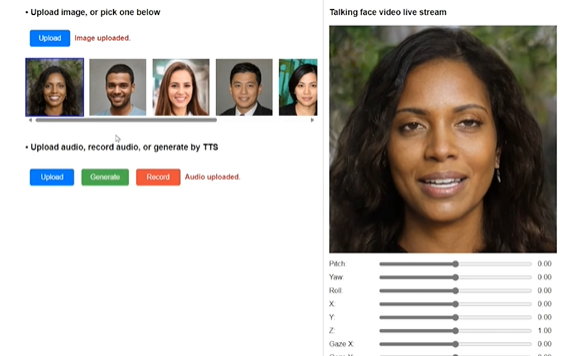
EMO同款?微软发布对口型软件VASA-1 图片加语音即可生成逼真说话视频
由微软亚洲研究院开发的VASA-1项目,是一项前沿的人工智能技术,它能够将单一静态图像和一段语音音频转换为逼真的对话面部动画。这项技术不仅能够实现音频与唇部动作的精确同步,还能够捕捉并再现丰富的面部表情和自然的头部动作,极大地增强了生成视频的真实感和生动性。
主要功能与特点:
逼真的面部动画: VASA-1可以根据一段语音音频和单一静态图像生成逼真的对话面部视频,包括精确的唇部运动同步和复杂的面部表情及头部动作。
高度自然的头部动作: VASA-1能够生成包括点头和转头在内的自然头部运动,这些都是人类交流中常见的非语言行为。
实时视频生成: 利用NVIDIA RTX4090GPU,VASA-1能够实现高性能的视频生成。它支持在离线模式下以45fps生成512×512分辨率的视频,以及在线流模式下的40fps生成速度,前置延迟仅为170毫秒,适合实时应用。
泛化能力: 模型展现出强大的适应能力,即使面对与训练数据不同的音频或图像,如不同的语言或非常规的艺术照片,也能够有效工作。
支持多种语言: VASA-1不仅支持中文,还能处理多种语言的语音输入,甚至能够生成唱歌的动画。
解耦能力: 模型能够独立处理和控制人脸的不同动态特征,如嘴唇运动、表情、眼睛注视方向等,提供了高度的解耦和可控性。
生成的可控性: 通过引入条件信号,如眼睛注视方向、头部距离和情绪偏移,VASA-1增强了视频生成的可控性,允许更精细的调整和个性化的动画输出。
技术原理:
VASA-1项目利用了一系列先进的计算机视觉和机器学习技术,包括面部潜在空间构建、数据集处理、3D辅助表征、整体面部动态和头部动作生成、音频条件化的生成控制、以及实时生成支持等。这些技术的应用使得VASA-1能够生成与音频高度同步的、具有丰富表情和动作的逼真面部动画。
案例与资源:
微软亚洲研究院提供了VASA-1的项目演示和相关论文,以供有兴趣的研究人员和开发者进一步探索和学习。所有在演示中使用的肖像图像,除了蒙娜丽莎外,都是由StyleGAN2或DALL-E-3生成的虚拟、不存在的身份图像。
项目地址:https://top.aibase.com/tool/vasa-1
论文地址:https://arxiv.org/abs/2404.10667
第二代蔚来手机 NIO Phone 2手机或将于 7 月 27 日发布
蔚来汽车公司宣布,NIOIN2024蔚来创新科技日将于7月27日在上海举行。届时,蔚来将发布其第二代智能手机——NIOPhone。蔚来创始人、董事长李斌在今年3月的“共话江城”活动中曾透露,第二代NIOPhone的研发已经完成,并已进入生产阶段。蔚来每年计划推出一款新手机,以确保产品的质量和用户体验。站长网2024-07-22 17:41:520000公众号粉丝8500,变现100万。
各位村民好,我是村长。公众号粉丝越少,才越赚钱。当我提出这个观点的时候,绝大多数人都会反对,因为这和大家的常识是违背的。但只有真正实操过的人,才知道,粉丝量不等于变现力。今天我想以我实际的经验和大家一起来分享一下,也鼓励大家开始写作。01公众号涨粉慢很正常公众号早就过了野蛮生长期,所以现在对于许多创作者来说,涨粉慢是一件很痛苦的事情。站长网2023-04-26 09:05:240001英国筹款平台JustGiving 提供生成式AI创建筹款页面
本文概要:1.JustGiving将提供生成式人工智能技术,帮助人们更快地创建筹款页面和分享个人故事。2.撰写个人故事是筹款页面的关键部分,使用清晰故事的页面筹集的资金比不使用的高出65%。3.人工智能服务是可选的,不想使用的筹款人可以选择不使用。英国筹款平台JustGiving将引入生成式人工智能技术,以帮助筹款者更快速地创建筹款页面和分享个人故事。站长网2023-08-22 14:33:490000最低9美元/月!Stability AI推Stable Assistant 可用SD3生成图片
划重点:🤖StableAssistant是由StabilityAI开发的友善聊天机器人,搭载了StabilityAI的文本和图像生成技术,包括StableDiffusion3和StableLM212B。💬StableAssistant支持使用SD3生成图片、通过文字编辑图片、生成式填充图片、提升分辨率、生成视频、去除背景、线稿转图片、改变画风等。站长网2024-05-27 19:35:510001iOS17.2为 iPhone15Pro 的操作按钮添加翻译功能
苹果最近发布了iOS17.2更新,为iPhone15Pro系列的操作按钮添加了新的翻译功能。这个功能允许用户将翻译任务分配给操作按钮。当按下操作按钮时,它将启动翻译应用程序的对话模式,无需离开当前应用程序。这极大地简化了在不同语言之间快速翻译短语或进行对话的过程。站长网2023-10-27 09:46:570000