谷歌具身智能新研究:比RT-2优秀的RT-H来了
RT-H 在一系列机器人任务中的表现都优于 RT-2。
随着 GPT-4等大型语言模型与机器人研究的结合愈发紧密,人工智能正在越来越多地走向现实世界,因此具身智能相关的研究也正受到越来越多的关注。在众多研究项目中,谷歌的「RT」系列机器人始终走在前沿(参见《大模型正在重构机器人,谷歌 Deepmind 这样定义具身智能的未来》)。

谷歌 DeepMind 去年7月推出的 RT-2:全球第一个控制机器人的视觉 - 语言 - 动作(VLA)模型。只需要像对话一样下达命令,它就能在一堆图片中辨认出霉霉,并送给她一罐可乐。
如今,这个机器人又进化了。最新版的 RT 机器人名叫「RT-H」,它能通过将复杂任务分解成简单的语言指令,再将这些指令转化为机器人行动,来提高任务执行的准确性和学习效率。举例来说,给定一项任务,如「盖上开心果罐的盖子」和场景图像,RT-H 会利用视觉语言模型(VLM)预测语言动作(motion),如「向前移动手臂」和「向右旋转手臂」,然后根据这些语言动作,预测机器人的行动(action)。

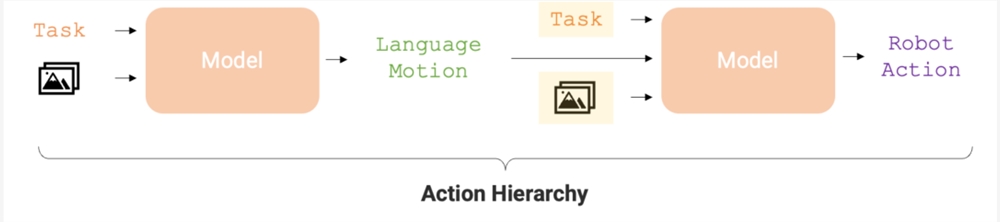
这个行动层级(action hierarchy)对于提高机器人完成任务的准确性和学习效率非常有帮助,使得 RT-H 在一系列机器人任务中的表现都优于 RT-2。

以下是论文的详细信息。
论文概览

论文标题:RT-H: Action Hierarchies Using Language
论文链接:https://arxiv.org/pdf/2403.01823.pdf
项目链接:https://rt-hierarchy.github.io/
语言是人类推理的引擎,它使我们能够将复杂概念分解为更简单的组成部分,纠正我们的误解,并在新环境中推广概念。近年来,机器人也开始利用语言高效、组合式的结构来分解高层次概念、提供语言修正或实现在新环境下的泛化。
这些研究通常遵循一个共同的范式:面对一个用语言描述的高层任务(如「拿起可乐罐」),它们学习将观察和语言中的任务描述映射到低层次机器人行动的策略,这需要通过大规模多任务数据集实现。语言在这些场景中的优势在于编码类似任务之间的共享结构(例如,「拿起可乐罐」与「拿起苹果」),从而减少了学习从任务到行动映射所需的数据。然而,随着任务变得更加多样化,描述每个任务的语言也变得更加多样(例如,「拿起可乐罐」与「倒一杯水」),这使得仅通过高层次语言学习不同任务之间的共享结构变得更加困难。
