最长处理2小时,开源视频字幕模型Video ReCap
随着抖音、快手等平台的火爆出圈,越来越多的用户开始制作大量的短视频内容。但对这些视频进行有效的理解和分析仍面临一些困难。尤其是视频时长超过几分钟、甚至几小时,传统的视频字幕生成技术往往无法满足需求。
因此,北卡罗来纳大学和Meta AI的研究人员开源了,视频字幕模型Video ReCap。这是一种递归视频字幕生成模型,能够处理从1秒到2小时的视频,并在多个层级上输出视频字幕。
此外,研究人员通过在Ego4D上增加8,267个手动收集的长视频摘要,引入了一个层次化视频字幕数据集Ego4D-HCap,并使用该数据集对Video ReCap进行了综合评估。
结果显示,Video ReCap在短视频片段字幕、中等长度段描述和长视频摘要的测试指标均明显超过多个强大基准模型。通过该模型生成的分层视频字幕,也能显著提升基于EgoSchema数据集的长视频问答效果。
开源地址:https://github.com/md-mohaiminul/VideoRecap?tab=readme-ov-file
论文地址:https://arxiv.org/abs/2402.13250

Video ReCap模型介绍
Video ReCap的核心技术是使用了递归视频语言架构,主要通过递归处理机制,使模型能够在不同的时间长度和抽象层级上理解视频,从而生成精确且层次丰富的视频描述字幕。主要由3大模块组成。
1)视频编码器:Video ReCap使用了一个预训练的视频编码器,从长视频中提取特征。对于短视频片段,编码器则输出密集的时空特征。
这允许模型捕获细粒度的详细信息,对于更高层级的字幕,使用全局特征(如CLS特征),以降低计算成本并捕获长视频输入的全局属性。
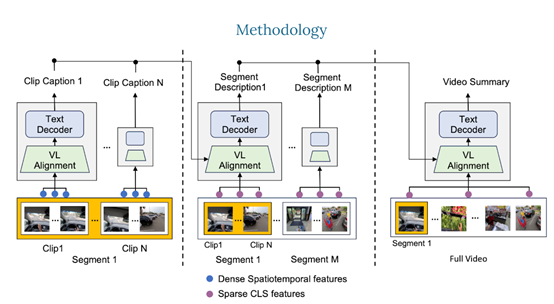
2)视频-语言对齐:该模块可以将视频和文本特征映射到联合特征空间,以便递归文本解码器可以联合处理两者。
具体来说,使用了一个预训练的语言模型,通过在每个转换器块内注入可训练的交叉注意力层,从视频特征中学习固定数量的视频嵌入。
然后,从属于特定分层的字幕中学习文本嵌入。最后,连接视频和文本嵌入以获得联合嵌入,并交给后续的递归文本解码器使用。
3)递归文本解码器:该模块主要用于处理短、中、长三种视频的字幕,所以,采用了一种分层的生成策略。首先,使用从短视频剪辑中提取的特征生成短剪辑级别的字幕。这些短剪辑级别的字幕描述了视频中的原子动作和低级视觉元素,例如,对象、场景和原子动作等。

然后,使用稀疏采样的视频特征和上一层级别生成的字幕作为输入,生成当前层级别的视频字幕。这种递归设计可以有效地利用不同视频层次之间的协同作用,能高效地生成最多2小时的长视频字幕。
Video ReCap实验数据
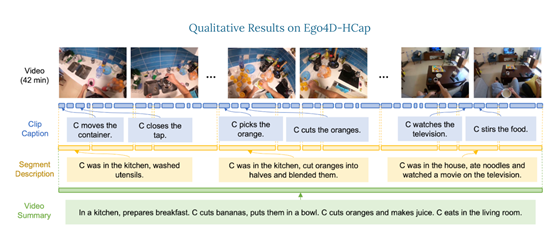
为了评估Video ReCap模型,研究人员推出了一个新的分层视频字幕数据集Ego4D-HCap。该数据集是基于目前最大的公开第一人称视频数据集之一Ego4D。
Ego4D-HCap主要包含三个层次的字幕:短剪辑字幕、几分钟长的段描述和长段视频摘要,用于验证分层视频字幕任务的有效性。
