炸场的Sora和冷静的同行
Sora面世半个多月,这个深水炸弹的后续效应依然强烈。
Open AI 发布的这个文生视频模型,紧跟着 Google 发布 Gemini1.5的消息,让支持百万级 token 的 Gemini 黯然失色,帮助OpenAI在科技圈成功「抢 C」,一跃成为视频模型届的 GPT3.5时刻。
毕竟,当Runway、Pika 等同类视频模型的创作上限还在10秒左右时,Sora 已经能够生成60秒的精致视频,可以一镜到底、切换视角,无论是背景还是主人公的表情,都拥有丰富的细节。关于Sora是否会杀死剪映的舆论甚嚣尘上。
目前 Sora 还没有对公众开放,但昨天,已经有创作者拿到了测试资格,并发布了自己尝试的三个视频。
在「测评电子产品的年轻人」这个视频中,光影细腻,人物和置景真实,美中不足的是他的右手有六根手指。此外,Sora 在理解物理时会遇到困难,特别是在腿部/行走方面。在 Sora 生成的小狗行走视频中,腿部经常交叉并合并在一起。
虽然 OpenAI 发布了 Sora 的技术报告,但其中并未涉及技术细节。
我们能知道的是,Sora 又是一次 OpenAI 式的典型胜利,是技术选型、训练数据、资源优化等各个环节的细节优化,组合成了一次效果超出预期的质变。就像 Sam Altman 之前解释为什么 GPT 会比其他的大模型更好,是因为 OpenAI 堆了「一百万个小技巧」。
去年年初,ChatGPT 发布后,海内外大厂争先恐后地发布文本大模型,热闹非凡,生怕落队;这次 Sora 发布后,只有海外版剪映、Stability AI 跟进发布了文生视频产品的测试版。
其他公司也许是暗中跟进,或是谨慎观望,除了网红李一舟蹭蹭热点,还没有谁站出来敢说,要做中国版Sora。
追,还是不追?
ChatGPT 发布后,大公司和初创企业纷纷加入百模大战;现在 Sora 已经发布半个多月了,此前的盛况没有再次出现。
一周之后,Stability AI 开放了Stable Video的公测,但或许是服务器爆满的缘故,功能不够稳定。生成的视频最值得称道的是清晰度,但仍然没有大幅度的视角切换,画面主体也没有太多动作,只有背景动了起来,给人的感觉仍然是「会动的图片」。
字节剪映海外版也上线了文生视频的功能,同样反响不佳,主要是因为等待的时间过长。网友测试发现,一个视频的生成要等待1800分钟。
有人工智能算法工程师分析,同等参数的视频模型,比大语言模型所需要的算力要多几十倍。业界流传,Sora 的参数规模在10B 到30B 之间,其所需的算力或许与千亿级的大语言模型差不多。
有趣的是,腾讯和阿里巴巴虽然没有跟进视频模型的发布,却纷纷第一时间在自己的技术账号上发布了对 Sora 的技术拆解;其中,阿里巴巴达摩院所发布的文章题目叫做《复刻 Sora 有多难?》,并在文末表示,「我们期待视频生成领域的 LLaMa ,以及更加普惠的开源视频生成技术。」

AI 初创企业 Hugging Face 认为,视频模型的三大挑战是算力、数据、指令模糊性。要想做到物体和空间的一致性,往往伴随着高昂的计算成本;高质量的视觉数据集也比文本的更为稀缺。此外,生产让模型更容易理解视频的 Prompt,会比语言模型、文生图模型难度更大。
此外,Sora 是一个凭借直觉和概率驱动的模型,而不是靠精确计算的公式驱动的模型。有人总结道,「Sora 可以像一个普通人一样,通过直觉去理解物理世界,也能解决很多问题,但它没有办法像物理学家一样造出火箭这种东西。」
无论如何,Sora 跟 GPT3.5一样,验证了技术方向的可行性,视频模型的性能未来会随着参数量、数据大小和计算量的增加而提高。
又一次降维打击?