为了学习多样化的任务,研究者的目标是更准确地捕捉这些任务之间的相似性。
他们发现语言不仅可以描述高层次任务,还能细致说明完成任务的方法 —— 这种表示更细腻,更贴近具体动作。例如,「拿起可乐罐」这一任务可以分解为一系列更细节的步骤,即「语言动作(language motion)」:首先「手臂向前伸」,接着「抓紧罐子」,最后「手臂上举」。研究者的核心洞见是,通过将语言动作作为连接高层次任务描述与底层次动作之间的中间层,可以利用它们来构建一个通过语言动作形成的行动层级。
建立这种行动层级有几大好处:
它使不同任务之间在语言动作层面上能够更好地共享数据,使得语言动作的组合和在多任务数据集中的泛化性得到增强。例如,「倒一杯水」与「拿起可乐罐」虽在语义上有所不同,但在执行到捡起物体之前,它们的语言动作完全一致。
语言动作不是简单的固定原语,而是根据当前任务和场景的具体情况通过指令和视觉观察来学习的。比如,「手臂向前伸」并没具体说明移动的速度或方向,这取决于具体任务和观察情况。学习到的语言动作的上下文依赖性和灵活性为我们提供了新的能力:当策略未能百分百成功时,允许人们对语言动作进行修正(见图1中橙色区域)。进一步地,机器人甚至可以从这些人类的修正中学习。例如,在执行「拿起可乐罐」的任务时,如果机器人提前关闭了夹爪,我们可以指导它「保持手臂前伸的姿势更久一些」,这种在特定场景下的微调不仅易于人类指导,也更易于机器人学习。

鉴于语言动作存在以上优势,来自谷歌 DeepMind 的研究者设计了一个端到端的框架 ——RT-H(Robot Transformer with Action Hierarchies,即使用行动层级的机器人 Transformer),专注于学习这类行动层级。RT-H 通过分析观察结果和高层次任务描述来预测当前的语言动作指令,从而在细节层面上理解如何执行任务。接着,利用这些观察、任务以及推断出的语言动作,RT-H 为每一步骤预测相应的行动,语言动作在此过程中提供额外的上下文,帮助更准确地预测具体行动(图1紫色区域)。
此外,他们还开发了一种自动化方法,从机器人的本体感受中提取简化的语言动作集,建立了包含超过2500个语言动作的丰富数据库,无需手动标注。
