6·18前淘宝店铺迎来大改版,所有商家都可以“抢”的流量
这一次的改版,可能给了所有商家站在同一起跑线的机会。
针对所有店铺的新机
细心的人已经发现,在商家店铺里出现了“作品”一栏,里面的两个子菜单收录了店铺商品的笔记、买家秀和卖家秀。
这些短视频会出现在淘宝的“猜你喜欢”中,消费者观看后,点击发布者头像,会直接跳转到店铺的“作品”板块,即内容首页。
如果仅从用户在搜索和浏览上的习惯看,这个改动很聪明。
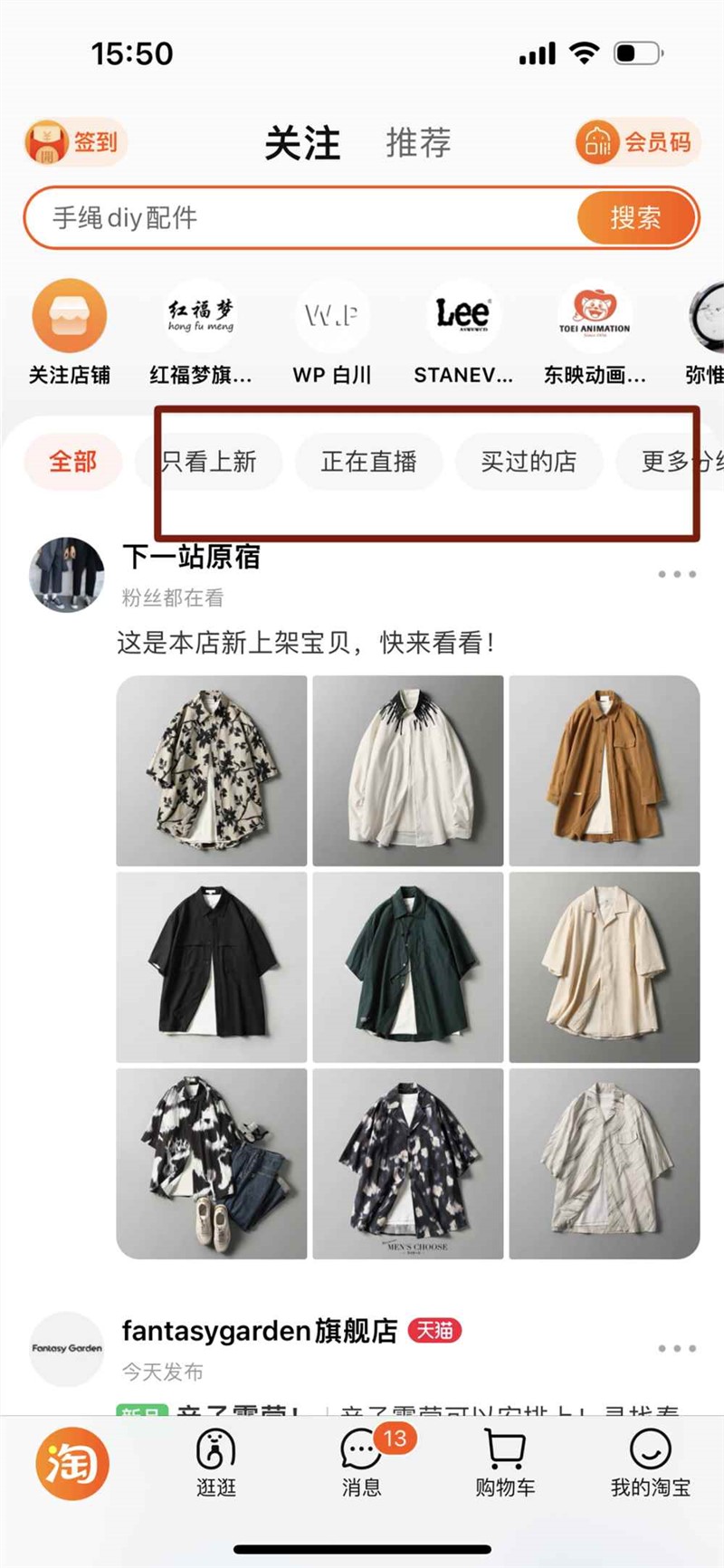
从用户搜索商品的习惯看,用户先看到商品,再点击进入店铺,内容页是种草、买家使用体验和好物分享的合集,这个合集可以由商家在后台做精选操作,它所承载的责任之一是辅助加速用户的购物决策,为商家带来新增量。
从用户逛淘宝的习惯看,不管是好物分享或是使用体验,“场景感”或者说“氛围感”的呈现是这两年商家打爆款的利器。用户看到好的内容后进行点击跳转,不论是关注店铺还是达人,或是形成购物,最终都能增加用户黏性,成为商家的私域资产,所以它承载的责任之二是私域转化,高效利用存量。
以上两点都是过去传统内容端的运行方式,将其与店铺私域经营进行强绑定,是这次改动的一个重要价值。而且这次的改动针对全平台所有商家,包括达人店铺、直播店铺、视频店铺和一般商家。
记者了解到,未来一年内会有更多流量和资源向直播和短视频倾斜,整个手淘的信息流中,内容占比将提升至30%。
而平台的推流与商家发布的视频“量”并没有直接关系,“只与内容的好坏相关”。这就意味着,所有人将在这30%的流量面前,站在同一起跑线上,从而撬动更大的机会。
流量增加体感明显
各个类型商家都可以有不同的内容
早在2022年,淘宝就已经开始“视频店”的试水,“任意点进一个视频,都会跳出链接”。
而这次改动更为彻底,在淘系内部被称为“店号一体”,实际的改动远远超过我们表面所看到的,是一次从前端到后端的大改版。
商家可以直接利用后台整合的工具,直观地看到“哪条内容带来的流量更多”,进而了解什么样的内容更适合自己的店铺,而不是千篇一律的模仿。再通过对粉丝的精细化管理和运营,“后台给商家准备了各种工具”,可以承接住流量,完成最终的闭环。
「卖家」随机采访了几位商家,发现他们对这次改版的理解并不统一,而一些动作快的商家已经尝到甜头。
某家居店铺(店铺粉丝1.7万,商品价格区间100元—300元):
“目前单篇内容主要是靠公域流量、推荐流量,视频的效果比较明显一点,同比有增长,视频占整个流量的15%。”
某厨具店老板(店铺粉丝4.4万,主消费产品价格区间100元—2000元):
“我们现在体感没那么明显,最近一个月和上个月差不多。”
某全品类美妆品牌(店铺粉丝2000万以上,产品价格区间10元—1700元):