硅谷投资机构 a16z 统计,截止去年年底,市面上共有21个公开的视频模型,其中包括 Runway、Pika、Stable Video Diffusion 等等。
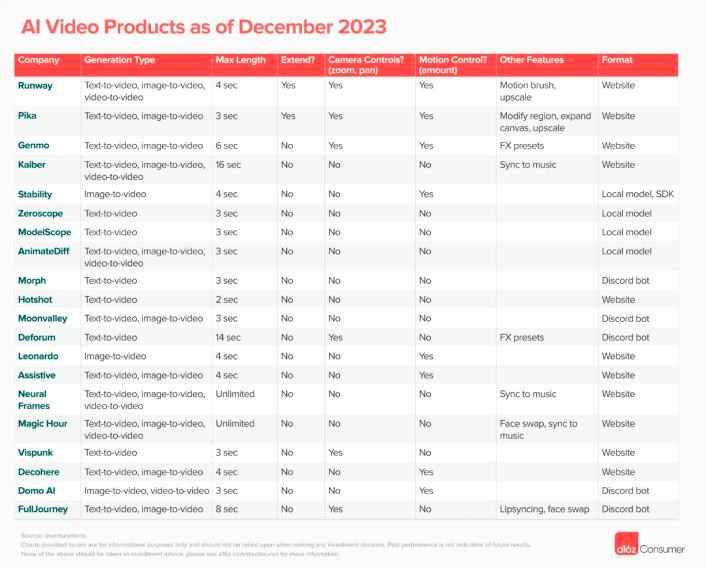
然而,第一个出圈的还是 Sora,核心依然是它远超预期的效果。以往几秒钟的 AI 视频,给人的感觉还是「会动的图片」,而 Sora 则展现了对真实世界的理解力和还原力,还有对虚拟场景的充沛想象力。
Sora 官网发布的几十个视频 Demo 中,有在东京街头散步的女人、在咖啡杯里航行的海盗船、在雪原上走过的猛犸、无人机视角拍摄的海浪拍打峭壁、华丽的纸艺海底世界、维多利亚冠鸽的微距特写,其视频主体和环境的一致性令人震撼。咖啡杯里航行的海盗船这个 Demo 里,水面的波纹、船的运动轨迹,很好地遵循了现实世界的物理规律。
阿里巴巴达摩院的分析认为,Sora 的智能涌现,体现在它的三位一致性、长距离连贯性和物体持久性、与世界互动的能力、对数字世界的模拟。
虽然 Sora 对复杂的物理预测还显得力不从心——比如,一个人咬了一口饼干,但饼干上并没有出现咬痕,但许多从业者认为,这是 AI 真正理解世界的开端,随着模型能力的持续提升,它对物理世界的理解和还原会更加准确。
此外,OpenAI 不仅公布了 Demo 视频,同时公布了每一个 Sora 生成视频的指令,方便大家尝试其他产品后,对比效果。
尽管外界担心其他文生视频初创企业的命运,但创始人们表现出的兴奋却远远大过恐惧。
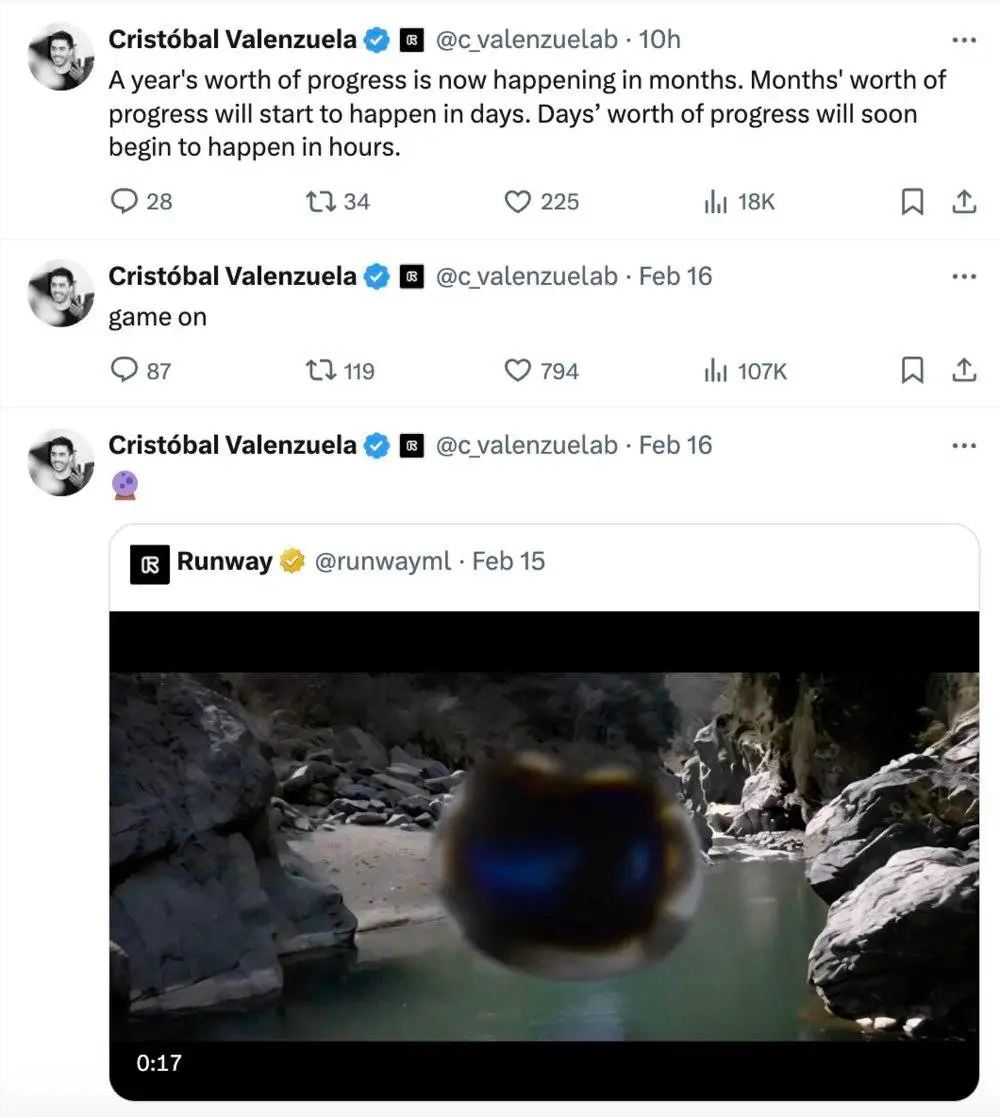
Runway CEO Cristóbal 感慨技术进步的速度,过去需要以年计算的技术进步,现在压缩到了月的维度,他预测技术将会更快地进化,每天、甚至每个小时,都可以涌现出新的技术实现。Pika 创始人郭文景也在媒体采访中表示,「(Sora)是一个振奋人心的消息,我们准备直接冲,将直接对标Sora。」
去年8月,OpenAI 对外披露了首次收购行为。
被收购公司 Global Illumination,开发了一款名为 Biomes 的开源大型多人在线沙盒游戏,类似于浏览器上运行的《我的世界》。当时就有人指出,借助开放式游戏中玩家的交互,OpenAI 通过这次收购,能为 AGI 构建真正的数据集;也有人猜测,OpenAI 将会推出游戏或视频模型产品。
从 Sora 的效果看,或许这次收购的确对 Sora 的训练数据优化有一些帮助。
世界模拟器?
「Sora 是能够理解和模拟现实世界的模型的基础,我们相信这一功能将成为实现 AGI 的重要里程碑。」OpenAI 在技术报告的最后写道。
