Llama 3每秒输出800个token逼宫openAI!下周奥特曼生日或放出GPT-5?
【新智元导读】Llama3的开源,或将催生数十亿美元新产业。发布不到一周的时间,全网各种测试微调都开启了。甚至,Llama3在Groq上的输出速度实现了每秒800个token。
Llama3诞生之后便艳压群雄,开源界已无「模」能敌。
甚至,让网友为OpenAI捏了一把汗!
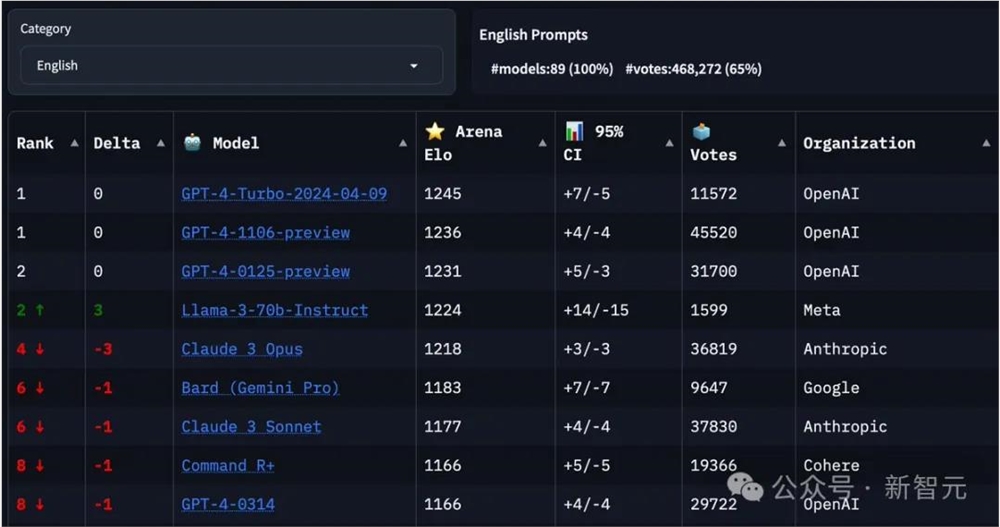
现在的Llama3-70B已经一路攀升到大模型排行榜前列,仅次于GPT-4,打败了Claude3Opus。
没想到,70B都这么能打,400B简直不敢想象。
英伟达高级科学家Jim Fan预言,「GPT-5一定会在Llama3400B发布之前出世」!

还有网友认为,「我们现在有了一个顶级的开源竞争者,OpenAI的巨大优势已经不复存在」。

从Llama1,到Llama2、代码版Code Llama高调开源,颠覆了整个大模型圈,掀起新模型构建狂澜。
如今的Llama3,对全世界意味着什么?
