发布一天,Code Llama代码能力突飞猛进,微调版HumanEval得分超GPT-4
昨天(8月25日)的我:在代码生成方面开源 LLM 将在几个月内击败 GPT-4。现在的我:实际上是今天。
昨天,Meta 开源专攻代码生成的基础模型Code Llama,可免费用于研究以及商用目的。
Code Llama 系列模型有三个参数版本,参数量分别为7B、13B 和34B。并且支持多种编程语言,包括 Python、C 、Java、PHP、Typescript (Javascript)、C# 和 Bash。
Meta 提供的 Code Llama 版本包括:
Code Llama,基础代码模型;
Code Llama-Python,Python 微调版;
Code Llama-Instruct,自然语言指令微调版。
就其效果来说,Code Llama 的不同版本在 HumanEval 和 MBPP 数据集上的一次生成通过率(pass@1)都超越 GPT-3.5。
此外,Code Llama 的「Unnatural」34B 版本在 HumanEval 数据集上的 pass@1接近了 GPT-4(62.2% vs67.0%)。不过 Meta 没有发布这个版本,但通过一小部分高质量编码数据的训练实现了明显的效果改进。
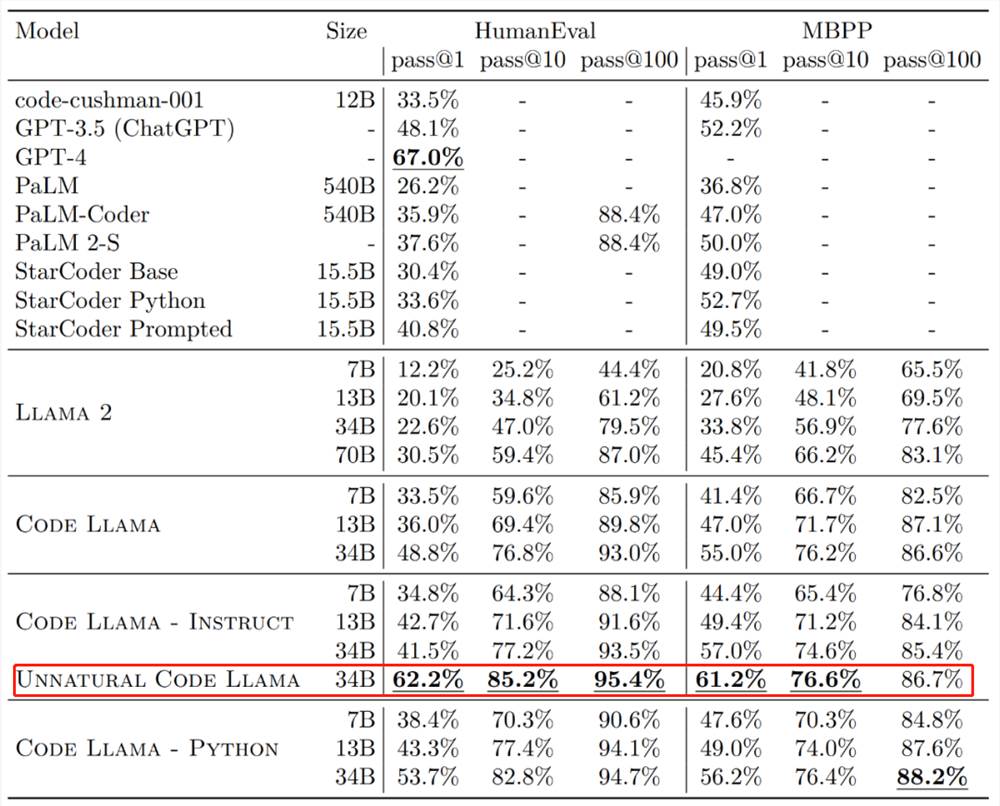
图源:https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/
一天刚过,就有研究者向 GPT-4发起了挑战。他们来自 Phind(一个组织,旨在构造一款为开发人员而生的AI 搜索引擎),该研究用微调的 Code Llama-34B 在 HumanEval 评估中击败了 GPT-4。
Phind 联合创始人 Michael Royzen 表示:「这只是一个早期实验,旨在重现(并超越)Meta 论文中的「Unnatural Code Llama」结果。将来,我们将拥有不同 CodeLlama 模型的专家组合,我认为这些模型在现实世界的工作流程中将具有竞争力。」

两个模型均已开源:

研究者在 Huggingface 上发布了这两个模型,大家可以前去查看。
Phind-CodeLlama-34B-v1:https://huggingface.co/Phind/Phind-CodeLlama-34B-v1