ChatGPT 是思维世界的模拟器,Sora 是物理世界的模拟器,出门问问 CEO 李志飞评论,「OpenAI 的科学家们果然一直有着创世的冲动。」

有技术人员猜测,Sora之所以具备强大的能力,得益于模型和数据。
首先,与 Runway、Pika 的技术路线不同,Sora 使用了基于 Transformer 的扩散模型(Diffusion Model),可以通过自注意力机制(Self-attention)来学习视频数据中各个元素块之间的关系,并模拟数据的扩散过程,生成高质量的视频输出。
其次,Sora 能将不同类型的视觉数据,转化成统一的视觉补丁(Patch)。Patch 之于 Sora,就像 token 之于 ChatGPT。ChatGPT 把各种语言、编程代码都切分为 token,Sora 把图片、视频都切割为 patch。
OpenAI 认为,将视觉数据统一处理,将带来两点好处:首先是采样的灵活性,通过统一的数据表示,Sora 可以灵活处理不同宽高比的视频内容。其次是更好的构图效果。在原始宽高比的视觉数据上进行训练,Sora 可以更好地学习和理解构图,使得生成的内容更符合人类的视觉习惯和审美标准。
如同 ChatGPT 在专业领域的能力,还比不过详细定义规则的小模型一样,Sora 虽然对物理世界有一定理解,并拥有更强大的泛化能力,但它与此前的物理仿真模拟相比,预测价值仍然有限。
比如,物理仿真模型可以预测汽车在相撞时的反弹效果和形变,但 Sora 无法发挥这样的作用。OpenAI 官网发布的 Demo 也表现出,Sora 无法很好地模拟玻璃杯破碎时的动态,混淆了玻璃破碎和液体溢出的顺序,倒下的玻璃杯甚至与桌面融为一体。
英伟达的研究人员Jim Fan认为,这有两种可能的解释:一是模型之所以犯这样的错误,是因为它根本不学习物理,只是简单地缝合像素;二是模型实现了一个内部的物理引擎,但这个引擎还不够好,就像 Unreal Engine v1在流体和可变形物体等物理模拟方面比 v5要差得多,渲染效果也差得多,并且不符合物理规律。他本人更倾向于第二种解释。

但模型能力的提升是可预见的,因为人类生产视觉数据的速度前所未有地加速了:全世界遍布摄像头,每人每天都在用智能手机采集这个世界。这将成为模型理解世界的通路。此外,UE5也可以模拟多角度的高清视频,让模拟出来的视觉数据更加优质。
从 Sora 中我们不难看出,头部玩家 OpenAI 的思路是「集中力量办大事」:专注提高模型的能力,只进行轻度的产品化。毕竟,能生产60s 视频的模型,要比添加了很多细碎功能、复杂按钮的视频产品震撼多了。此外,谁也无法预测模型智能程度的提升曲线,产品设计的节奏很可能追不上模型进步的速度。
