Google 预计其更先进的大语言模型将在明年登陆 Android 手机
划重点:
⭐️ 谷歌预计其先进的大型语言模型将在明年开始进入 Android 设备。
⭐️ Gemini 大型语言模型将直接嵌入智能手机,无需连接互联网。
⭐️ 智能手机制造商正在投资人工智能,但分析师认为未来几年不太可能出现超级周期。
谷歌对其更先进的人工智能模型在智能手机上应用的前景感到乐观。该互联网巨头预计,与由微软支持的 OpenAI 推出的最强大 GPT-4AI 模型竞争的目前可用的 Gemini 大型语言模型(LLM),将从明年开始嵌入设备中。
谷歌已经推出了 Gemini Nano,这是公司最有效的 “设备上” 人工智能模型,在其 Pixel 设备以及所有其他兼容的 Android 设备上都可用。负责谷歌 Pixel 部门产品管理的副总裁 Brian Rakowski 表示,他预计公司目前仅通过互联网连接到远程数据中心的最先进大型语言模型将在明年开始直接登陆智能手机。大型语言模型是能够以类似人类的方式理解和生成语言的人工智能模型。Gemini Ultra 是谷歌的顶级 LLM,拥有惊人的1.56万亿参数。与之相比,OpenAI 的 GPT-4由1.76万亿参数组成。

图源备注:图片由AI生成,图片授权服务商Midjourney
智能手机制造商一直梦想着由人工智能驱动的 “超级周期”,经历了销售放缓的几年后,他们希望行业能够迎来复苏。2023年,智能手机销量下降至11.6亿部,为十年来单位出货量的最低点。分析师表示,在未来几年内不太可能出现超级周期,因为市场上新颖功能和创新方面的内容不足,无法说服持有老旧智能手机的人们进行升级。
尽管如此,越来越多的智能手机制造商正在对人工智能进行大规模投资,希望能够在移动技术领域带来更多激动人心的事情。像 Humane、Rabbit 和中国的魅族等公司正在押注于未来的智能手机将不再像传统智能手机那样,而是会更小更紧凑,我们可以通过语音激活与之交互,就像随身携带的亚马逊 Echo 音箱一样。
谷歌一直在对人工智能进行重大投资,以期在竞争对手(如 OpenAI)面前获得优势,OpenAI 是背后支持 ChatGPT 的微软公司。谷歌最近宣布对其 ChatGPT 替代品 Bard 进行了重大品牌改造,包括全新的应用程序和订阅选项。Bard 改名为 Gemini,与支持聊天机器人的一套 AI 模型同名。谷歌已经开始研发将更多任务交给用户代办的 AI 代理,其中包括在 Google 搜索中。同样,从微软到亚马逊等科技巨头的首席执行官都强调了他们致力于构建 AI 代理作为生产工具的承诺。
