作自己的一些作品。
但是在这个时间点,很多的创作者,都非常关心一个问题:AI版权。
特别是最近的有两个月,在聊天中有密集想了解的,比如影视飓风,比如某国企,比如港中大等等。
大家的问题几乎都聚焦在两个问题上:
我用AI直接创作的内容,会有侵权的可能吗?
我用AI直接创作的内容,我拥有版权吗?
大家现在最忌惮的,就是第1点,我可能用AI出的内容,会侵别人的权。
毕竟现在典型的AI绘图工具比如Stable diffusion和Midjourney这么泛滥,但是你并不知道他们到底用了什么数据集来训练自己模型,这些模型数据到底有没有授权。
数据训练对于普通用户来说就是一个黑盒,特别是数据集这玩意儿,中间转手不知道多少层,真到终端用户调用并生成成品的时候,都盘包浆了...而且,也正因为有越来越多的AI内容被投入商用,我们更要看到技术与利益背后的风险。
前段时间有个典型是,4月23日,全国首例AI生成声音人格权侵权案在北京互联网法院一审开庭宣判,原告获赔25万。
原告殷某作为配音师,发现自己的声音被一款名为“魔音工坊”的APP以“魔小璇”出售。殷某随即以被告行为侵权为由,将“魔音工坊”的运营主体北京某智能公司等五被告起诉到北京互联网法院。
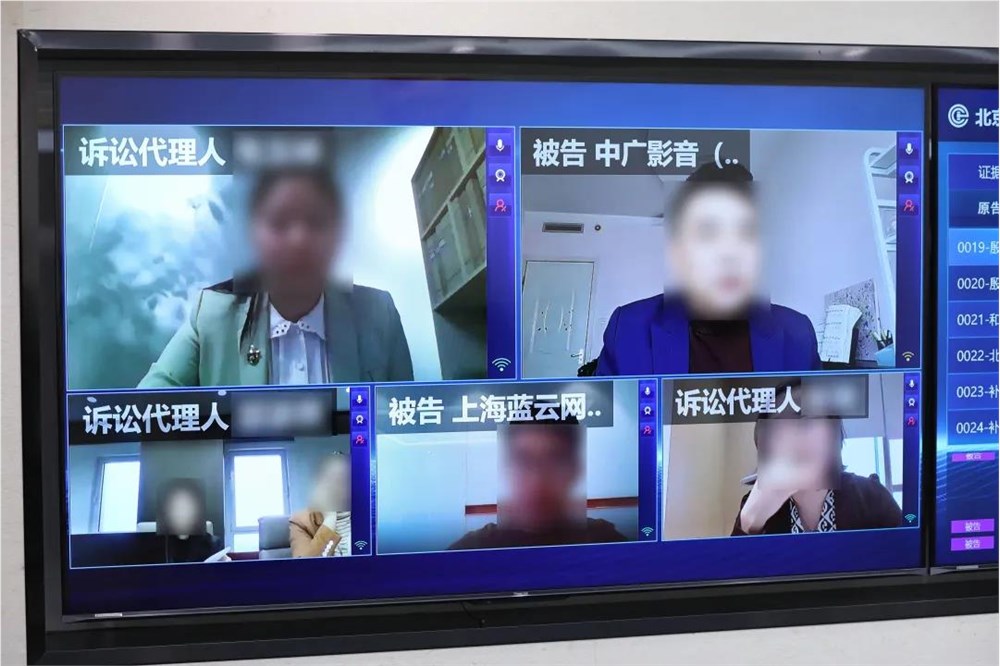
被告中广影音将原告为其录制的3本书的音频交给被告微软中国,被告微软中国又将原告的声音炼了AI声音模型,并向被告上海蓝云网络和被告北京信诺时代授权对外出售。然后北京信诺时代又跟小问智能签了采买合同,最终小问智能买了微软中国的殷某的AI声音模型,上架到“魔音工坊”上。
可以看到这期间倒了多少手。
虽然中广影音称自己有那3本书的音频的著作权,但不包括授权他人对原告殷某声音进行AI化使用的权利。所以虽然没有侵犯“著作权”,但是侵犯了原告殷某的人格权。
民法典第1023条规定,对自然人声音的保护参照适用肖像权的保护,明确将声音权益作为特殊的人格利益予以保护。即人格权。
所以最后判决是,中广影音和微软中国有明确的侵权行为,所以这两要赔25万。而另外三就是买卖关系,主观上不存在过错,不承担损害赔偿责任,道个歉就行。
你看,对于公司主体来说,这个链路非常清晰,但是我更关心的是另一点:
“魔音工坊” 有几百几千万用户,一定有无数人用了"魔小璇"的AI声音去做各种各样的AI作品,那这些人侵权了吗?