Phind-CodeLlama-34B-Python-v1:https://huggingface.co/Phind/Phind-CodeLlama-34B-Python-v1
接下来我们看看这项研究是如何实现的。
微调 Code Llama-34B 击败 GPT-4
我们先看结果。这项研究用 Phind 内部数据集对 Code Llama-34B 和 Code Llama-34B-Python 进行了微调,分别得到两个模型 Phind-CodeLlama-34B-v1以及 Phind-CodeLlama-34B-Python-v1。
新得到的两个模型在 HumanEval 上分别实现了67.6% 和69.5% pass@1。
作为比较,CodeLlama-34B pass@1为48.8%;CodeLlama-34B-Python pass@1为53.7%。
而 GPT-4在 HumanEval 上 pass@1为67%(OpenAI 在今年3月份发布的「GPT-4Technical Report」中公布的数据)。
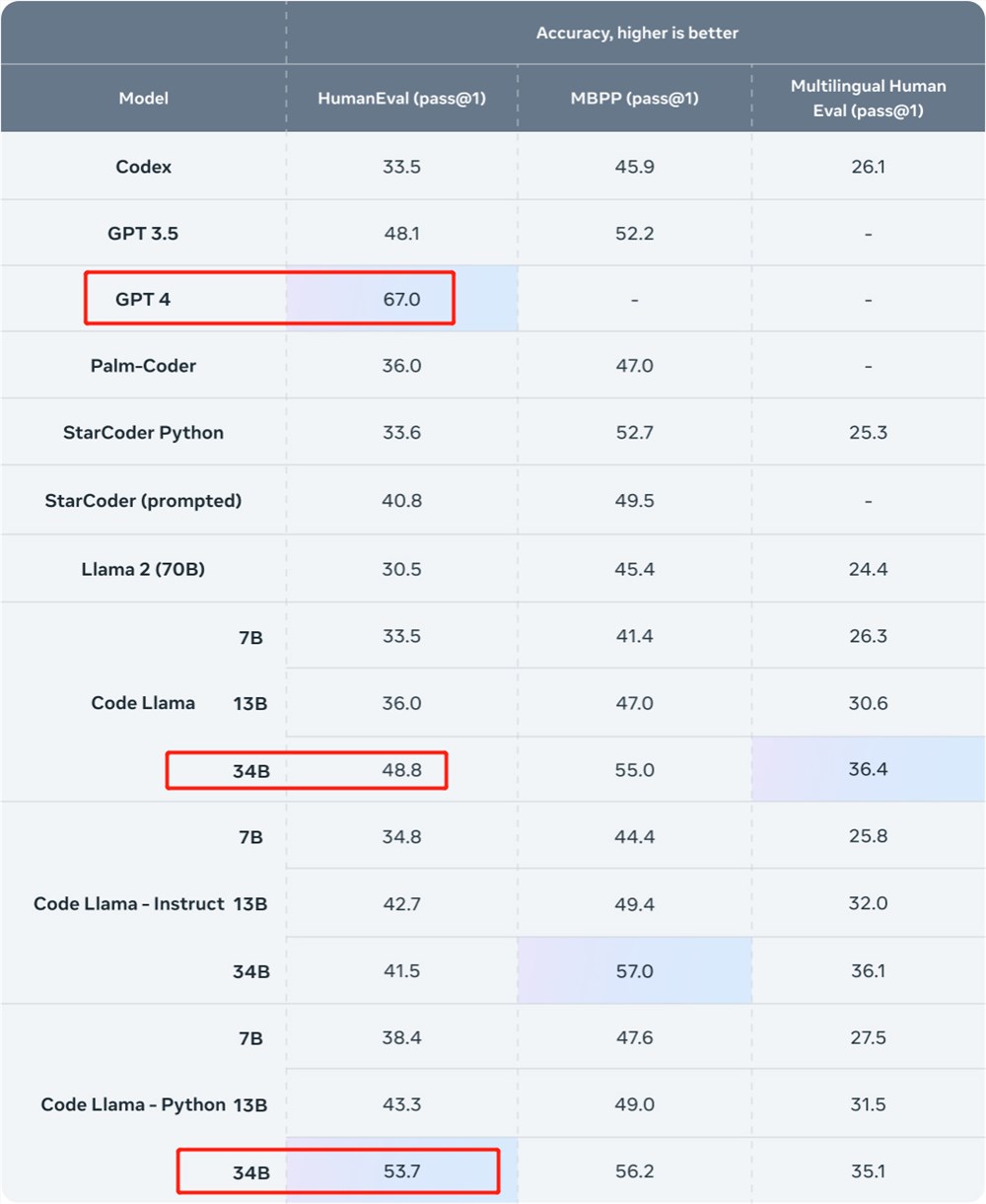
图源:https://ai.meta.com/blog/code-llama-large-language-model-coding/
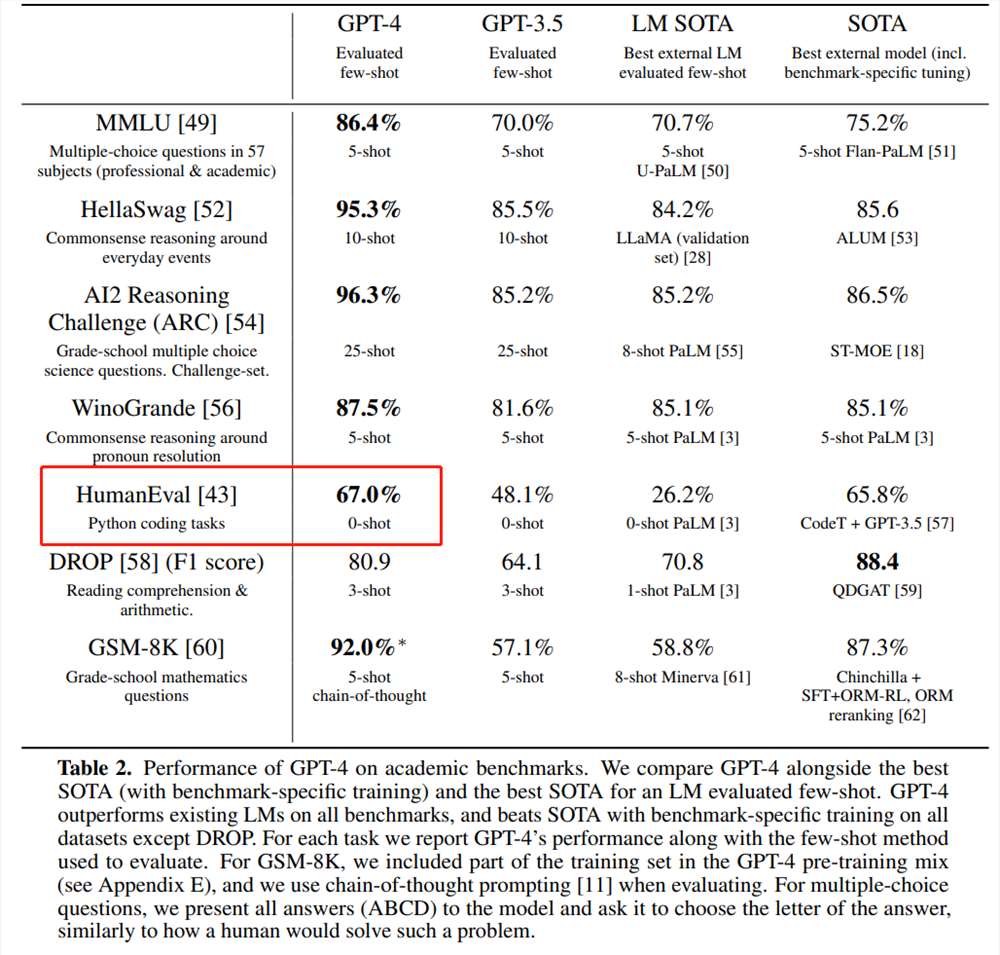
图源:https://cdn.openai.com/papers/gpt-4.pdf
谈到微调,自然少不了数据集,该研究在包含约8万个高质量编程问题和解决方案的专有数据集上对 Code Llama-34B 和 Code Llama-34B-Python 进行了微调。
该数据集没有采用代码补全示例,而是采用指令 - 答案对,这与 HumanEval 数据结构不同。之后该研究对 Phind 模型进行了两个 epoch 的训练,总共有约16万个示例。研究者表示,训练中没有使用 LoRA 技术,而是采用了本地微调。
此外,该研究还采用了 DeepSpeed ZeRO3和 Flash Attention2技术,他们在32个 A100-80GB GPU 上、耗时三个小时,训练完这些模型,序列长度为4096个 token。
此外,该研究还将 OpenAI 的去污染(decontamination)方法应用于数据集,使模型结果更加有效。