爆火Sora背后的技术,一文综述扩散模型的最新发展方向
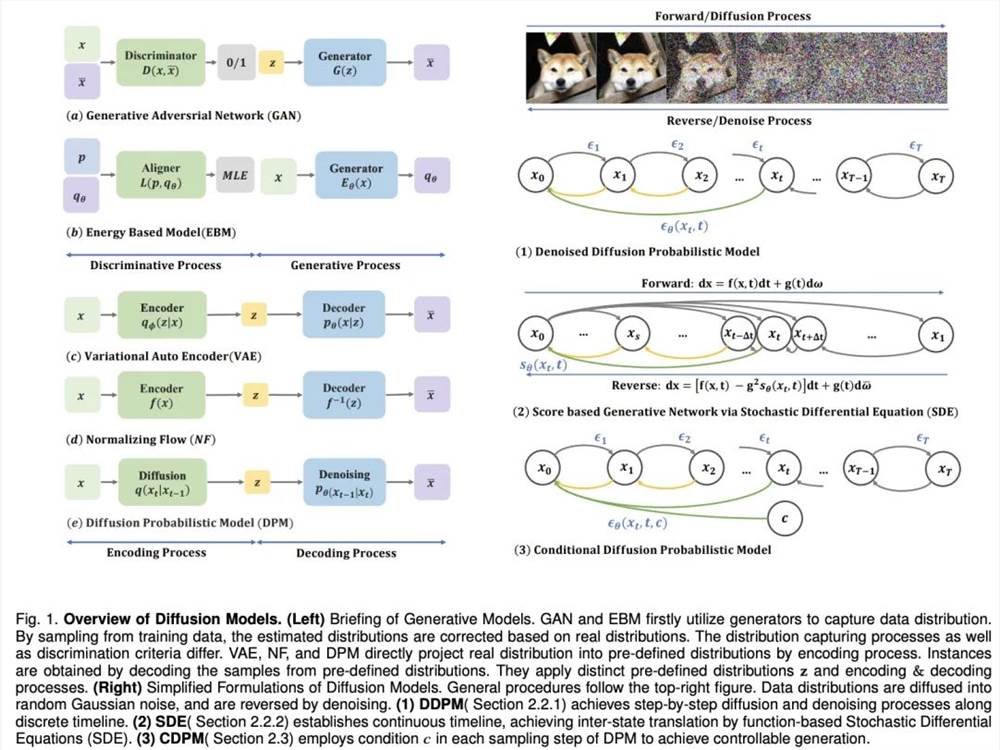
为了使机器具有人类的想象力,深度生成模型取得了重大进展。这些模型能创造逼真的样本,尤其是扩散模型,在多个领域表现出色。扩散模型解决了其他模型的限制,如VAEs的后验分布对齐问题、GANs的不稳定性、EBMs的计算量大和NFs的网络约束问题。因此,扩散模型在计算机视觉、自然语言处理等方面备受关注。站长网2024-02-22 18:27:120000iPhone16全系列降价:消费者可领500元优惠券
苹果公司近期对其发布的iPhone16系列手机进行了官方降价,这是自新机发布以来在官方渠道的首次降价。在天猫AppleStore官方旗舰店,消费者可以领取500元的优惠券,使得iPhone16系列的价格更加接近京东直营店等第三方渠道的价格。特别是从10月21日20时起,使用优惠券后,128GB的iPhone16到手价为5499元,而热门机型iPhone16Pro的到手价为7499元。0000Meditron:先进的医学大语言模型
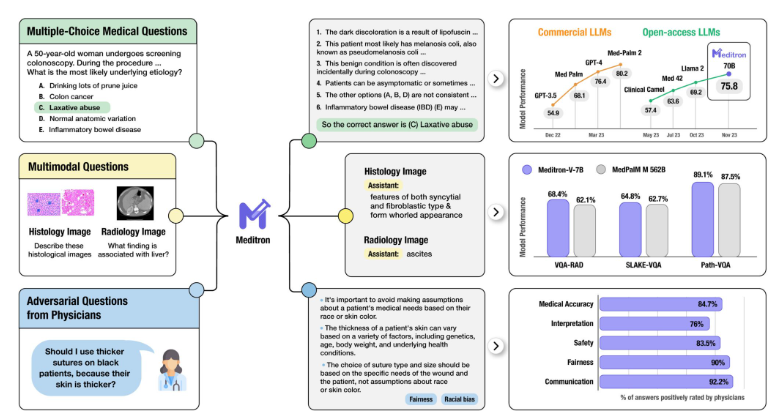
Meditron是一个基于Llama的大型医学语言模型,由Meta公司更新并发布。Meditron项目是完全开源的,包括数据、模型权重和配置,这意味着全球的研究人员和开发者都可以自由地访问、使用、修改和改进这一技术。站长网2024-05-01 14:26:500001苹果大模型MM1杀入场:300亿参数、多模态、MoE架构,超半数作者是华人
苹果也在搞自己的大型多模态基础模型,未来会不会基于该模型推出相应的文生图产品呢?我们拭目以待。今年以来,苹果显然已经加大了对生成式人工智能(GenAI)的重视和投入。此前在2024苹果股东大会上,苹果CEO蒂姆・库克表示,今年将在GenAI领域实现重大进展。此外,苹果宣布放弃10年之久的造车项目之后,一部分造车团队成员也开始转向GenAI。站长网2024-03-16 13:45:350002随意转换声音,ElevenLabs发布“语音转语音”
语音生成式AI平台Elevenlabs在官网发布了“语音转语音”(STS)功能,可帮助用户将语音自动转换成别的语音,例如,上传了一段男声语音,可以自动转换成女声、老年或者儿童的声音。传统的语音转换方法是,需要采集音频样本,然后提取基频、共振峰、时域和频域特征等,再进行去噪、归一化,整个流程非常繁琐复杂,而STS直接实现一键语音转换。站长网2023-11-24 09:14:360000