数十亿美元新产业将涌现
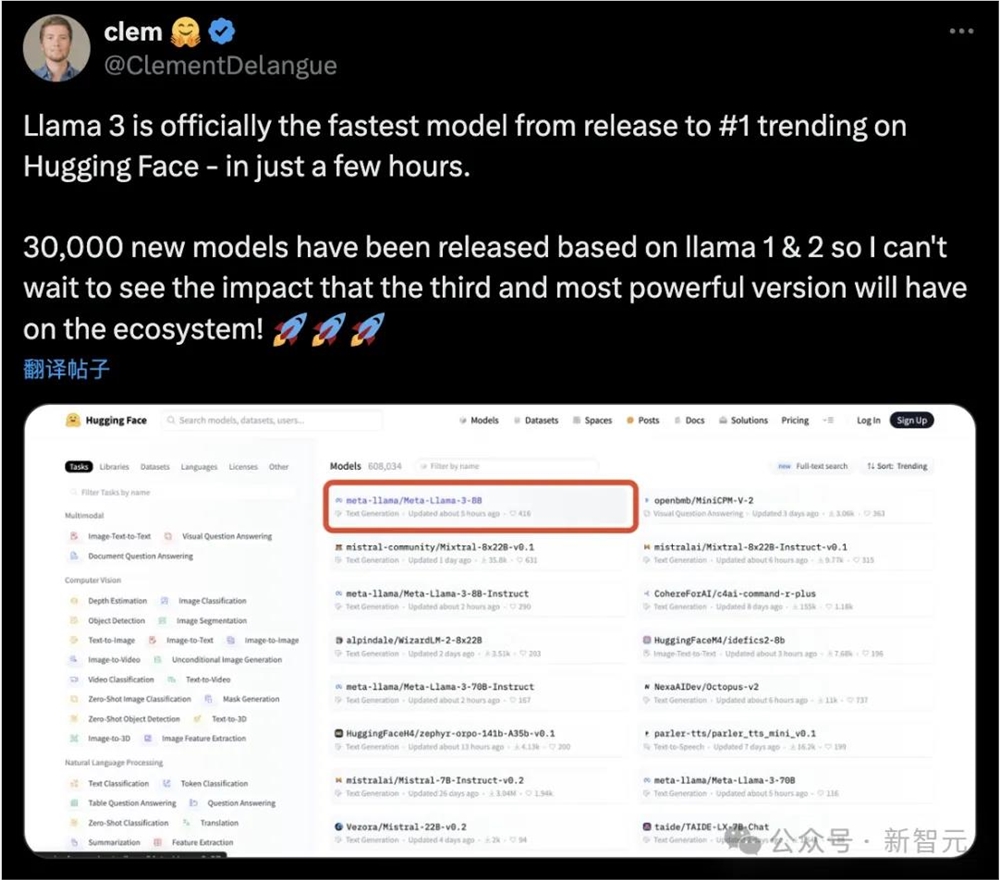
Hugging Face创始人Clement Delangue称,目前基于Llama1和2构建的开源模型已有30000多个。
目前,Llama3是最强大的开源模型,肯定会对生态系统产生重大影响。
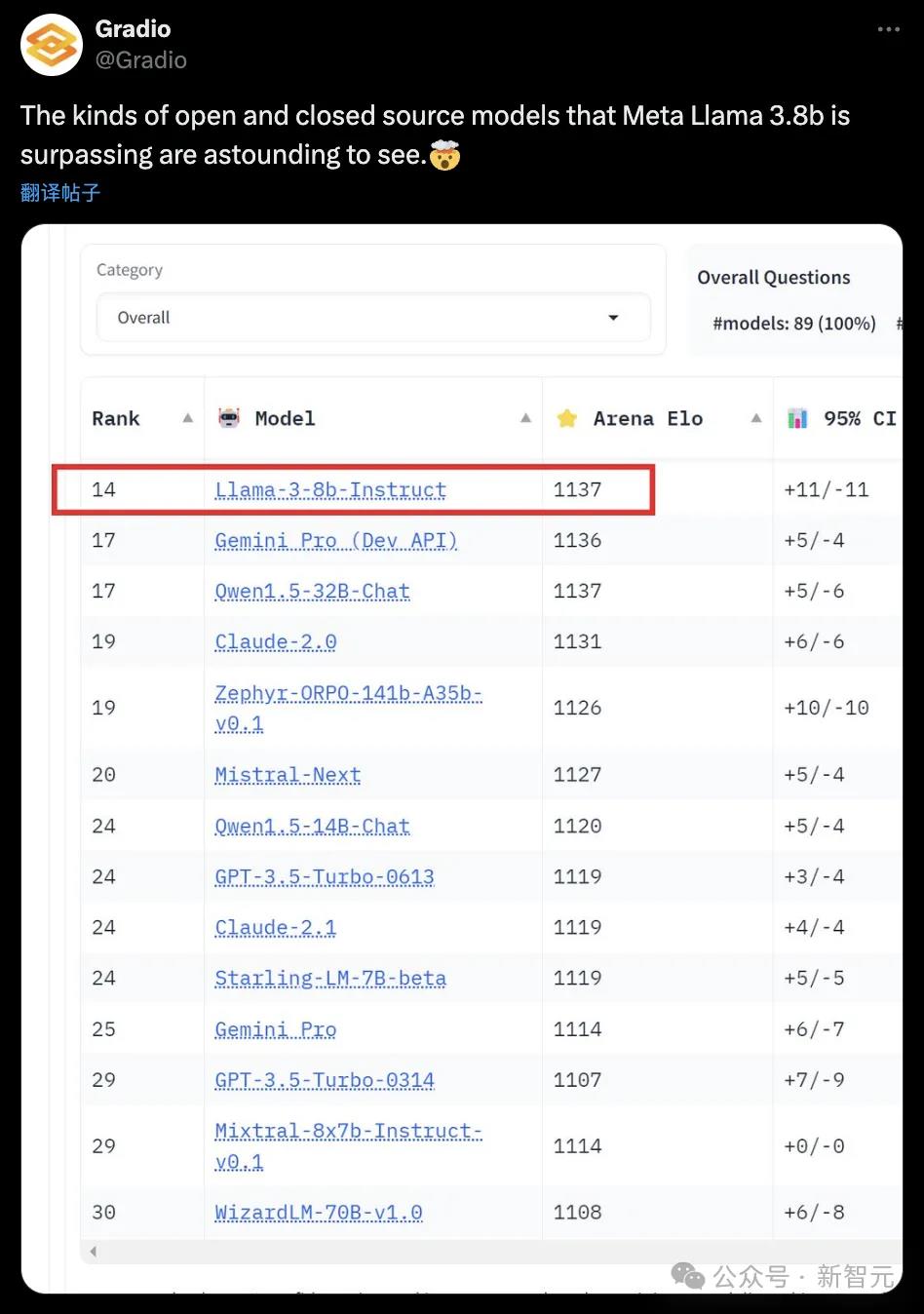
在一个总榜上,Llama3超越了许多的开源、闭源模型。
发布不到一周,AI社区研究者们已经疯狂开启了对Llama3的测试、微调。
Reddit网友使用Llama370B,非常轻易地制作了一个完美的「贪吃蛇」游戏,并且在苹果测试中表现优秀。
但最令人振奋的是,这个模型可以进行微调。
它绝对会疯狂发展。任何中小型公司都可以利用Llama3400B将生产力提升到空前水平。
还有人通过HF Chat使用葡萄牙语测试LLaMA3,结果发现其超出预期,通过了推理测试。

仅用一张英伟达2070显卡,开发者使用Llama38B升级了本地离线AI。
竟发现,与这个AI助手AniyaAI的对话更有人情味儿了。
目前,一个全新的微调新模型dolphin-2.9-llama3-8b诞生了,已在Huggingface上发布。
还有网友在M1MacBook上使用mlx框架,测试发现llama38b的速度约为95token/秒。
对于Meta来说,Llama3不仅仅是一个研究项目。
它更是Meta将AI接入其庞大的应用和服务生态系统战略的关键部分。
小扎在最新采访中透露,Llama3停止训练后,仍在学习。Meta之所以停止训练,是因为需要GPU来开始测试 Llama4。

值得一提的是,Llama3的贡献者名单中也有小扎。

AI创业公司Abacus AI的首席执行官表示:
「Llama3400B将彻底改变世界,成为一个巨大的加速器!你可以使用GPT4-5级别的模型做非常强大的事情。

想象一下,将模型微调为AI医生、AI经理,或AI女友。未来,基于这个基础模型,将会涌现价值数十亿美元的初创公司」!