这个答案其实非常明确:
不侵权。
因为整个案子,原告殷某告的都是侵犯人格权,而并不是著作权。
微软中国是用原告殷某为中广影音录制的3本书的音频去炼的模型,这3本书音频的著作权是在中广影音手上的,所以并不构成侵权著作权。构成的一直都是侵犯人格权。这两公司是明知不可为而为之。
而“魔音工坊”的用户们,并不知道这声音是殷某的,也并没有用殷某这个主体来进行宣传,所以其实并没有侵犯人格权。
而之前的AI孙燕姿的例子,你不仅炼了AI孙燕姿的声音,还明确的用AI孙燕姿来进行宣传,甚至开直播要打赏,这就是侵犯了孙燕姿的人格权。而只是单纯的声音相似,其实不构成人格权的侵权。除非你故意的混淆声音的主体。
所以可以从这个例子中看到,人格权和著作权,都有可能侵权,但是却是完全不一样的维度。
那到底什么情况我们有版权?什么情况下我们会侵权?怎么避免侵权?
所以为了搞懂这些问题,也为了让自己更有一根弦,我花了将近一个月的时间,去看了大量的过往的资料和案例,也咨询了很多律师朋友,这里特别感谢竞天公诚律所的超级大佬,数据合规组的合伙人周杨周律师(去年上了Legal Band的知名合伙人),不厌其烦的给我这个法律小白,解答了N多相关的问题,也让我对AI版权有了自己心中的答案。
所以我想用这一篇文章,把我现在的调研结果写出来,也希望能给N多的创作者一个答案。
当然,我是法律外行,这些更多的是我调研与咨询的结果,如果有不对的地方,希望大佬们多多指正!感恩。
那,让我们进入正文吧。
1.我用AI直接创作的内容,会有侵权的可能吗?
首先大家最关注的问题:
我用AI生成的内容是否会侵权?
而现在这里的"权",则更多的是聊著作权,也就是版权。
先回答这个问题。
AI生成的内容,会不会侵权?明确的说:会。
这个需要一点点来聊。
首先,在我们国家,在聊AI侵权方时,一般分为三个主体,这三个主体是根据《互联网信息服务深度合成管理规定》《生成式人工智能服务管理暂行办法》(“《AIGC 暂行办法》”)中的角色中进行划分的。
分为服务技术支持者(模型开发者)、服务提供者(运营者)、服务使用者(用户)。
其中服务技术支持者和服务提供者是不一样的,在进行算法备案的时候,基础模型备案的是模型开发者,而基于模型之上所构建的服务,则是运营者。
也可以简单的理解为,开发模型的,和开发产品的。这两者一般是区分开的。
所以基本构成三方之势:模型开发者、产品运营者、用户。