众所周知,即便是非常强大的 GPT-4,也会面临数据污染的困境,通俗一点的讲就是训练好的模型可能已经接受评估数据的训练。
这个问题对 LLM 非常棘手,举例来说,在评估一个模型性能的过程中,为了进行科学可信的评估,研究者必须检查用于评估的问题是否在模型的训练数据中。如果是的话,模型就可以记住这些问题,在评估模型时,显然会在这些特定问题上表现更好。
这就像一个人在考试之前就已经知道了考试问题。
为了解决这个问题,OpenAI 在公开的 GPT-4技术文档《 GPT-4Technical Report 》中披露了有关 GPT-4是如何评估数据污染的。他们公开了量化和评估这种数据污染的策略。
具体而言,OpenAI 使用子串匹配来测量评估数据集和预训练数据之间的交叉污染。评估和训练数据都是通过删除所有空格和符号,只保留字符(包括数字)来处理的。
对于每个评估示例,OpenAI 随机选择三个50个字符的子字符串(如果少于50个字符,则使用整个示例)。如果三个采样的评估子字符串中的任何一个是处理后的训练样例的子字符串,则确定匹配。
这将产生一个受污染示例的列表,OpenAI 丢弃这些并重新运行以获得未受污染的分数。但这种过滤方法有一些局限性,子串匹配可能导致假阴性(如果评估和训练数据之间有微小差异)以及假阳性。因而,OpenAI 只使用评估示例中的部分信息,只利用问题、上下文或等效数据,而忽略答案、回应或等效数据。在某些情况下,多项选择选项也被排除在外。这些排除可能导致假阳性增加。
关于这部分内容,感兴趣的读者可以参考论文了解更多。
论文地址:https://cdn.openai.com/papers/gpt-4.pdf
不过,Phind 在对标 GPT-4时使用的 HumanEval 分数存在一些争议。有人说,GPT-4的最新测评分数已经达到了85%。但 Phind 回复说,得出这个分数的相关研究并没有进行污染方面的研究,无法确定 GPT-4在接受新一轮测试时是否看到过 HumanEval 的测试数据。再考虑到最近一些有关「GPT-4变笨」的研究,所以用原始技术报告中的数据更为稳妥。

不过,考虑到大模型评测的复杂性,这些测评结果能否反映模型的真实能力依然是一个有争议的问题。大家可以下载模型后自行体验。
参考链接:
https://benjaminmarie.com/the-decontaminated-evaluation-of-gpt-4/
