Nvidia因使用侵权作品训练NeMo AI平台被作者起诉
**划重点:**
1. 📘 三位作者控告Nvidia未经许可使用其版权图书训练NeMo AI平台。
2. 📚 Brian Keene、Abdi Nazemian和Stewart O'Nan称其作品成为约196,640本书的数据集的一部分,用于NeMo模拟书面语言。
3. 🚫 作者指称其作品在NeMo训练后被撤下。
在一场法律纷争的风波中,以其芯片驱动人工智能的Nvidia公司被三位作者起诉,指控其未经许可使用了其版权图书来训练NeMo AI平台。
Brian Keene、Abdi Nazemian和Stewart O'Nan三位作者提起了诉讼,声称他们的作品成为NeMo AI平台训练的约196,640本书的数据集的一部分。这些作品的使用旨在模拟普通书面语言,然后在训练完成后被撤下。

这场法律纷争引发了关于人工智能领域中知识产权的争论,特别是在大规模数据集的使用方面。Nvidia作为一家领先的芯片制造商,其产品广泛应用于人工智能领域,但这次诉讼揭示了在AI开发中,公司是否足够重视版权问题的争议。
根据起诉书,Nvidia使用了大量的图书数据,其中包括了Keene、Nazemian和O'Nan的作品,用于NeMo AI平台的训练。这一平台的目的是模拟普通书面语言,使其能够更自然地理解和生成文本。然而,作者们指控Nvidia在这一过程中没有获得他们的许可,侵犯了他们的知识产权。
起诉书中提到的数据集规模庞大,包含了近20万册图书。这引发了关于数据集来源和知识产权保护的深刻问题。在数字时代,数据集的质量和来源是AI发展中不可忽视的因素之一,但与之伴随的知识产权问题也变得日益复杂。
三位作者的代表律师表示,他们要求法院对Nvidia采取行动,以确保类似的侵权行为不再发生,并为他们的客户获得赔偿。这一案件可能成为AI领域中关于版权和数据使用的重要先例,对未来的行业规范和公司行为可能产生深远的影响。
Nvidia尚未就此案发表正式回应。这场官司引发了业界对于AI开发中的法律和伦理问题的关注,特别是在公司使用大规模数据集时应该遵循的规定和程序。对于整个科技行业而言,这也是一个提醒,即在追求创新的同时,应当更加注重尊重知识产权和保护作者的权益。
剑桥词典公布2023年度词汇:AI改变了“幻觉”的定义
#划重点:1.📚剑桥词典宣布2023年的年度词汇是“幻觉”,并赋予其与人工智能技术相关的新含义。2.🤖人工智能工具如ChatGPT引起了2023年对AI技术的强烈兴趣,但随之而来的是人们对AI生成文本不可靠的认识。3.🧠AI“幻觉”已经在现实世界产生影响,涉及虚构法律案例等。站长网2023-11-15 20:47:400000英伟达最强通用大模型Nemotron-4登场!15B击败62B,目标单张A100/H100可跑
最近,英伟达团队推出了全新的模型Nemotron-4,150亿参数,在8Ttoken上完成了训练。值得一提的是,Nemotron-4在英语、多语言和编码任务方面令人印象深刻。论文地址:https://arxiv.org/abs/2402.16819在7个评估基准上,与同等参数规模的模型相比,Nemotron-415B表现出色。甚至,其性能超过了4倍大的模型,以及专用于多语言任务的模型。站长网2024-03-01 09:37:300000百度Comate智能代码助手上线SaaS版本 适配100种开发语言
百度智能云宣布百度Comate智能代码助手正式上线SaaS版本,可提供10余项编码功能,适配100种开发语言。即日起企业和开发者可前往百度Comate官网体验(https://comate.baidu.com)。站长网2023-10-25 09:26:3500013550万美元A轮融资,Praktika携手AI虚拟导师打造沉浸式英语学习课堂
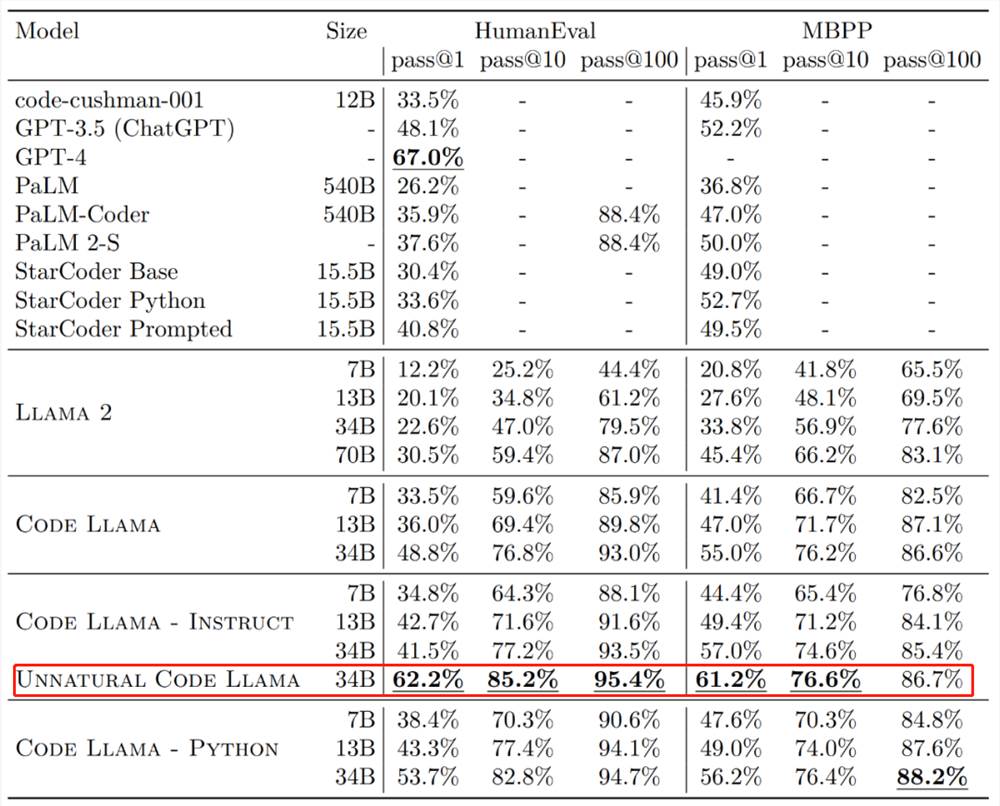
大多数语言学习应用通过选择选项或滑动卡片进行互动,用户或多或少是在与机器互动。然而,Praktika则采用了不同的方法:它让用户创建个性化的AI虚拟形象,模拟真人面授导师的课堂体验,利用语音语调和情感,使语言学习更加自然。Sense思考我们尝试基于文章内容,提出更多发散性的推演和深思,欢迎交流。站长网2024-06-08 12:44:000001发布一天,Code Llama代码能力突飞猛进,微调版HumanEval得分超GPT-4
昨天(8月25日)的我:在代码生成方面开源LLM将在几个月内击败GPT-4。现在的我:实际上是今天。昨天,Meta开源专攻代码生成的基础模型CodeLlama,可免费用于研究以及商用目的。站长网2023-08-27 15:24:400000