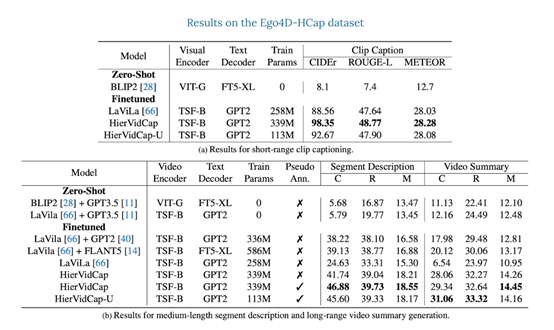
结果显示,在所有三个时间层级,Video ReCap模型都大幅度优于之前的强大的视频字幕基准模型。此外,还发现递归架构对于生成段描述和视频摘要非常重要。
例如,不带递归输入的模型在段描述生成方面CIDEr性能下降1.57%,而在长时间视频摘要生成方面下降了2.42%。
研究人员还在最近推出的长序视频问答基准EgoSchema上验证了该模型。结果显示,Video ReCap生成的分层视频字幕可以将文本问答模型的性能提高4.2%,并以50.23%的整体准确率刷新了记录,比之前的最佳方法提高了18.13%。
支付宝与华为合作 启动鸿蒙原生应用开发
支付宝与华为终端宣布合作,启动鸿蒙原生应用开发,进一步完善鸿蒙生态布局。双方合作将满足用户在不同终端和场景下的智慧生活服务需求。据悉,支付宝作为数字支付和数字互联开放平台,已服务8000万商家和10亿消费者。华为表示,鸿蒙原生应用的开发体现了鸿蒙原生应用的新发展。双方将在数字化服务等领域拓展合作,共建新生态,服务国内用户和市场。0000滴滴里程会员全新升级 免费享超10项专属权益
滴滴近期对其里程会员权益进行了全新升级,以提供更丰富的实惠和更优质的服务体验。升级后的会员体系新增了免单券、半价券等乘车优惠券,并增加了包括快速应答、无车赔、极速赔付在内的超过10项乘车权益的免费使用次数。此外,用户通过加入滴滴家庭账户,可以与亲友共享和积累打车里程值,更快提升会员等级,享受更多的乘车权益。站长网2024-08-13 01:58:340000大厂AI人,奔向香港
“现在在香港,遍地都是AI创业的前大厂人,百万融资不难拿到。”30岁的大厂P7黄全,刚刚搬离西二旗的工位,就在2024年1月前往香港尝试AI创业,这是他寻找出路的首选。香港对科创类项目的鼎力支持,让他迎来了惊喜的开局。两大科创集群——香港科技园和香港数码港,都对科创企业有不同的培育计划。以香港科技园IDEATION项目的计划为例,前期可提供10万港币的几乎无条件的funding。0000被“薅羊毛”的瑞幸,一季度赚了5.6亿
5月1日,瑞幸咖啡(下简称瑞幸)发出了了一份堪称“狂飙”的一季度财报。财报显示,今年一季度瑞幸营收达到44.37亿元,同比增长84.5%;美国会计准则(GAAP)下净利润5.65亿,同比增长超27倍。瑞幸一边飞速赚钱,一边飞速开店。一季度瑞幸净新增门店1137家,总门店数量环比增长13.8%,简单换算一下几乎是两小时就开一家新店。站长网2023-05-10 13:52:350000突破性文本生成视频方法LVD,利用LLM创建动态场景布局
文章概要:1.困扰文本提示生成视频的挑战:研究团队引入LLM-GroundedVideoDiffusion(LVD)方法,以解决生成复杂时空动态视频的问题。2.LVD采用大型语言模型(LLMs)来创建动态场景布局(DSLs),作为视频生成的蓝图,同时发现LLMs具有惊人的能力来捕捉时空关系和复杂动态。站长网2023-10-10 16:30:020000