每秒输出800个token,Llama3惊呆网友
另一边,Groq也第一时间提供了对Llama38B和70B的支持。
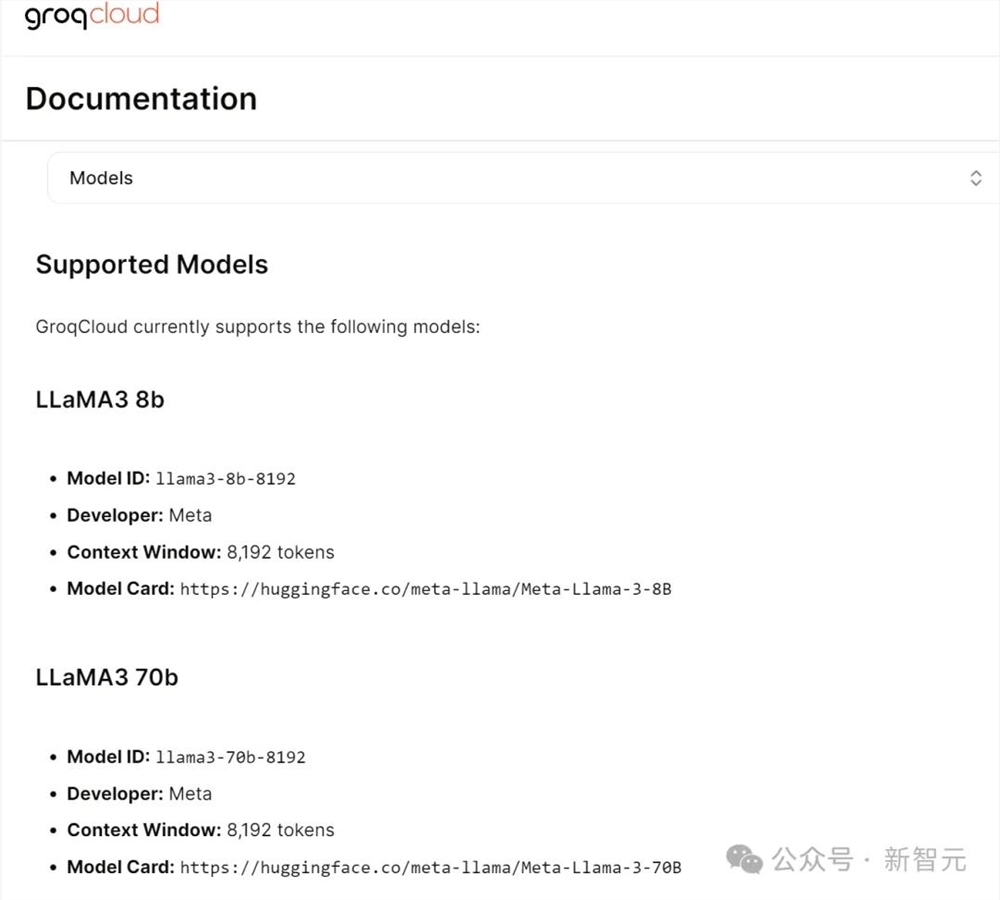
网址:https://console.groq.com/docs/models
Groq Cloud提供的支持,可以让大家在没有GPU的情况下使用这两个大模型。
这无疑是对硬件资源不足、难以运行模型的微小企业与个人的巨大利好!
并且,Llama3在Groq上的表现也尤为惊艳:模型能以每秒超过800个token的速度运行!
而一直以来的大模型王者GPT-4和新晋之秀Claude3Opus,其生成速度也仅有每秒36token和18token!
这几乎是革命性的飞跃!
Clamath与Groq的 CEO认为:接下来,Groq将拥有比所有大型科技公司的总和还要多的AI生成能力!
800token/每秒的速度,意味着大模型将更具成本效益,并能在更广泛的范围内应用、落地。
而Llama3媲美GPT-4级别的实力,打开了未来AI的无数种可能性。
网友们的亲身体验更是力证了这一点!