https://www.phind.com/blog/code-llama-beats-gpt4
谷歌刚修复了一个高危 Chrome 漏洞,可被用于劫持账户
如果你还在犹豫是否要更新浏览器,那么现在是时候动手了。谷歌刚发布了一组Chrome紧急安全更新,其中修复了一个高危漏洞,该漏洞可被黑客利用来接管你的Google账户。据BleepingComputer报道,此次更新共修补了4个漏洞,其中一个尤其令人担忧,因为这个漏洞已在现实中被黑客积极利用。站长网2025-05-17 21:35:410000《杭州新闻联播》首推全AI主持播报:表情生动、肢体自然
快科技2月12日消息,据杭州电视台官方公众号杭州综合频道”介绍,《杭州新闻联播》甲辰龙年上新两位新主播小雨、小宇。这两位主播已经在年初一和年初二的节目中登场,TA们是杭州文广集团短视频AI生产实验车间开发生产的AI数字主播,以两位真人主播雨辰、麒宇为蓝本,采集生成而来。0000OpenAI 首席执行官在国会就 AI 风险作证:人工智能不是致力于自我意识的「生物」
OpenAI首席执行官SamAltman表示,人们不应该试图将人工智能「拟人化」,而应该将这种强大的技术系统视为「工具」而非「生物」。当被问及如果国会不对技术进行监管,人工智能会多快「自我意识」时,Altman在周二在国会山对记者表示:「我认为对这个问题存在大量的猜测。」这种提问方式与电影系列《终结者》有些相似,其中人工智能在「自我意识」之日引发了世界末日。站长网2023-05-17 09:07:260002东南亚走访弹:小杨哥、老罗都在布局的东南亚MCN,真赚钱吗?
进入2023年,出海圈似乎回到了2019年的状态,从业者开始更频繁地出国到本地市场考察和学习。四月初,白鲸出海的几位同事也到印尼、马来走了一圈,实地拜访了不少MCN、海外仓负责人和电商从业者。第一期,我们想聊聊印尼的MCN们。站长网2023-05-12 20:33:480000谷歌被指控窃取数百万用户数据训练人工智能工具
日前,谷歌面临一项广泛的侵权诉讼,指控这家科技巨头未经用户同意,窃取了数百万用户的数据,并违反版权法来训练和开发其人工智能产品。这起对谷歌、其母公司Alphabet和其人工智能子公司DeepMind的集体诉讼于周二在加利福尼亚州的联邦法院提起,由克拉克森律师事务所提出。该律所上个月曾对ChatGPT制造商OpenAI提起类似诉讼。站长网2023-07-12 17:26:030000












