英伟达发布Nemotron-4 15B: 8 万亿训练数据,性能超LLaMA-2
**划重点:**
1. 🌐 Nemotron-415B拥有150亿参数,基于8万亿文本标注数据预训练,在多领域测试中超越同类大小的开源模型,尤其在代码语言准确率上表现出色。
2. 🧠采用标准Transformer架构,结合自注意力、全局注意力和多头注意力等机制,以及旋转位置编码技术,提升模型表达和泛化能力。
3. 🌐 利用384个DGX H100节点,每节点搭载8个NVIDIA Hopper架构的H10080GB SXM5GPU,采用8路张量并行和数据并行的组合,以及分布式优化器进行分片。
英伟达最新推出的大型语言模型Nemotron-415B,以其卓越性能和创新架构引起广泛关注。该模型拥有150亿参数,基于庞大的8万亿文本标注数据进行了预训练。
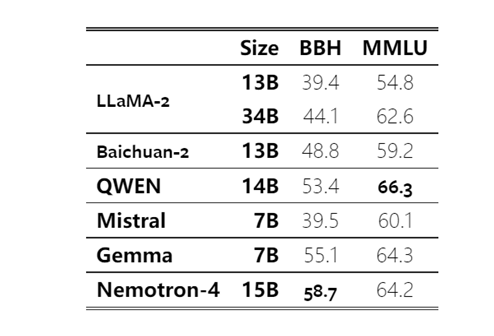
在多领域测试中,Nemotron-415B在7个领域中的4个表现优异,超越了同类大小的开源模型。特别值得注意的是,在代码语言方面,Nemotron-415B展现出更高的准确率,尤其在资源稀缺的编程语言上超过了Starcoder和Mistral7B等模型。
该模型采用了标准的Transformer架构,包括多头自注意力机制和前馈神经网络。其独特之处在于,Nemotron-415B结合了自注意力和全局注意力机制,以更好地理解输入序列内部的依赖关系和输入序列与输出序列之间的对应关系。多头注意力的引入进一步提高了模型的表达能力和泛化能力。
在训练过程中,研究人员充分利用了384个DGX H100节点,每个节点搭载8个基于NVIDIA Hopper架构的H10080GB SXM5GPU。通过8路张量并行和数据并行的组合,以及分布式优化器进行分片,成功完成了Nemotron-415B的训练。
Nemotron-415B在英语、数学推理、多语言分类和代码等多个测试任务中表现出色,不仅在性能上超越了LLaMA-234B和Mistral7B,在广泛的代码语言中也取得了更高的准确率。这一成就为大型语言模型的发展和应用提供了崭新的视角。
技术报告https://arxiv.org/abs/2402.16819
OpenAI CEO:马斯克教会我深度技术投资的重要性 但对生活在火星上没有兴趣
