美团、浙大等提出视觉任务统一架构VisionLLAMA
站长网2024-03-07 16:16:090阅
要点:
1. VisionLLaMA 是一种统一的视觉 transformer 架构,显著提升了图像生成、分类、语义分割和目标检测等多个主流视觉任务的性能。
2. VisionLLaMA 架构采用常规 transformer 和金字塔结构两种设计,有效减少了视觉和语言之间的架构差异,实现了更好的泛化能力和更快的收敛速度。
3. 通过在 ImageNet、ADE20K 和 COCO 数据集上的全监督和自监督训练实验,证明了 VisionLLaMA 在各种任务和数据集上都取得了显著的性能优势。
近期提出的 VisionLLaMA 架构在视觉任务领域取得了突破性进展。该架构致力于解决视觉和语言模态之间的架构差异,通过引入类似于 LLAMA 的统一接口,将视觉任务推向了一个新的高度。

项目地址:https://github.com/Meituan-AutoML/VisionLLaMA
VisionLLaMA 结合了常规 transformer 和金字塔结构的设计,有效减少了视觉和语言之间的差异,为各种任务提供了更一致的处理方式。
在全监督和自监督训练中,VisionLLaMA 在 ImageNet、ADE20K 和 COCO 数据集上都实现了显著的性能提升,尤其在目标检测和语义分割任务上表现突出。
此外,VisionLLaMA 的推广性得到了充分验证,不仅在常规任务中表现出色,还在图像生成领域取得了令人瞩目的成绩。
这些结果证明了 VisionLLaMA 的有效性和通用性,为视觉模型的发展提供了重要的参考和启示。综上所述,VisionLLaMA 架构的提出标志着视觉任务的新一轮技术革新,将为未来的研究和应用带来更多可能性和机遇。
0000
评论列表
共(0)条相关推荐
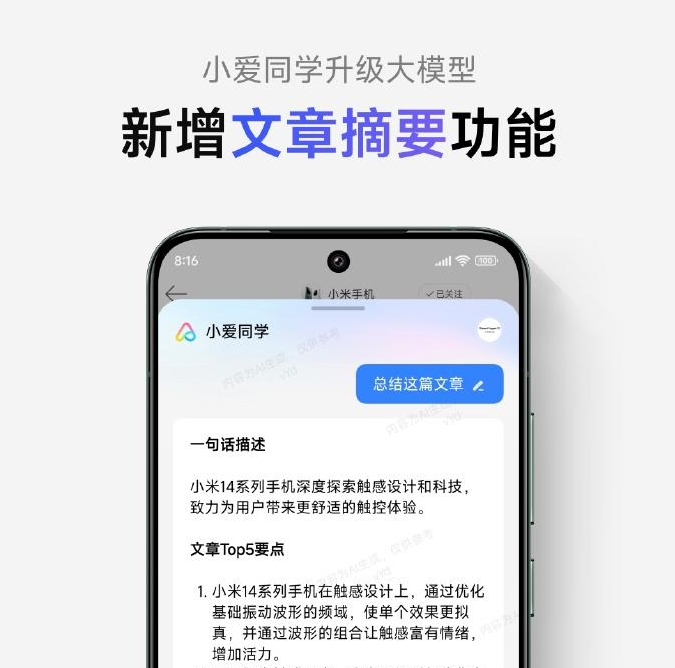
小米澎湃 OS 小爱同学大模型上线“文章摘要”功能