首先我们要明确的是,在国内,AI产出的内容,可以被认定为“作品”,可参考北京互联网法院在(2023)京0491民初11279号案件(AI绘图侵权第一案)中的判决(这个放在第二部分细聊)。
所以一旦可以成为“作品”,那么也就有了著作权的概念。著作权制度的立法初衷之一就是保护自然人的利益。AI算法模型仅仅是人类的附属物,不具有独立的法律人格。所以AI生成的内容版权,必须归于自然人。
而这个自然人是谁,就需要先看看AI工具自身的软件许可协议了。
比如说,这是OpenAI的条款。

简单的说,就是OpenAI定义了一个“输入”和“输出”,输入就是你发给模型的,输出就是模型生成的。
OpenAI的意思就是:输出的所有权归你所有,OpenAI将其在输出中可能拥有的所有权利、所有权和利益转让给你。
也就是说,所有的权利都归你,当然,出了事发生了侵权也是你的事。跟OpenAI无关。
再看一下Midjourney的。
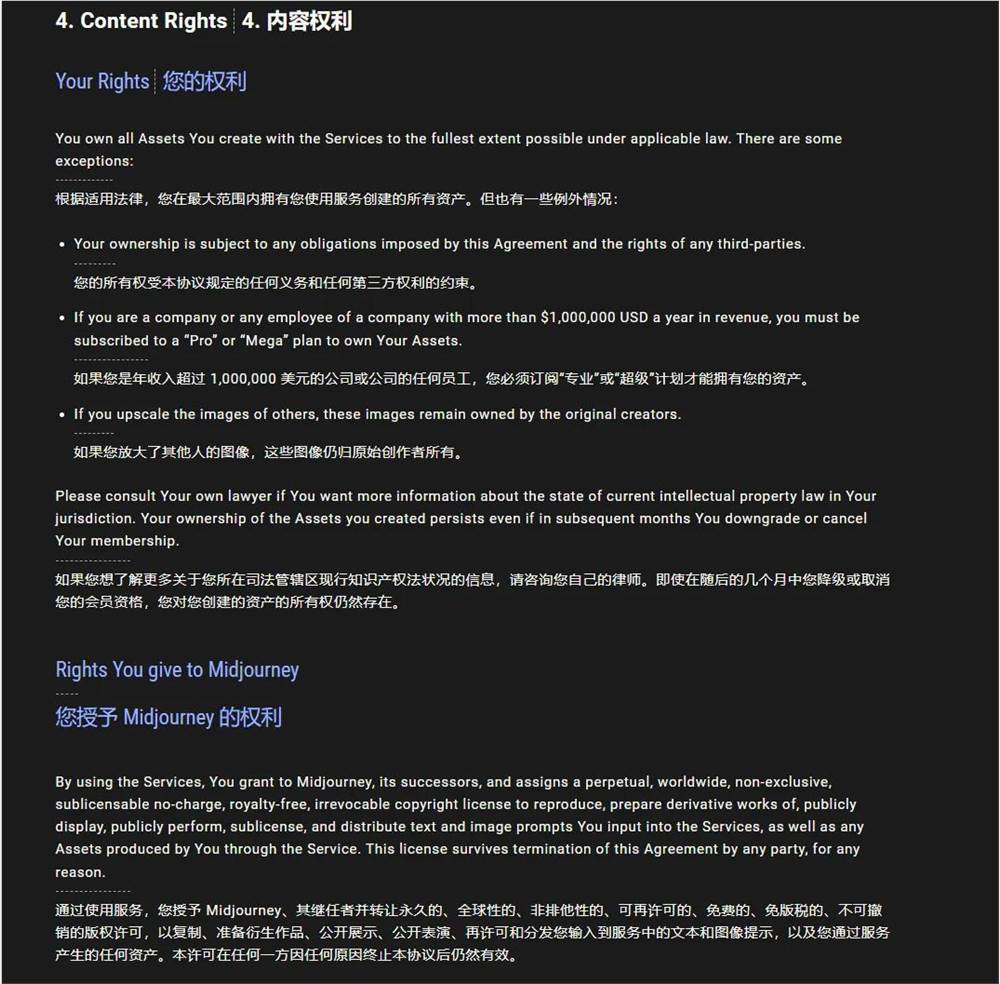
Midjourney就比较狗一点,大多数情况下,你都有用Midjourney生成的图片的所有权,除非你是年收入超过100w美元的公司的员工,那你必须开通“pro”或者“Mega”计划才拥有这些图片的所有权。
同时,你在有这些图片的所有权的同时,你会永久的、全球的、非独家的、可转授权的、免费的、不可撤销的版权许可,以复制、准备衍生作品、公开展示、公开表演、转授权和分发你输入到服务中的文本和图像提示,以及通过服务产生的任何资产。这个许可在本协议由任何一方终止后仍然有效。
非常的狗。你虽然有你的图片所有权,但是你也无条件的授权给了Midjourney,他可以用你的图去做几乎任何事情。
而像Runway这种,就更强盗一些,有兴趣的可以都去看看。
但是大部分的AIGC平台,都比较整齐划一,把所有权给到用户。版权给你,侵权了也是你自己的事。
但这并不意味着 AIGC 平台在此场景下绝对免责。在权利人知晓侵权内容是来自AIGC 平台的情况下,权利人完全有可能主张AIGC平台与用户构成共同侵权,并要求 AIGC平台与用户承担连带赔偿责任。
更多的是根据用户和 AIGC 平台对于被控侵权元素的贡献程度,来判断两者内部如何分摊侵权责任。
甚至在某些时候,权利方直接会来告AIGC平台。