站长之家(ChinaZ.com)5月25日消息:OpenAI联合创始人兼首席执行官SamAltman当地时间周四在伦敦大学学院(UniversityCollegeLondon)拥有985个座位的地下礼堂发表演讲,排队等候进入礼堂的人们从门外一直排到楼梯上,延伸至街道,并蜿蜒延伸了整个街区的大部分距离。站长网2023-05-25 09:41:130000抖音卖服装,9个赚钱思路
各位村民好,我是村长。如果你只是单纯的想做抖音服装账号,但是直到目前又不知道该怎么做的话。这篇文章特别适合你看一看,我原本打算设置付费阅读的。后来还是打算免费分享出来,希望帮助一些人梳理一下思路,如果你觉得受到一点启发可以转发、赞赏。01服装是电商消费半边天关于服装这个市场一直可以做,因为只要是个人就得穿衣服。哪怕是老人,自己不买,总有子女会偶尔帮忙买一件。0000谷歌内部测试YouTube游戏产品,以进军游戏领域
据国外媒体报道,谷歌正在内部测试一款名为Playables的新YouTube产品,让用户在移动设备或桌面电脑上玩游戏。该产品将为YouTube在在线游戏领域拥有更大的影响力,而首席执行官NealMohan正在寻求新的增长领域。站长网2023-06-26 12:31:590000国产大模型 WAIC 竞技:大厂拼落地,中厂显焦虑
如果想要度量国产大模型大小厂商的实力,WAIC(世界人工智能大会)是一个不错的切口。众所周知,2023年是国产大模型元年,在去年的WAIC之后,腾讯发布混元大模型,字节跳动上线豆包APP,而后通过豆包大模型正式开启对外服务,年轻的月之暗面、MiniMax等创业公司形成了「五小虎」的格局,这让今年的WAIC有了更强的指向性:大模型选手们都已走向台前,给了AI行业更多的机会和答案。站长网2024-07-08 20:30:520001微软宣布 Sam Altman 和 Greg Brockman 加盟,领导新的高级 AI 研究团队
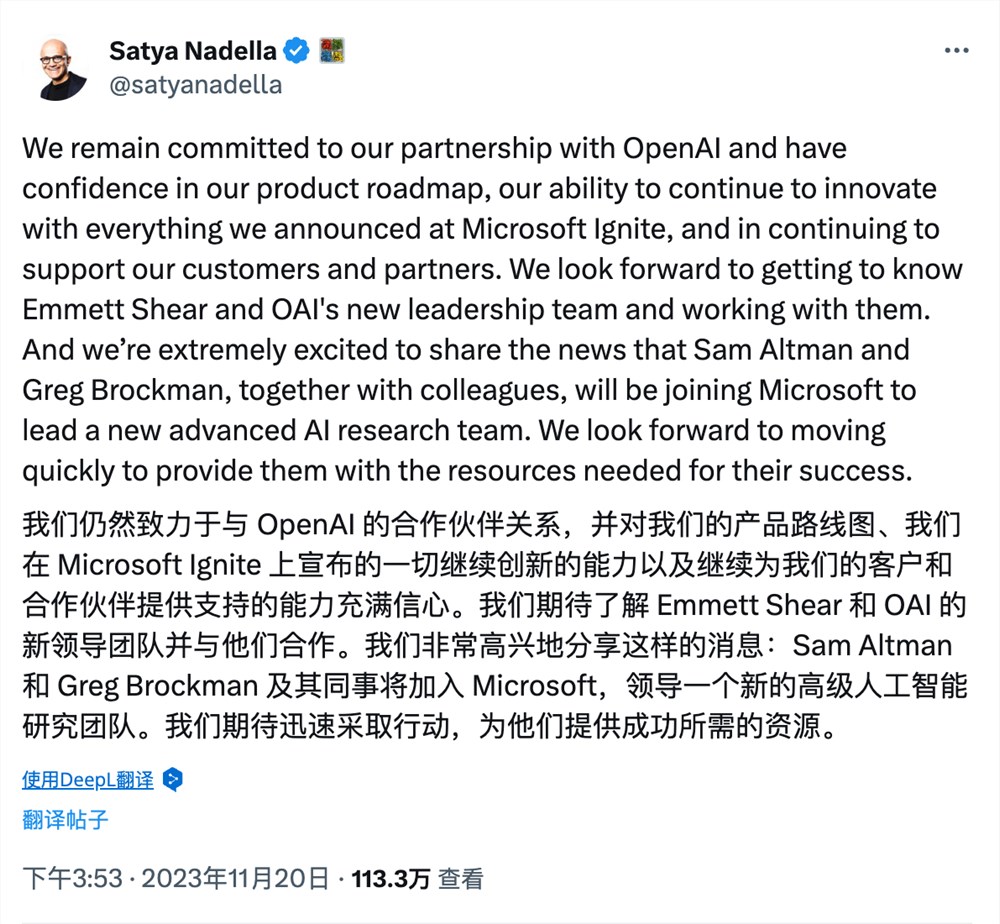
微软公司的首席执行官SatyaNadella在周一表示,SamAltman、GregBrockman以及他们的许多前OpenAI同事将加入这家软件巨头。这一宣布标志着在AI初创公司的高管突然离职后,经过三天激烈讨论高潮的句号。站长网2023-11-20 16:29:510002