阿里通义实验室开源多模态说话人项目3D-Speaker
站长网2024-02-27 17:53:322阅
3D-Speaker 是通义实验室语音团队贡献的一个开源项目,结合了声学、语义、视觉三维模态信息来解决说话人任务。
项目涵盖了说话人日志、说话人识别和语种识别任务,提供了工业级模型、训练代码和推理代码。同时还开源了研究数据集3D-Speaker dataset,包含了多设备、多距离和多方言的音频数据和文本,适用于高挑战性的语音研究。
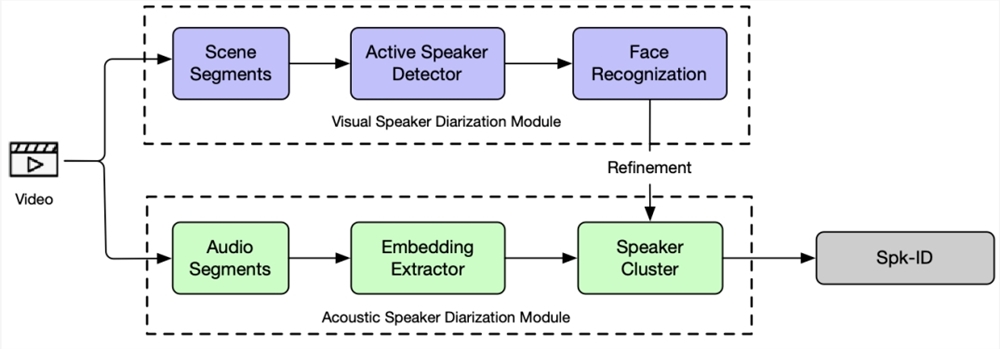
1. 结合视觉信息的说话人日志技术:
- 在复杂声学环境中,引入视觉信息可以提升说话人识别能力。
- 系统包括声学和视觉模态识别路线,通过联合多模态聚类得到最终识别结果。
2. 结合语义信息的说话人日志技术:
- 将说话人日志任务从传统的音频切割转为对文本内容进行说话人区分。
- 提出了对话预测和说话人转换预测模块,基于 Bert 模型,用于提取语义中说话人信息。
3. 基于经典声学信息的说话人和语种识别:
- 包含全监督和自监督说话人识别模型,支持多种数据增强、多模型训练和多损失函数。
- 提供一键式训练推理,支持多种经典模型,并提供有效的学习率调节方案和 margin 变换值。
3D-Speaker 项目在说话人任务中探索了多模态信息的结合应用,提供了一系列有效的技术解决方案和开源资源,为语音研究领域的发展做出了贡献。
开源代码链接:
https://github.com/alibaba-damo-academy/3D-Speaker/blob/main/egs/3dspeaker/speaker-diarization/run_video.sh
0002
评论列表
共(0)条相关推荐
在生成式AI面前,创作者能否保护自己的作品免受侵害?
站长之家(ChinaZ.com)引言:随着生成式人工智能艺术的风靡,一些人怀疑它是否应该被视为艺术。这项技术仍在不断发展中,如Midjourney和StableDiffusion等生成式人工智能工具正在产生越来越令人信服的视觉效果。然而,这些工具是依靠庞大的创意作品数据库来生成内容。对于创作者这来说,可能想知道是否有一种方法可以保护您的工作免受人工智能工具的影响,答案是:这很复杂。站长网2023-07-26 16:43:560000公众号标题可以修改了!还有这8个变化。
各位村民好,我是村长。对于所有公众号的创作来说,这是个很好的消息!01公众号标题修改公众号终于支持修改标题了,但依然是有克制性的。规则:标题字词3个字以内容的修改,包括删除、替换。这对于许多内容创作者来说,以前不小心打错字,漏字的情况,不至于删除全文。02公众号正文图片修改除了标题,公众号文章中的图片也支持修改了。规则:点击图片可替换或删除图片,支持3张图片内的修改。站长网2024-07-11 08:56:400000Stack Overflow 推出 OverflowAI,实现开发者社区和人工智能的整合
StackOverflow是开发者寻求答案和知识的知名平台,宣布了新的路线图,迈出了重要的一步,开创了以生成式AI集成为标志的新时代。StackOverflow在开发者社区和人工智能之间进行了整合,推出了OverflowAI。OverflowAI引入了语义搜索,通过矢量数据库提供智能的响应,为开发者提供准确的问题解决方案。站长网2023-07-31 10:06:390002AI服务器不足一年价格涨近20倍 从8万涨到160万元每台
据《证券时报》报道,受到AI大型模型的发展热度影响,市场对算力的需求量飞速增长。作为算力基础架构之一的AI服务器,拥有图形渲染和大规模数据并行运算等优势,能够快速、准确地处理大量数据,其市场价值愈加凸显。站长网2023-05-18 11:01:560000快抖微,抢夺“霸总”
“两天花了300多元、一晚上看了30多个30秒广告”,近期,某博主吐槽自己被短剧“骗”了。像这位博主一样为短剧上头的观众不少,在他们的助力下,今年9月以来,小程序短剧发布的“战报”频频刷爆朋友圈,《无双》8天充值金额破亿、《哎呀!皇后娘娘来打工》上线24小时充值金额破1200万元......0000