目前在国内,最典型的就是广州互联网法院判的(2024)粤0192民初113号案件(AI奥特曼侵权案)。

原告是奥特曼中国区的版权代理商,被告是经营着某AI网站(化名Tab)的公司,Tab网站提供具有AI对话及AI生成绘画功能的服务。原告指控被告在其运营的网站上,通过AI生成了与其奥特曼形象实质性相似的图片。
如用户输入“生成一个奥特曼”,即生成奥特曼形象图片;
输入“奥特曼融合美少女战士”,即生成奥特曼身体拼接美少女战士长发形象的图片等。而且该网站生成的奥特曼形象与原告奥特曼形象构成实质性相似。
知识产权法里边有一个特别古老的原则,就是大家的常识,就如果你按照你的常识就能够判断你生成的这个图片,它明显的就是一个侵权图片,那就构成侵权。除非你能证明除Tab网站的AI公司里没有人了解奥特曼形象,也从未接触过奥特曼形象。
虽然Tab只是一个接别人绘图API的网站,但是根据《AIGC 暂行办法》第二十二条第二款规定:“生成式人工智能服务提供者,是指利用生成式人工智能技术提供生成式人工智能服务(包括通过提供可编程接口等方式提供生成式人工智能服务)的组织、个人。”Tab网站被认定为服务提供者(运营者),构成实质性侵权。
最后判决是原告胜诉。支持了原告索赔(不过从30w砍到了1w)以及在停止生成奥特曼形象的请求。但没支持原告请求删除模型训练侵权数据的要求。
原因是该案的被告只是AIGC服务提供者而不是服务技术支持者(模型开发者),大模型是由第三方公司提供的,原告也没有追加第三方公司为共同被告。
不过在我国根据《AIGC暂行办法》第七条规定,你如果想通过算法备案,就必须使用具有合法来源的数据和基础模型,如果涉及知识产权的,则不得侵害他人依法享有的知识产权。
换句话说,在想拿到算法备案时,只有你的数据本身是没有侵权的,才能通过算法备案。
所以对于普通用户是否侵权其实已经很清晰了,版权是一条非常完整的,且不可中断的链条。不管素材是在模型端,还是在数据传输的中间,只要出现了版权问题,就会一直延续下去,不会因为面临二次加工、或者因为基数庞大的用户群,就让已经出现的侵权风险消失。
所以回到那个问题:
我用AI直接创作的内容,会有侵权的可能吗?
明确的说:会。
能给的建议也不多,最基本的就是:尽量回避与知名艺术家或知名作品相关的提示词。如果必须模仿知名者的风格或者相关作品时,应特别重视生成品是否构成“实质性相似”。
2. 我用AI直接创作的内容,我拥有版权吗?