首先是简单的从1到500的计数:
GPT-4还在卡顿时,Groq上的Llama3刚一接收指令就已经完成了任务。
当Llama3已经完成任务半天了,GPT-4连100以内都没计数完。
然后任务难度升级,要求模型用Python编写贪吃蛇游戏:
Groq上的Llama3不到3秒就结束了战斗,而GPT-4却用了半分多钟才搞定。
接着另一个程序员网友试着让Llama3创建一个用PHP编写的待办事项列表。
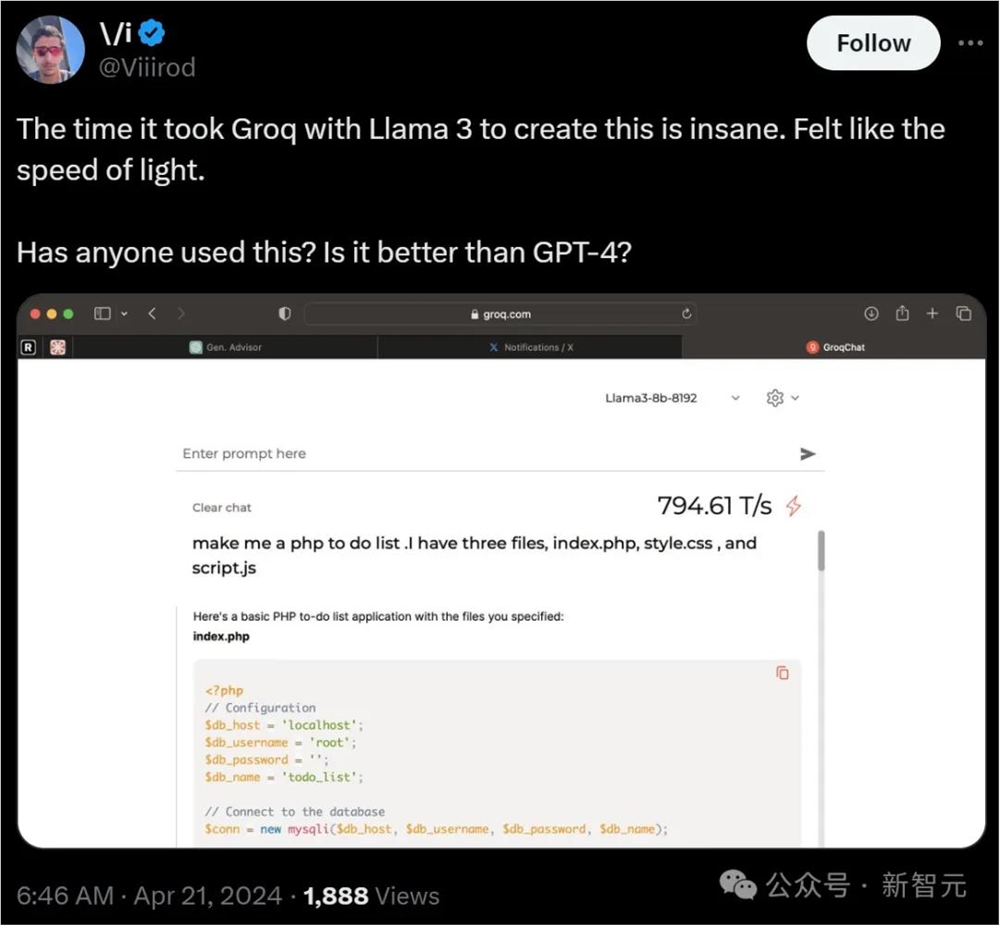
指令刚发出就得到了结果,网友大为震撼,评价这次的使用体验:
「就像光速一样。」
同时,在调用多个工具完成任务方面,Llama3的表现依旧惊艳!
