谷歌最新的人工智能大型语言模型 PaLM 2 在训练中使用的文本数据是其前身的近五倍
据 CNBC 披露,谷歌上周宣布的新型大型语言模型 PaLM 2 使用的训练数据量几乎是 2022 年前身的 5 倍,可执行更高级的编码、数学和创意写作任务。据 CNBC 获悉,谷歌的新通用大型语言模型(LLM)PaLM 2 已训练了 3.6 万亿个 token。而 token 是单词字符串,是训练 LLM 的重要组成,因为它们使模型能够预测序列中接下来出现的单词。

过去谷歌的 PaLM 使用了 7800 亿个 token,虽然谷歌一直渴望展示其人工智能技术的强大功能以及如何将其嵌入搜索、电子邮件、文字处理和电子表格中,但公布训练数据量及其它细节方面一直非常保密。微软支持的 ChatGPT 的创建者 OpenAI 也保密其最新的 LLM GPT-4 的细节。
两家公司都表示,不公开训练数据等细节是因为业务竞争的原因,但研究界呼吁进行更大的透明度。自公布 PaLM 2 以来,谷歌已表示新模型比以前的 LLM 更小,这表明谷歌的技术正在变得更加高效,同时可以完成更复杂的任务。PaLM 2 据内部文档所示,已经训练了 3400 亿个参数,是模型复杂性的指标。而初始的 PaLM 则是训练了 5400 亿个参数。至于 PaLM 2 的训练数据具体来自哪里,谷歌发言人拒绝发表评论。
据谷歌在 PaLM 2 的博客文章中表示,这种新技术称为「compute-optimal scaling」,通过这种方法,LLM 运行效率更高,性能更好,包括更快的推理、更少的服务参数以及更低的服务成本。谷歌证实 PaLM 2 已经训练了 100 种语言,并且可以执行广泛的任务,已经被用于推动 25 个功能和产品,包括谷歌的实验性聊天机器人 Bard。它提供四种大小的选择,从最小的 Gecko 到最大的 Unicorn。
众所周知,PaLM 2 比现有任何模型都更强大,在公开披露的数据中如此。Facebook 的 LLM 称为 LLaMA,是在今年 2 月宣布的,使用了 1.4 万亿个 token 训练。上一次 OpenAI 披露 ChatGPT 的训练规模是在 GPT-3 时,当时公司表示它使用了 3000 亿个 token,而现在 OpenAI 在 3 月份推出了 GPT-4,并表示该模型在许多专业测试中达到了「人类水平的表现能力」。
如今,随着新的 AI 应用快速走向主流,围绕 AI 的争议也变得越来越激烈。谷歌的高级研究科学家 El Mahdi El Mhamdi 在 2 月份因公司缺乏透明度而辞职。周二,OpenAI 首席执行官 Sam Altman 在参议院隐私和技术小组的听证会上作证,同意议员们需要一个处理 AI 的新系统。「对于这项非常新的技术,我们需要一个新的框架,」Altman 说:「像我们这样的公司肯定要对我们在世界上推出的工具负起很大的责任。」
苦等7年果粉欢呼!微信CallKitt功能意外回归:支持灵动岛显示
快科技1月19日消息,日前,不少苹果用户在社交平台发帖称,自己的微信突然有了CallKit功能。根据用户反馈,微信的CallKit功能目前处于灰度推送阶段,只需在设置-消息通知”中找到语音和视频通话用系统电话接听”选项,即可开启该功能。启用CallKit后,微信语音和视频来电将直接在系统电话界面中显示,用户可以像接普通电话一样接听。站长网2025-01-19 10:21:060000百度资深副总裁梁志祥接管公关业务 知情人士:此前璩静便向其汇报
快科技5月21日消息,据媒体报道,在原公关副总裁璩静因短视频争议言论离职后,百度资深副总裁梁志祥已暂时接管了公关业务。不过据知情人士透露,璩静在离职前的工作汇报对象就是梁志祥,目前尚无人员填补璩静的职位空缺。目前,关于梁志祥接管公关业务的性质,尚不明确是临时措施还是长期安排,百度方面未对外界透露更多关于该职位的未来规划。站长网2024-05-22 00:48:500000奇富科技宣布组建大模型部门 砸下2000万年薪招揽技术大牛
据新浪科技消息,奇富科技(原360数科)内部人士透露,该公司近期宣布组建一级战略部门大模型部,致力于开发和运用深度学习算法、生成式人工智能技术和在金融领域的场景化应用。大模型部门从公司内部选拔优秀员工,提供必要的培训和发展机会,外部也会招聘资深人才。目前国内大模型行业开始爆发,各家公司都在争抢这个行业里比较顶尖的人才,挖猎薪资非常高,部分公开招聘的高端技术人才,岗位年薪已接近2000万。站长网2023-04-25 14:33:560002甲骨文创始人身价超过巴菲特和盖茨成为全球第四大富豪 受益于 AI 需求强势增长
甲骨文发布了超出华尔街预期的财报及季度营收指引,使得该公司的股价在周一盘后交易中股价上涨5%。根据一份声明,甲骨文上季度的营收同比增长了17%。净收入达到33.2亿美元,每股收益为1.19美元,相比去年同期的31.9亿美元和每股收益1.16美元有所增长。站长网2023-06-13 14:58:490000研究:代码数据增强技术在深度学习中的应用具有巨大潜力
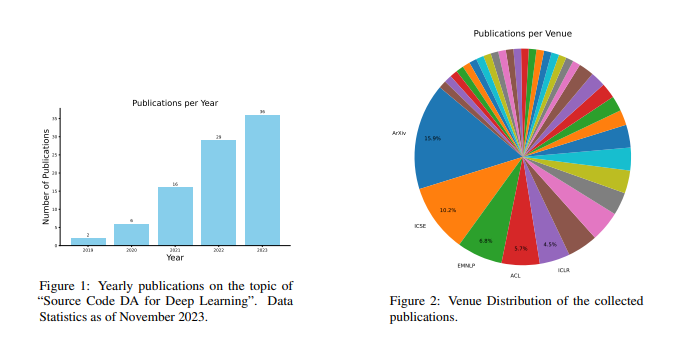
要点:1、代码数据增强技术在深度学习中的应用具有巨大潜力,能够提高模型性能和稳健性。2、代码数据增强面临着独特的挑战,包括代码的特殊性和多模态特性,但已经取得了一些令人鼓舞的成果。3、代码数据增强方法主要分为基于规则的技术、基于模型的技术和示例插值技术,每种方法都有其特点和适用场景。站长网2023-11-23 15:04:560001