RT-H 的模型架构借鉴了 RT-2,后者是一个在互联网规模的视觉与语言数据上共同训练的大型视觉语言模型(VLM),旨在提升策略学习效果。RT-H 采用单一模型同时处理语言动作和行动查询,充分利用广泛的互联网规模知识,为行动层级的各个层次提供支持。
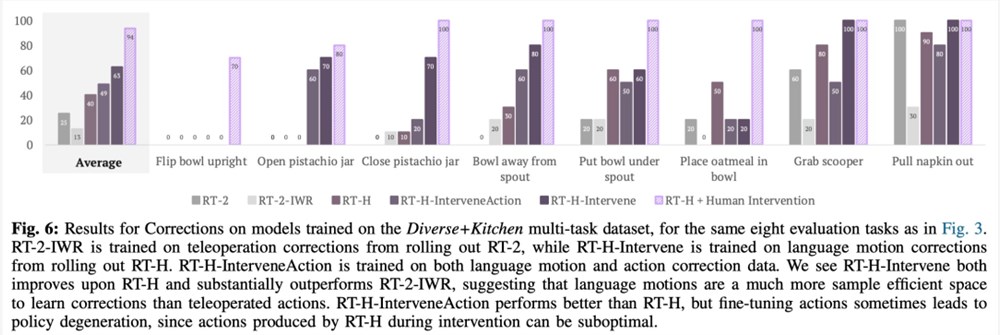
在实验中,研究者发现使用语言动作层级在处理多样化的多任务数据集时能够带来显著的改善,相比 RT-2在一系列任务上的表现提高了15%。他们还发现,对语言动作进行修正能够在同样的任务上达到接近完美的成功率,展示了学习到的语言动作的灵活性和情境适应性。此外,通过对模型进行语言动作干预的微调,其表现超过了 SOTA 交互式模仿学习方法(如 IWR)50%。最终,他们证明了 RT-H 中的语言动作能够更好地适应场景和物体变化,相比于 RT-2展现出了更优的泛化性能。
RT-H 架构详解
为了有效地捕获跨多任务数据集的共享结构(不由高层次任务描述表征),RT-H 旨在学习显式利用行动层级策略。
具体来说,研究团队将中间语言动作预测层引入策略学习中。描述机器人细粒度行为的语言动作可以从多任务数据集中捕获有用的信息,并可以产生高性能的策略。当学习到的策略难以执行时,语言动作可以再次发挥作用:它们为与给定场景相关的在线人工修正提供了直观的界面。经过语言动作训练的策略可以自然地遵循低水平的人工修正,并在给定修正数据的情况下成功完成任务。此外,该策略甚至可以根据语言修正数据进行训练,并进一步提高其性能。
如图2所示,RT-H 有两个关键阶段:首先根据任务描述和视觉观察预测语言动作,然后根据预测的语言动作、具体任务、观察结果推断精确的行动。
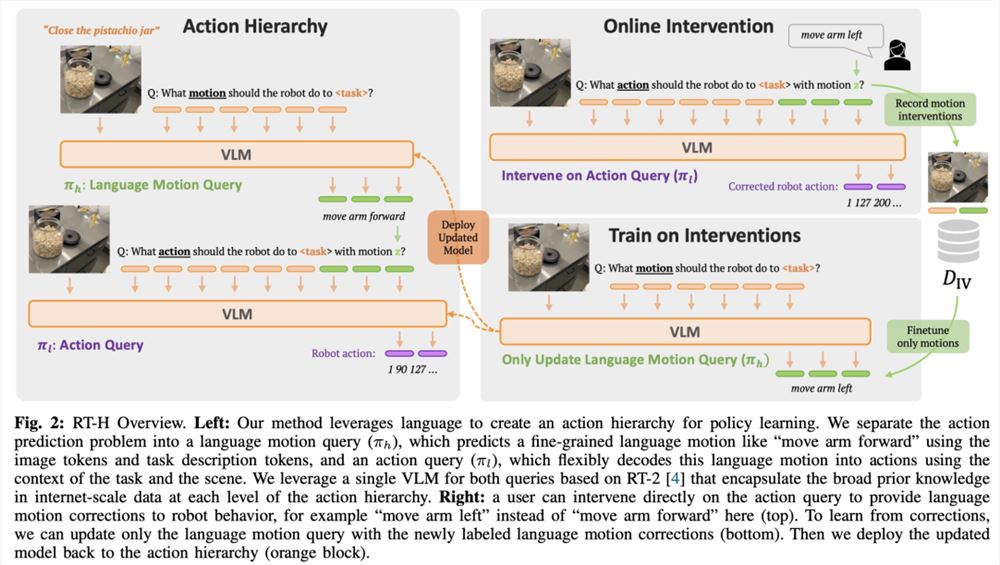
RT-H 使用 VLM 主干网络并遵循 RT-2的训练过程来进行实例化。与 RT-2类似,RT-H 通过协同训练利用了互联网规模数据中自然语言和图像处理方面的大量先验知识。为了将这些先验知识合并到行动层级的所有层次中,单个模型会同时学习语言动作和行动查询。
实验结果
为了全面评估 RT-H 的性能,研究团队设置了四个关键的实验问题:
Q1(性能):带有语言的行动层级是否可以提高多任务数据集上的策略性能?
Q2(情境性):RT-H 学得的语言动作是否与任务和场景情境相关?
Q3(纠正):在语言动作修正上进行训练比远程(teleoperated)修正更好吗?
Q4(概括):行动层级是否可以提高分布外设置的稳健性?