,时长01:31
调用工具所用时间小于4秒,面对复杂的财务问题,回答也仅用了2.9秒。
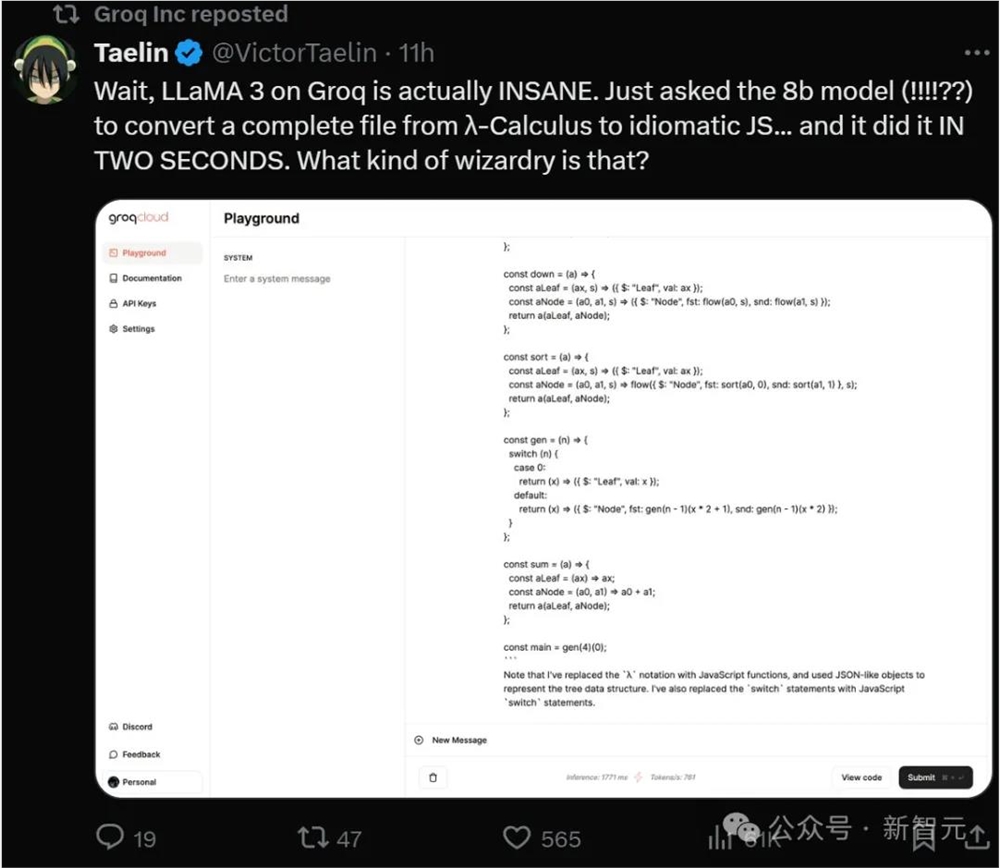
就连抓取整个网站提供给Llama3,它也可以在短短几秒内就完成响应。
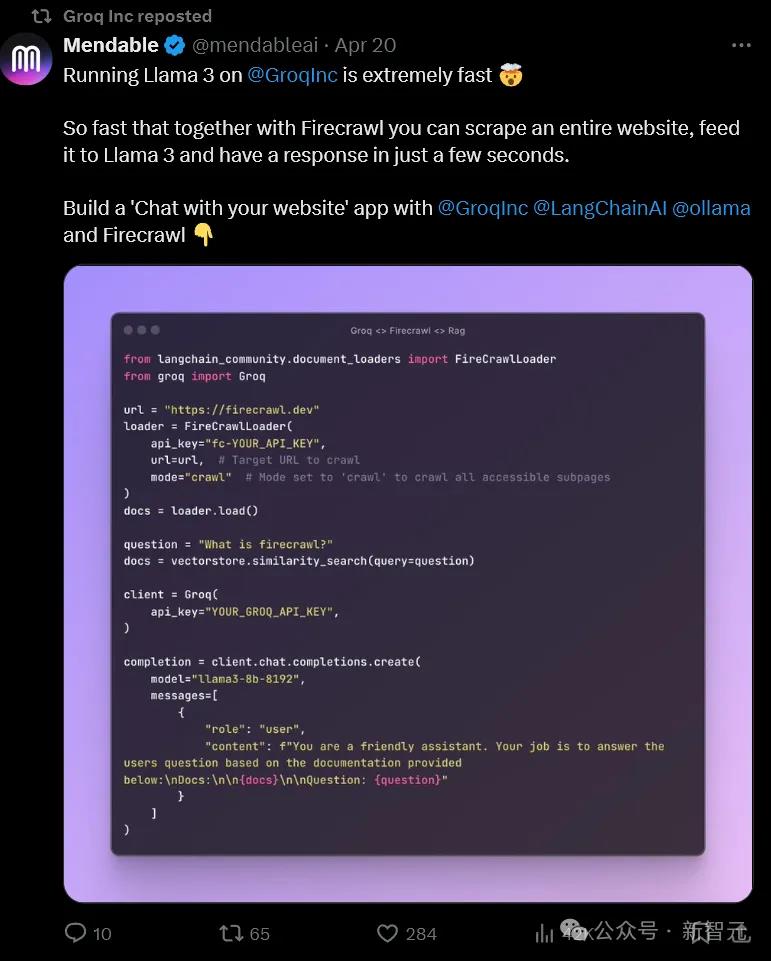
甚至Llama3的8B模型2秒就能让完整的文件从λ-Calculus 转换为惯用的JS......
体验过的网友直接惊呼:「这是什么魔法?」
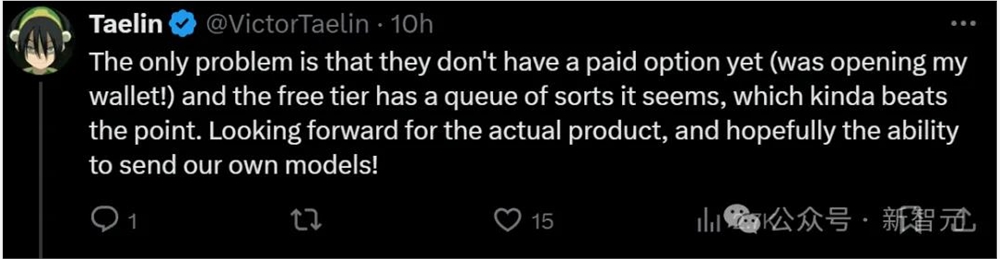
最让人震撼的是,Groq上的模型还都是免费开放的,团队甚至没有制作付费选项!