在我国,目前讨论AI版权,主要通过分析人类(作品作者,或者已经拿到版权许可)在AI生成中的过程性行为(人类做了啥)来判断作品(法律范围内认定为“作品”)是否属于能够得到版权保护的独创性智力成果(具有独创性,且表达智力成果)。
这块可以参考北京互联网法院在(2023)京0491民初11279号案件(AI绘图侵权第一案)中的过程与判决。
2023年8月,原告李某向法院起诉称,2023年2月24日,他使用开源软件Stable Diffusion通过输入提示词的方式生成了涉案图片,并将该图片发布在小红书平台上。
后原告发现,被告刘某在百家号一篇文章的配图中使用了涉案图片。被告不仅未获得自己的许可,还截去了署名水印,使得相关用户误认为被告为该作品的作者,严重侵犯了自己享有的署名权及信息网络传播权。故请求法院判令被告在百家号公开赔礼道歉、消除影响,赔偿经济损失5000元。
在公开庭审时候,法院要求原告当庭展示创作过程,并说明其中哪些有独创性:
然后原告当庭下载了SD,打开B站去一个视频下面下了一个SD大模型和LoRA,然后调了提示词,改了参数。
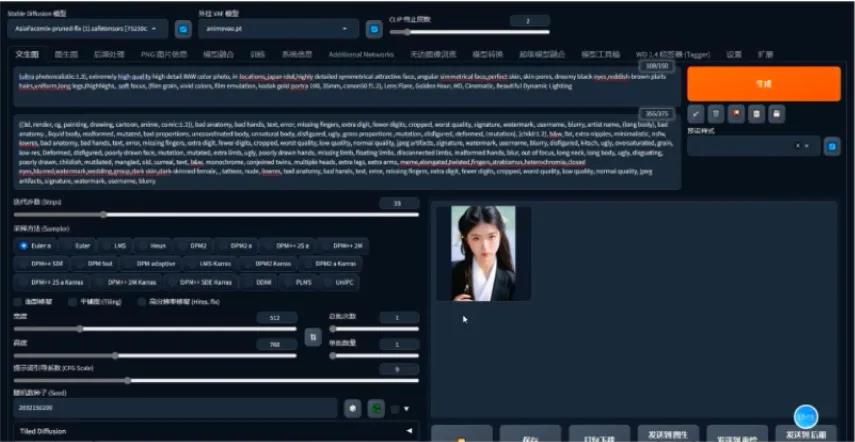
法院认为,你模型选取是不算体现作者的独创性的,但是对提示词、参数的选择可以体现其“进行了一定的智力投入”,从最开始的图片构思起,到设计人物的呈现方式、选择提示词、安排提示词的顺序、设置相关的参数、选定哪个图片符合预期等等,都体现了原告的智力投入。
法院对作品的原话是:“人们利用人工智能模型生成图片时......本质上仍然是人利用工具进行创作, 即整个创作过程中进行智力投入的是人而非人工智能模型。鼓励创作,被公认为著作权制度的核心目的......人工智能生成图片,只要能体现出人的独创性智力投入,就应当被认定为作品,受到著作权法保护。”
最后判决原告胜诉,被告需要赔礼道歉,并赔偿500元。
金额是否合理不谈,但是整体看下来,观点非常清晰:
1. AI模型是工具。
2. 涉案图片虽然有AI生成,但使用者给予了人工干预,至于说AI生成的内容是否构成作品,要基于个案具体情况对“人工干预”的内容、作用进行审查。
3. 原告的举证和留痕,可以证明其对涉案图片的形成进行智力投入且满足独创性要件,可以作为作品给予版权保护。
所以根据AI绘图侵权第一案,我们是可以认为,AI生成的内容,是可以成为“作品”的,同时AI算法模型仅仅是人类的附属物,不具有独立的法律人格。所以AI生成的内容版权,必须归于自然人。
也就是说,一旦AI生成的内容被认定为“作品”,创作者就拥有AI生成内容的版权。
其实除了这个AI绘图第一案,在2019年12月24日深圳市南山区人民法院民事发布的判决书(2019)粤0305民初14010号(简称Dreamwriter案)里,同样认定AI生成的文章构成作品。
这个比AI绘图第一案还要早几年,是真正的全国首例认定AI生成的文章构成“作品”。
大概就是腾讯使用一个叫Dreamwriter的AI写作的软件,生成了一篇A股收评文章,然后被盈讯科技一字未动的搬到了自己的网站上。
而同样想判定盈讯科技有没有侵权,首先得判定腾讯的人使用Dreamwriter生成的东西是不是“作品”,是否具有独创性。
而法院在详细审查后,认为涉案文章满足独创性要求,属于我国著作权法所保护的文字作品。