“我们现在的内容主要是护肤知识进行软植入,结合时下热点,真人出镜拍摄,种草效果还可以。我们打算大量去铺视频。”
我们可以很明显看到,不同类型的商家在这次的改版中都可以找到自己的机会。
传统品牌店铺具备一定货品优势和玩法经验,通过“店号一体”给用户提供多样性的内容服务,既达到种草的目的,也能增加粉丝粘性,服务私域,跳脱出原本的货架商品搜索的逻辑,形成一条新路径;
内容型商家、达人店铺或者设计向商品天生具备内容优势,提供快速爆发的机会;
货品力和价格力中游的一般淘宝商家,可以从原先的竞争思路中跳脱出来,尝试经营内容店铺,是普通店铺弯道超车的好机会。
据部分媒体报道,直播、私域、内容化、本地零售和价格力,是淘宝天猫在2023年初定下的年度五大战略。如何利用淘系平台的优势,针对“私域战略”进行布局调整,用产品和工具本身的更新迭代来帮助商家建立私域运营的阵地,进而拉起整条战线,不再各自为营,就像有个商家说,“不再像以前,一拳打到棉花上”。
美图设计室上线“AI商拍” 支持AI模特试衣、服装换色等功能
美图设计室正式面向生产力场景推出“美图设计室·AI商拍”,一站式解决电商用户商业拍摄需求。“美图设计室·AI商拍”聚合了美图设计室自2023年4月以来相继上线的多项功能,包括“AI商品图”、“AI模特试衣”,另外与美图设计室的“智能抠图”、“服装换色”、“电商海报”等辅助功能配合,为电商拍摄与设计工作提供一站式解决方案。站长网2023-12-14 18:03:160000DL3DV-10K数据集:可用于深度学习的3D视觉大规模场景
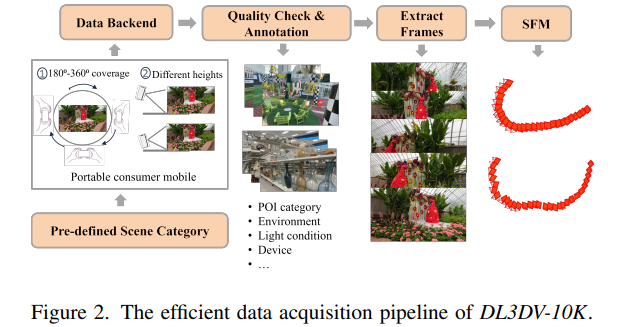
划重点:🌐研究人员介绍DL3DV-10K,这是一个大规模的多视图场景数据集,旨在解决神经视图合成(NVS)中的挑战,为深度学习三维视觉提供强大的数据支持。📊研究团队使用DL3DV-10K评估了现有方法,包括NeRF变体和3D高斯斑点,提出DL3DV-140作为性能基准,揭示了这些方法在各种真实场景中的强弱之处。站长网2024-01-05 12:18:400000谷歌 Android Auto 使用 Google Assistant 和 AI 总结消息
谷歌公司正在为其AndroidAuto平台开发一项新功能,该功能将利用谷歌助手和人工智能(AI)技术来总结信息。根据9To5Google的报道,他们对上传到Play商店的谷歌应用程序14.52版本进行了反编译,并发现了这一功能的代码行。0000小马智行、文远知行,谁是Robotaxi第一股?
自动驾驶企业,正在跑步上市。10月18日,“小马智行”向美国证券交易委员会(SEC)递交招股书,准备在纳斯达克上市。小马智行的竞争对手“文远知行”,则早在今年7月就向SEC递交招股书,同样计划在纳斯达克上市,但目前尚未正式挂牌。小马和文远,是今年自动驾驶上市潮的一部分。0000