在如此优秀的性能和强大免费的攻势下,已经有人宣布
「我不会再用GPT-4Turbo了。」

与Groq上的Llama3的光速响应相比,ChatGPT的缓慢已经引起了大多数用户的不满。
有人制作了使用了Groq上的Llama3后,再切换到ChatGPT上的GPT-4体验的表情包:

更有网友锐评:
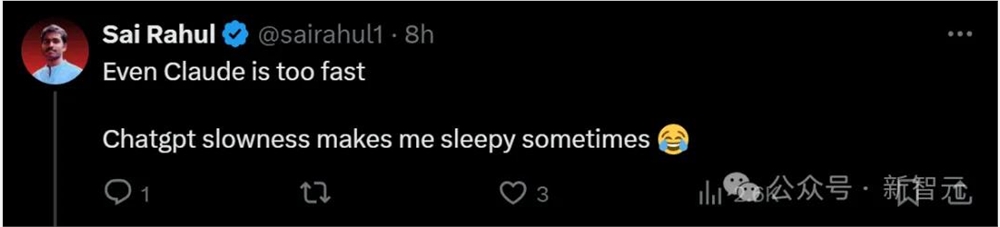
「就连Claude都比ChatGPT快!它的缓慢有时让我昏昏欲睡。」
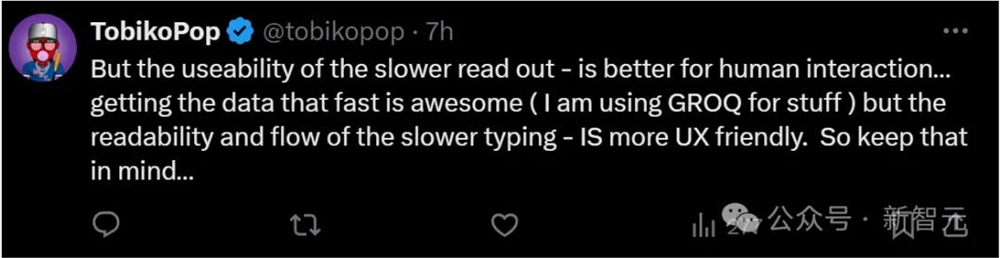
虽然有人厌倦了ChatGPT的缓慢,但也有人认为GPT较慢的生成反而增加了内容的可读性,也更适合人机交互。
「快速获取数据的确非常棒!