所以判定也很简单,AI只是工具,是否是“作品”,你是否有版权,得看其是否具备“独创性”要件,属于“智力成果”。而怎么判断智力成果,简单且草率的总结,就是两点:
第一个,肯定是作品得有整体性(以及,可能期待传递内容)。
我用3000条prompt生成了1个视频,和用1条prompt生成了随便1幅图,肯定前者能够受保护。
我只做几个音符,和我写整首歌,肯定是后者得到保护。
当然,上述还是需要具体情况具体分析,但是过于简单,或者完全不成体系,可能不能被视作“作品”。
第二个,具备“独创性”和“智力创作”。
这个要具体看情况认定,但是肯定不能直接ctrl c v。
但是有一点,现在大家都用prompt,但是万一同一个咒语产生的效果过于雷同,咋整?
在使用prompt生成作品,在一定程度上可以看做创作过程,独创性和智力创作可以在这里得到体现,故而生成的作品也可以得到相应保护。
同一个AI,同一条指令,生成的不一定是同一个作品,更何况一千条指令一千个哈姆AI。当然,相似程度与版权关系需要具体问题具体分析。这个目前还没有具体的案例。
也给大家一点关于“作品”在制作过程中的存证方法。
首先当然是过程中留档、截图,比如设计师在设计过程中,存过程草稿就是一种非常常见的做法。
在做完之后,你可以选择在作品上进行署名,法律规定,在作品上署名的,即为作者,有相反证明的除外。
当然你也可以通过邮箱或第三方存储平台进行存证,第三方储存平台包括通过朋友圈、微博、微信公众号或其他线上平台发布分享内容,通过上传的主体,内容和时间,证明获得著作权的时间和权属。注意,账号一定要实名,或者用自己的手机号登录。
当然还有更厉害的,比如你的重要作品,想保护知识产权,你直接打印出来,用邮政寄给自己,然后收着,别拆,中国邮政的邮戳就是你的知识产权生效日期。
希望大家,都能保护好自己的知识产权吧。
写在最后
综上,谁使用,谁拥有,谁负责。不论是不是在AI视野下,版权保护都是一个双向的过程:在保护自己的作品同时,也需要提高自己的内容辨认意识与版权意识。
最后,我想用AI绘图第一案和AI奥特曼侵权案里,北京互联网法院和广州互联网法院两份判决书中的原话做结尾。
在AI绘图第一案中,判决书中写道:
“当前,新一代生成式人工智能技术正在被越来越多的人用来进行创作,Stable Diffusion模型和与之类似功能的模型,可以根据文字描述生成精美图片......使创作图片的效率大幅提高。应当讲,生成式人工智能技术让人们的创作方式发生了变化,这与历史上很多次技术进步带来的影响一样,技术的发展过程,就是把人的工作逐渐外包给机器的过程......而现阶段,生成式人工智能模型不具备自由意志,不是法律上的主体因此,人们利用人工智能模型生成图片时,不存在两个主体之间确定谁为创作者的问题,本质上,仍然是人利用工具进行创作:即整个创作过程中进行智力投入的是人而非人工智能模型。鼓励创作,被公认为著作权制度的核心目的。只有正确地适用著作权制度,以妥当的法律手段,鼓励更多的人用最新的工具去创作,才能更有利于作品的创作和人工智能技术的发展。在这种背景和技术现实下,人工智能生成图片,只要能体现出人的独创性智力投入,就应当被认定为作品,受到著作权法保护。”
而在AI奥特曼侵权案中,判决书中写道:
“本院需要强调的是,人工智能是引领未来的战略性技术,是新一轮科技革命和产业变革的核心驱动力,被认为是发展新质生产力的主要阵地。我国人工智能技术快速发展、数据和算力资源日益丰富、应用场景不断拓展,为开展人工智能场景创新奠定了坚实基础。考虑到生成式人工智能产业正处于发展的初期,需要同时兼顾权利保障和产业发展,不宜过度加重服务提供者的义务。在技术的飞速发展过程中,服务提供者应当主动积极履行合理的、可负担的注意义务,从而为促进形成安全与发展相济、平衡与包容相成、创新与保护相容的中国式人工智能治理体系提供助益。”
不仅仅是版权保护,我也期待着未来能够有更完善、全面、灵活的措施能够在推动技术进步的同时保护创作者的合法权益。
更能在服务技术支持者(模型开发者)、服务提供者(运营者)、服务使用者(用户)三者之间找到平衡。
当然, 本文仅仅是从最浅层的AI版权保护角度写出自己的一些想法和调研结果,仅供参考。
很希望大家的智慧成果都能够在被尊重的同时得到保护。
未来能够更加安全快乐的激情创作。
AI一定是未来,我坚信。
豪掷290亿元!马斯克:特斯拉今年要买大量NVIDIA芯片
快科技6月5日消息,特斯拉CEO埃隆马斯克近日透露,特斯拉计划在今年投入高达40亿美元(约合人民币290亿元)用于采购NVIDIA芯片。马斯克在社交媒体上表示,特斯拉今年的人工智能相关支出大约为100亿美元,其中约一半将用于内部研发,包括特斯拉自行设计的AI推理计算机和传感器,以及Dojo超级计算机集群的建设。他进一步解释说,构建AI训练超级集群的成本中,NVIDIA硬件占据了大约三分之二。0000商务部:1-9月全国直播电商销售额达1.98万亿元,增长60.6%
划重点:1.🌐网络零售带动消费增长:1-9月全国网上零售额达10.8万亿元,增长11.6%,网络零售对社会消费贡献率达33.9%。2.💻直播电商蓬勃发展:全国直播电商销售额达1.98万亿元,增长60.6%,带动网络零售增速7.7%。3.🌾数实融合助力产业升级:推动农业全链条数字化转型,全国农村网络零售额增长12.2%,产业深度融合促进特色数字化产业带形成。站长网2023-10-20 16:17:270000网易有道上线「易魔声」开源语音合成引擎 包含2000多种不同音色
今天,网易有道宣布上线了一项开源技术,名为「易魔声」开源语音合成引擎。这款引擎支持中英文双语,包含2000多种不同的音色,具备特色的情感合成功能,可以合成包含快乐、兴奋、悲伤、愤怒等广泛情感的语音。用户可以在GitHub上免费下载使用,并通过提供的web界面和批量生成结果的脚本接口实现音色的情感合成与应用。站长网2023-11-10 14:11:260001亚马逊模仿TEMU商业模式推出新低成本店面
电子商务巨头亚马逊正准备推出一个新低成本店面,模仿TEMU的商业模式。据报道,亚马逊给商家发来的信息显示,该公司的限价包括珠宝8美元、吉他13美元和沙发20美元。消息中列出了700件商品。亚马逊计划直接从中国广东的一个工厂向美国客户发货,并补充称,对于通过新店面销售的商品,亚马逊向卖家收取较低的配送费用。0000文生视频大模型,短视频的过弯点?
随着今年初Sora的横空出世,这个可以创建长达一分钟视频的文生视频模型就成为了国内厂商追逐的焦点。6月初,快手自研的视频生成大模型“可灵”正式上线。可灵AI采用了与Sora相似的技术路线,能够生成具有合理运动和模拟物理世界特性的视频。截至目前,已有超百万人排队申请内测资格,其中超30万人已获得试用资格,累计生成超700万条短视频。近日,可灵AI终于宣布全面开放内测,同时上线付费会员体系。站长网2024-07-30 08:59:480000