小米澎湃OS宣布,小爱同学的大模型已经上线了“文章摘要”功能。这项功能具有系统级入口,支持多种应用,可以帮助用户节省阅读时间。如果用户需要阅读英文文章,这项功能还可以直接生成中文摘要,使得阅读过程更加迅速。用户只需要对小爱同学说出“总结这篇文章”,就可以触发这个功能。站长网2023-11-23 08:49:430000Redmi K70 Pro、K70标准版今日开售 首销5分钟销量破60万台
今日10点,RedmiK70Pro和K70标准版正式开售。据小米官方公布数据,K70系列,首销5分钟销量突破60万台。RedmiK70Pro和K70标准版这两款手机都搭载了强大的硬件配置和小米澎湃OS操作系统。站长网2023-12-01 10:40:120000华为正式发布问界M9:售价46.98万元起 2月26日规模交付
华为今日下午举行了全场景发布会,问界M9豪华D级SUV正式发布。售价方面,问界M9增程Max版46.98万元,纯电Max版50.98万元,增程Ultra版52.98万元,纯电Ultra版56.98万元,将于2月26日规模交付。站长网2023-12-26 17:02:190001AIGC让个性化营销更卷了
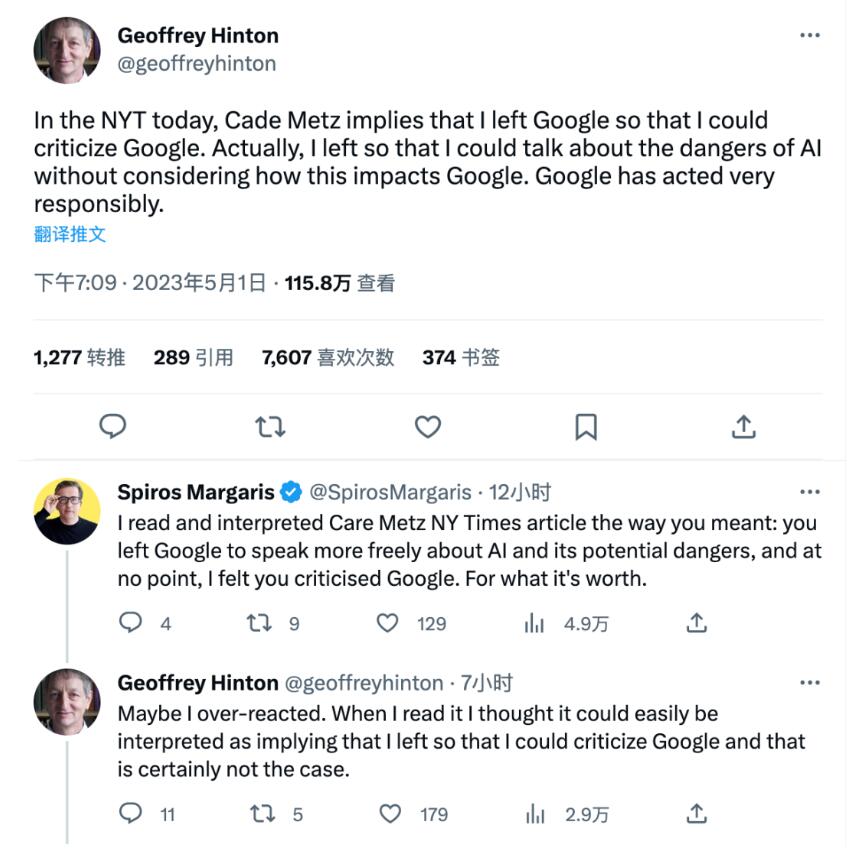
在AIGC正火热的当下,未来AIGC发展会带动营销走向何方或许无人知晓。但有一件能确定的事情是,未来的营销一定是个性化的天下。借着AIGC的东风,不同领域发生了一些变化:-在金融领域,AIGC可以用于金融市场的预测和分析,识别趋势和模式,并提供个性化的投资建议。-医疗保健领域,AIGC可以用于医学图像分析、疾病诊断,提供个性化的治疗方案。0000谷歌痛失AI大将!76岁图灵奖得主Hinton离职
“深度学习三巨头”之一、2018年图灵奖获得者杰弗里·辛顿(GeoffreyHinton)已离开谷歌,强调他离开是为了谈论人工智能的危险,而不会对谷歌造成影响。Hinton担心AI会制造虚假信息,随着AI技术的进步,它会编写并运行自己的代码,对人类生存构成更大的威胁。站长网2023-05-04 10:22:150000