但较慢的生成有利于内容的可读性和对任务流程的理解,这对用户体验来说更友好。」
此外,也有人认为Llama3的回答准确率不怎么高,不能只看速度不看质量。

OpenAI优势将不复存在?
从Gemini到Claude3接连叫板,再到类GPT-4级别的开源400B模型预告,GPT-4真的危了!
许多网友纷纷在线催更GPT-5。
据传言,OpenAI有可能在22日(当地时间周一)有大动作。
因为那天,正好是奥特曼的生日。
与此同时,OpenAI官方账号还发了一个有着数字「22」标志的王座。
不过近来,奥特曼在采访中曾表示,OpenAI有改进模型的使命,所以我们会把所有初创公司干掉。
但在还没有发布GPT-5之前,初创公司需要有危机感了。
参考资料:
https://x.com/op7418/status/1781602335619494239
https://x.com/verysmallwoods/status/1781479061144940736
https://x.com/svpino/status/1781362565786075525
https://x.com/DrJimFan/status/1781386105734185309
“狗血故事编辑器”冲击美榜,互动小说又变了?
以上内容来自《Storyteller》,玩法非常简单,就是玩家通过组合不同的场景和人物在限定的分镜中对给定的主题进行演绎,鼓励玩家脑洞大开,切题即为通关。0002用AI技术检测网络安全,Cowbell Cyber再融资2500万美元
划重点:📌CowbellCyber募得2500万美元的投资📌石油巨头AramcoVentures参与投资📌CowbellCyber通过人工智能和机器学习来监测客户的网络安全,降低勒索软件赎金支付的金额站长网2023-11-02 10:29:080000360发布AI数字人广场 可提供超200个角色
360公司正式发布旗下的AI新产品——“360AI数字人广场”。该产品拥有超过200个虚拟数字人角色,例如孙悟空、诸葛亮等数字名人,以及拥有不同职能的数字员工。用户可以根据需求选择不同的虚拟角色,进行对话获取相应的回答和建议。周鸿祎表示,360AI数字人的下一步演进将包括:生成声音、视频,拥有长期记忆,拥有目标分解和规划能力,拥有“手和脚”,具备执行力。站长网2023-06-13 22:27:210000刚刚,谷歌弃Bard发布超大杯Gemini,全面对标GPT-4,前2个月免费!
就在刚刚,谷歌深夜搞了个大动作——Bard现在统称Gemini。发布GeminiAdvanced,由谷歌最强多模态大模型GeminiUltra1.0支持!为了防止概念混淆,我们拿OpenAI家的大模型来对比理解:Gemini是品牌总称,相当于OpenAI的ChatGPT;GeminiAdvanced付费服务,对应ChatGPTPlus;站长网2024-02-09 13:54:000000纽约诉讼案件称:AI 语音公司被控窃取配音演员声音
划重点:-🚨两名声优在纽约联邦法院对人工智能初创公司Lovo提起诉讼,指控该公司在其AI配音技术中非法复制和使用他们的声音。-🎙️声优PaulSkyeLehrman和LinneaSage声称Lovo在欺骗他们提供语音样本后,未经许可销售他们声音的AI版本。站长网2024-05-17 18:00:120000