数据集方面,该研究采用一个大型多任务数据集,其中包含10万个具有随机对象姿态和背景的演示样本。该数据集结合了以下数据集:
Kitchen:RT-1和 RT-2使用的数据集,由70K 样本中的6个语义任务类别组成。
Diverse:一个由更复杂的任务组成的新数据集,具有超过24个语义任务类别,但只有30K 样本。
该研究将此组合数据集称为 Diverse Kitchen (D K) 数据集,并使用自动化程序对其进行语言动作标记。为了评估在完整 Diverse Kitchen 数据集上训练的 RT-H 的性能,该研究针对八项具体任务进行了评估,包括:
1)将碗直立放在柜台上
2)打开开心果罐
3)关闭开心果罐
4)将碗移离谷物分配器
5)将碗放在谷物分配器下方
6)将燕麦片放入碗中
7)从篮子里拿勺子
8)从分配器中拉出餐巾
选择这八个任务是因为它们需要复杂的动作序列和高精度。
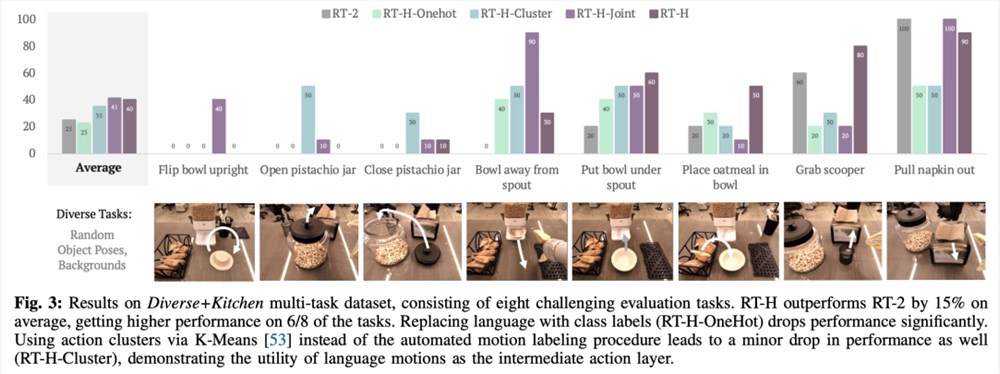
下表给出了在 Diverse Kitchen 数据集或 Kitchen 数据集上训练时 RT-H、RT-H-Joint 和 RT-2训练检查点的最小 MSE。RT-H 的 MSE 比 RT-2低大约20%,RTH-Joint 的 MSE 比 RT-2低5-10%,这表明行动层级有助于改进大型多任务数据集中的离线行动预测。RT-H (GT) 使用 ground truth MSE 指标,与端到端 MSE 的差距为40%,这说明正确标记的语言动作对于预测行动具有很高的信息价值。