当下对于大模型公司来说,模型能力才是最好的增长手段。不仅SLG(Sale-lead growth)显得过于原始,甚至PLG(Product-lead growth)也有些过时,我们正在迎来一个MLG(Model-lead growth)的时代。
1小时700元、年入7000万 谁在靠年轻人的焦虑赚钱
在成为疗愈师的三年时间里,来找刘倩咨询的客户,面临着晋升失败、被裁员优化、失恋、亲子关系紧张等各种职场、生活问题。年轻人无法自洽的情绪,在疗愈师的帮助下得到缓解,也带火了从冥想、正念,到颂钵音疗、芳疗、绘画疗愈,再到禅修、旅修等一系列新兴疗愈经济。一时间,关注人的身体、心理、精神健康与个人成长的身心灵产业再度受到关注。但由于尚且缺乏平台和规范化监管,眼下的疗愈行业火爆与野蛮生长并存。站长网2023-10-22 09:41:590001小米汽车 SU7 宣布 3 月 28 日正式发布 售价即将公布
小米创始人雷军宣布,小米SU7将在3月28日正式发布。雷军表示,如果你想拥有一台车,要有最先进的智能科技,还要有出色的驾驶质感,小米SU7将会是首选。站长网2024-03-12 09:28:0400009块9的瑞幸,到底赚了谁的钱?
9.9的瑞幸和8.8的库迪之间的价格战已经打了挺久了,进度条还在前半段。最希望这场价格战早日结束的可能不是库迪,而是瑞幸伙伴们。瑞幸对外宣称有信心打持久价格战,内部已经将价格战的时间定为2-3年,至少也会持续到2024年底。“因为每杯都赚钱。”瑞幸在价格战里疯狂撒币,用户也觉得不薅资本家羊毛那不傻逼吗,打折的咖啡不喝就亏。站长网2023-07-10 18:31:510001小i机器人起诉苹果索赔100亿新进展 将在上海高院开庭
站长之家(ChinaZ.com)4月24日消息:天眼查数据显示,上海智臻智能网络科技股份有限公司(小i机器人)将与苹果公司、苹果电脑贸易(上海)有限公司、苹果贸易(上海)有限公司等被告展开侵害发明专利权的诉讼,并公布了新的开庭公告。原告为上海智臻智能网络科技股份有限公司,案件将于5月5日在上海市高级人民法院开庭。智臻智能表示,此次诉讼将向全球证明中国人工智能企业的实力。站长网2023-04-24 11:44:240001原钉钉副总裁成立Al应用开发平台BetterYeah AI 已获亿元融资
据36氪消息,斑头雁智能科技是一家人工智能公司,由原钉钉副总裁张毅(花名陶钧)创立。该公司最近完成了近千万美元的A轮融资,用于开发企业级AIAgent产品BetterYeahAI。斑头雁智能科技已经完成了2轮融资,累计融资额达到1亿元人民币。图源备注:图片由AI生成,图片授权服务商Midjourney0002