Meta 的开源语音 AI 项目 MMS 可识别 4000 多种口头语言
Meta 公司的人工智能研究团队今天宣布开源一个名为「Massively Multilingual Speech(大规模多语言语音)」的新项目,旨在解决创建准确可靠的语音识别模型的挑战。
图片来自Meta
能够识别人类语音并清晰回应的 AI 模型具有巨大的潜力,特别是对于完全依赖语音访问获取信息的人来说。然而,训练高质量的模型通常需要大量的数据,包括数千小时的音频和对话内容的转录。对于许多语言,特别是那些较为冷门的语言,这样的数据根本不存在。
Meta 的 MMS 项目通过将一种名为 wav2vec 2.0 的自监督学习算法与一个提供了超过 1,100 种语言标记数据和近 4,000 种语言无标记数据的新数据集相结合,克服了数据不足的问题。
为了解决某些语言数据缺乏的问题,Meta 的研究人员利用《圣经》这本在很多语言中已经被翻译的书籍。其翻译通常被用于基于文本的语言翻译研究,并且许多语言而且,还有人们朗读这些文本的公开可用的音频录音。
「作为这个项目的一部分,我们创建了一个包含 1,100 多种语言新约圣经的数据集,平均每种语言提供了 32 小时的数据量,」Meta 的研究人员说道。
当然,32 小时的数据量不足以训练传统的有监督语音识别模型,这就是为什么使用 wav2vec 2.0 的原因。Wav2vec 2.0 是一种自监督学习算法,使机器能够在不依赖于标记训练数据的情况下学习。
借助这种算法,可以用更少的数据训练语音识别模型。MMS 项目在 1,400 多种语言中的约 500,000 小时的语音数据上训练了多个自监督模型,然后对生成的模型进行了特定的语音任务微调,如多语言语音识别或语言识别。
Meta 表示,生成的模型在 FLEURS 等标准评估以及与其他语音识别模型的比较中表现良好。
「我们使用了一个包含 1B 参数的 wav2vec 2.0 模型在 1,100 多种语言上训练了多语言语音识别模型,」Meta 的研究人员解释道,「随着语言数量的增加,性能确实会下降,但幅度很小,:从 61 种语言增加到 1,107 种语言,字符错误率仅增加约 0.4%,但语言覆盖范围增加了 17 倍以上。」
在与 OpenAI LP 的 Whisper 语音识别模型进行直接比较时,Meta 的研究人员发现,使用 MMS 数据训练的模型的单词错误率大约是其一半。「这表明我们的模型在与目前最佳的语音模型相比时表现非常出色,」研究人员表示。
Meta 表示,现在他们正在分享 MMS 数据集和用于改进和训练模型的工具,以便 AI 研究界的其他人能够在此基础上进行进一步的工作。MMS 项目的目标包括扩大其覆盖范围以支持更多的语言,并改善对方言的处理,这是现有语音技术所面临的主要挑战。
「我们的目标是让人们更容易以自己偏好的语言获取信息和使用设备,」研究人员说道,「我们还设想未来的情景是,一个单一模型能够解决所有语言的多种语音任务。虽然我们训练了独立的语音识别、语音合成和语言识别模型,但我们相信将来一个单一模型将能够完成所有这些任务,带来更好的整体性能。」
中国一汽联合阿里云通义千问打造大模型应用GPT-BI
中国一汽联合阿里云通义千问推出了大模型应用GPT-BI,用于数智化转型。该应用能够接收自然语言查询,并结合企业数据生成分析图表,准确率可达90%。与传统的BI系统相比,GPT-BI能够实现灵活的问答组合和数据穿透,实现“问答即洞察”的功能。站长网2024-01-23 09:29:530000微信公众号悄悄上线AI音色克隆,微信的一小步,却是AI的一大步。
这篇文章,可能是我有史以来最特殊的一篇文章。因为当你点开右上角的三个点,点击听全文的时候。可能你会发现,你听到的不再是那个永远跟其他人一样,相同的男声。而是,AI克隆的我的声音。此时,微信可能会用我的声音,来为你朗读出这篇文章。之所以,我一直在说可能,是因为我虽然在后台设置好了,但是只有这篇新发的文章,我才能知道,我的声音到底有没有生效。0001如果避免原图遭AI滥用?使用 AI 防止 AI 图像操纵
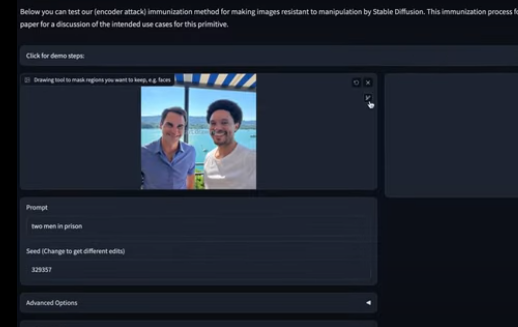
麻省理工学院的研究人员开发了一种名为PhotoGuard的技术,用于对抗未经授权的图像操纵,保护图像的真实性。PhotoGuard通过引入微小的、不可见的像素变化来破坏人工智能模型对图像进行操纵的能力。它使用了两种不同的攻击方法:编码器攻击和扩散攻击。编码器攻击对模型中图像的潜在表示进行微调,使模型将图像视为随机实体,从而阻止对图像的操纵。站长网2023-07-31 14:39:220000网易游戏上线未成年人模式 首批34款试点产品已完成部署
站长之家(ChinaZ.com)1月3日消息:网易游戏今日发布公告,为了积极响应和落实《未成年人网络保护条例》,网易游戏全线产品将增设“未成年人模式”。该模式在防沉迷系统的基础上,提供了更为全面的保护措施。目前,首批34款试点产品已完成“未成年人模式”的部署,为用户提供一键内容屏蔽、“网易家长关爱平台”管理、防网络欺凌三大防护功能选项。站长网2024-01-03 11:07:140000网购超长预售期引发吐槽 买家:衣服到货就过季了
11月22日消息,微博话题网购超长预售期引发吐槽”引发热议。据国内多家媒体报道,在电商平台上,设置7天、15天甚至30天预售期的女装店比比皆是。一位买家表示,冬天买的羽绒服春天才收到,已经过季了。还有买家说,适度预售等待可以理解,但如果等待过长就很难接受,如果质量、尺寸不合适,最终还得退货,白折腾一场。0002