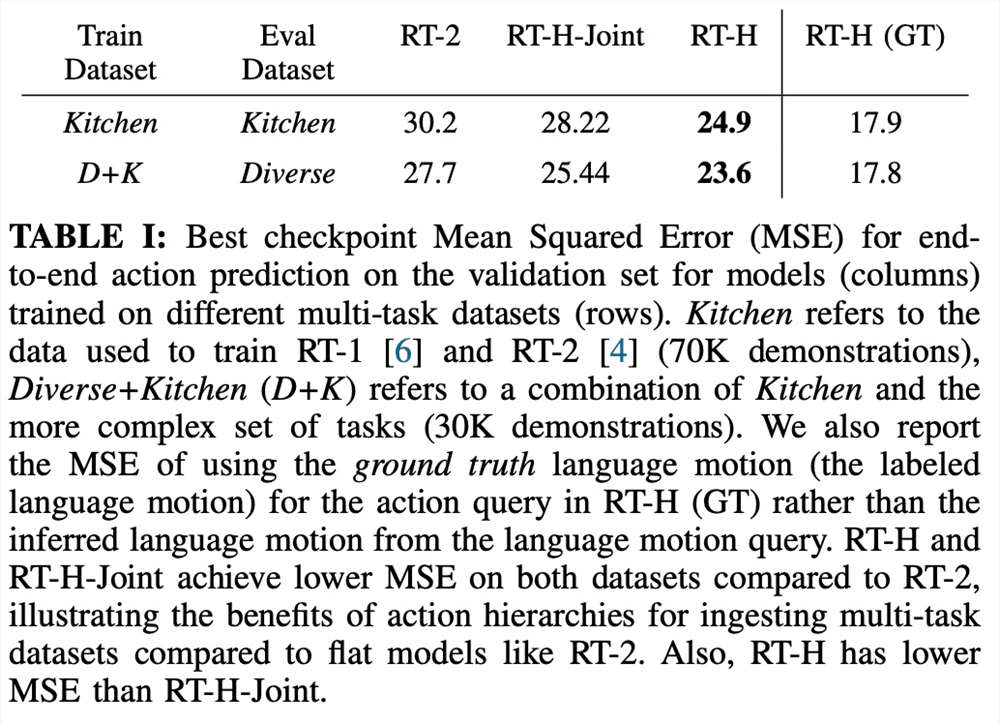
图4展示了几个从 RT-H 在线评估中获取的上下文动作示例。可以看到,相同的语言动作通常会导致完成任务的行动发生微妙的变化,同时仍尊重更高级别的语言动作。

如图5所示,研究团队通过在线干预 RT-H 中的语言动作来展示 RT-H 的灵活性。

该研究还用比较实验来分析修正的作用,结果如下图6所示:
如图7所示,RT-H 和 RT-H-Joint 对场景变化明显更加稳健:

实际上,看似不同的任务之间具备一些共享结构,例如这些任务中每一个都需要一些拾取行为来开始任务,并且通过学习跨不同任务的语言动作的共享结构,RT-H 可以完成拾取阶段而无需任何修正。

即使当 RT-H 不再能够泛化其语言动作预测时,语言动作修正通常也可以泛化,因此只需进行一些修正就可以成功完成任务。这表明语言动作在扩大新任务数据收集方面的潜力。
苹果确认漏洞阻止了儿童的屏幕时间限制
苹果确认存在漏洞,儿童能够绕过屏幕使用时间限制的设置。据《华尔街日报》报道,家长们发现通过家庭共享系统设置的一些屏幕使用时间限制无法正确保存数月。苹果本应在5月份解决这个问题,但该漏洞仍然存在。站长网2023-07-31 10:23:400000OpenAI推出DALL·E 3识别器、媒体管理器
5月8日,OpenAI在官网宣布,将推出面向其文生图模型DALL·E3的内容识别器,以及一个媒体管理器。随着ChatGPT、DALL·E3等生成式AI产品被大量应用在实际业务中,人们越来越难分辨AI和人类创建内容的区别,这个识别器可以帮助开发人员快速识别内容的真假。站长网2024-05-08 21:42:500002苹果国区教育优惠认证改用支付宝 此前仅需验证edu教育邮箱
