在生成式AI面前,创作者能否保护自己的作品免受侵害?
站长之家(ChinaZ.com) 引言:随着生成式人工智能艺术的风靡,一些人怀疑它是否应该被视为艺术。这项技术仍在不断发展中,如Midjourney 和 Stable Diffusion 等生成式人工智能工具正在产生越来越令人信服的视觉效果。然而,这些工具是依靠庞大的创意作品数据库来生成内容。对于创作者这来说,可能想知道是否有一种方法可以保护您的工作免受人工智能工具的影响,答案是:这很复杂。

生成式人工智能工具使用机器学习模型,这些模型经过训练可以使用大型数据集执行操作。用于训练的数据集包括数十亿个图像和文本对——从毕加索等传奇艺术家的作品到专业和业余创意人员的作品。
人工智能艺术生成器使用这些媒体文本配对来生成视觉内容以响应用户文本提示。基本上,他们使用现有艺术家的作品,并将模式与文本配对(社交帖子、标题、替代文本等)相匹配,以便用户可以根据“文森特·梵高风格的繁星夜空”等提示生成新的视觉效果。
为什么艺术家感到不安?
艺术创作者最不满的是生成式人工智能工具未经许可使用他们的作品。
生成式人工智能是将来自多件艺术品的数据组合起来,并将其拼接在一起,以生成与用户提示相匹配的东西。
生成式人工智能工具正侵害艺术创作者权益,大多数人工智能工具在没有征求许可、提供任何补偿、甚至不承认原始创造者的情况下就完成了所有这些工作。
能阻止生成式人工智能工具访问人类艺术品吗?
不幸的是,阻止人工智能工具访问任何内容的唯一方法是不在网上发布任何内容。这听起来可能有些极端,但这就是现实。当然,可以使用网站上的 robots.txt 文件来阻止 AI 工具抓取网站内容,或者通过选择退出训练数据集来保护您的图像免受 AI 影响,但这些方法有一些限制。
首先,robots.txt 文件中的命令是建议性的,这意味着网站没有遵守法律义务。其次,必须阻止像谷歌这样的公司抓取网站,而这又不利于SEO。最后,robots.txt 文件仅让能(有限)控制对网站的访问,它不会保护在其他地方发布的内容:社交媒体、云服务等。
谷歌的隐私政策可能意味着它使用所有在线内容来训练其人工智能算法
2023年7月,谷歌更新了隐私政策,表示将使用在线内容来训练其 AI 系统,包括 Brad、谷歌翻译等。谷歌使用“可公开访问的来源”这一措辞。以下引用在更新后引起了一些警钟:
“例如,我们可能会收集在线公开或从其他公共来源获取的信息,以帮助训练 Google 的 AI 模型并构建产品和功能,例如 Google Translate、Bard 和 Cloud AI 功能。” –谷歌隐私政策
换句话说,谷歌现在表示,您在网上发布的任何内容都可以获取。至少,谷歌通过突出显示最新的变化,可以轻松比较其隐私政策的更新:
这个措辞的变化相当微妙,但含义却很重大。此前,谷歌语言模型的主要功能是解释搜索查询并将文本翻译成其他语言。
现在,该公司表示可能会使用所有可公开访问的资源来训练其全套人工智能模型。这包括其生成式人工智能系统 Bard,并扩展到语言模型之外,包括所有谷歌的人工智能工具/功能——最明显的例子是图像生成。
社交网络可以使用平台上发布的任何内容
Meta 还可以不受限制地访问 Facebook、Instagram 和 Threads 上发布的所有内容。如果您阅读了条款和条件,这是社交平台的标准做法。一旦将任何内容上传到社交网络,他们就有权以任何他们希望的方式使用和重复使用它。
许多社交用户发现公司未经许可在广告中使用他们的图像,包括创意。不幸的是,如果该公司恰好是用户上传图像的社交网络、该网络的母公司或同一母公司拥有的另一个品牌,那同样能获取数据。
对于大多数人来说,像 Instagram 这样的平台使用他们的一张图片进行广告活动的机会非常低。然而,Meta 几乎肯定会使用您的图像、视频和帖子来训练其人工智能算法。
Adobe 等服务可能会访问并使用用户作品来训练他们的算法
2023年1月,Adobe 因更新其条款和条件而引起热议。该语言似乎表明 Adobe 可以使用摄影师上传到其云服务的图像来训练其人工智能算法。
具体措辞如下:
“Adobe 可能会使用机器学习(例如模式识别)等技术来分析您的内容,以开发和改进我们的产品和服务。”
更糟糕的是,Adobe 自动选择用户加入该内容分析系统,这意味着他们必须在帐户设置中手动将其关闭。几周后,Adobe 表示不会使用任何客户数据来训练其生成式人工智能工具。
不管怎样,如果Adobe 想使用客户数据来训练其人工智能系统,那么除了抵制之外,任何人都无能为力。与此同时,Adobe 正在从某处获取生成填充等工具的数据,因此它以某种方式使用艺术家的作品。
科技公司几乎可以轻松地访问用户的数据
就目前情况而言,谷歌和 Meta 等科技巨头几乎可以轻松地访问艺术创作者的数据。
欧盟直到2018年才实施其GDPR 隐私准则,但在保护用户数据方面几乎没有采取任何措施。
生成式人工智能是一个新的雷区,几乎没有任何法规来限制科技公司在这一领域的行动。目前,像 Google 和 OpenAI 这样的公司几乎可以用用户的数据做任何他们想做的事情,而且这种情况不会很快改变。
最终,需要通过诉讼和监管来保护艺术家免受人工智能的侵害
在生成式人工智能及其对用户数据的访问受到监管之前,艺术创作者几乎无力阻止这项技术。最有可能的情况是版权法的变化,或者可能是与创意所有权相关的新数据保护。无论哪种情况,新法规的出台和执行都需要很长时间。
对于创意人士来说,关于AI版权诉讼案件不断增多,这可能会加快法律反应的速度。与此同时,人工智能艺术一代所面临的伦理问题将持续存在。
IBM 与 NASA 合作开发多模态基础模型,用于天气预测
划重点:-IBM与NASA等机构合作,致力于开发地理空间AI以应对气候变化。-合作旨在开发一个多模态基础模型,用于天气预测、分析热岛效应、绘制造林地图和预测极端天气事件的影响。-IBM希望通过开源发布这个模型,促进全球范围内的研究和科学发现。站长网2023-11-30 15:35:430000前 OpenAI 首席技术官 Mira Murati 将为新的 AI 初创公司筹集资金
站长之家(ChinaZ.com)10月20日消息:据知情人士透露,前OpenAI首席技术官MiraMurati正在为她的新AI创业公司向风险投资家筹集资金。消息人士表示,这家新公司计划基于自主研发的专有模型构建AI产品。目前尚不清楚Murati是否会出任新公司的首席执行官。由于涉及私人事务,一位不愿透露姓名的消息人士称。Murati的代表对此拒绝发表评论。站长网2024-10-20 10:00:210000OpenAI 增强 Assistants API 引入视觉能力支持多种图像格式
OpenAI最近宣布,其AssistantsAPI现在支持视觉能力,这标志着该公司在多模态AI领域的进一步扩展。这项更新使得API能够处理和理解图像内容,为用户提供更加丰富的交互体验。AssistantsAPI的视觉能力特点包括:支持多种图像格式:用户现在可以提交PNG、JPG、GIF和WebP格式的图像,以供API进行分析和理解。站长网2024-05-10 17:23:090000AMD收购人工智能软件公司 Nod.ai
AMD宣布签署协议收购开源人工智能(AI)软件公司Nod.ai,以扩展公司的开源AI软件能力。Nod.ai的加入将为AMD带来一个经验丰富的团队,该团队开发了领先行业的软件技术,可加速部署针对AMDInstinct™数据中心加速器、Ryzen™AI处理器、EPYC™处理器、Versal™SoC和Radeon™GPU进行优化的AI解决方案。站长网2023-10-11 18:41:060001谷歌推“Circle to Search”AI搜索功能,用手势在Android设备就能随意搜索
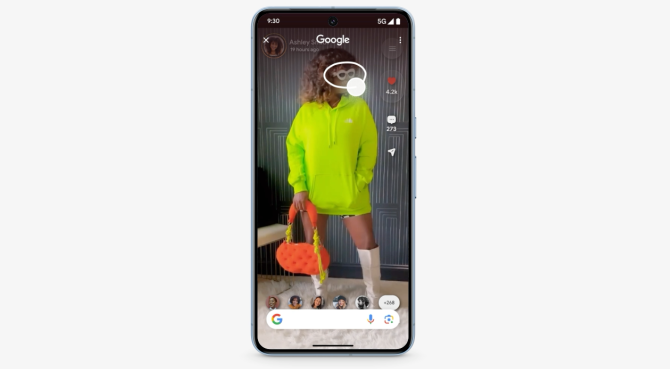
##划重点:🔄**新功能介绍:**Google在今天的Samsung发布活动中宣布推出了一种名为“CircletoSearch”的新搜索方式。这一功能允许用户通过手势操作(如画圈、划线、涂鸦或轻击)在手机任何地方进行搜索。站长网2024-01-18 14:34:4100078