近日,苹果对国区用户的教育优惠验证方式进行了重大调整。从过去仅需使用UNiDAYS验证edu教育邮箱,变更为须通过支付宝App进行学生身份验证。据悉,在以往,国区高校生只需拥有一个edu教育邮箱,通过UNiDAYS验证后,即可享受苹果的“教育优惠”价格购买相关设备,并获赠AirPods耳机等配件或礼金。站长网2023-10-12 10:07:010002京东PLUS会员政策调整 会员可不限额无限免邮
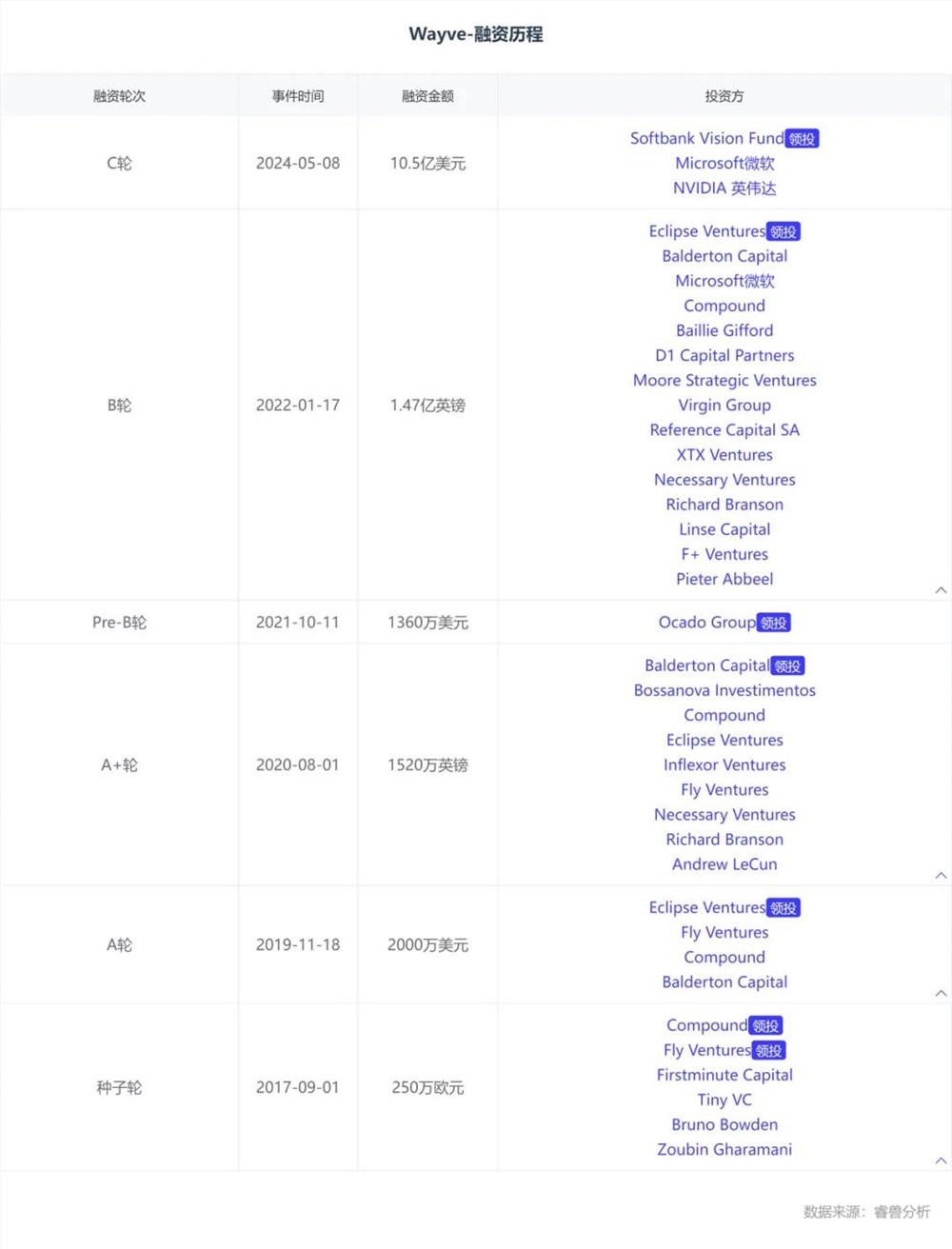
京东宣布,将从2023年8月23日开始,将全年360元运费券升级为无限免邮。PLUS会员还可以享受最高3%的购物返利以及免费体检等权益。无限免邮权益适用于京东自营商品,用户下单结算时会自动抵扣自营商品订单运费。站长网2023-08-23 18:08:40000276亿!孙正义再出手,领投比尔·盖茨狂赞的自动驾驶独角兽
今年自动驾驶赛道最大的一轮融资来了!日前,英国自动驾驶独角兽Wayve宣布获得10.5亿美元(约75.76亿元人民币)C轮投资,本轮融资由软银集团领投,新投资方英伟达和现有投资方微软跟投。同时,作为最终交易的一部分,软银将加入Wayve的董事会。据悉,该行业上一笔10亿美元级别融资发生在去年9月,当时同样是软银向无人驾驶卡车初创公司StackAV注资10亿美元。站长网2024-05-19 12:31:240000