苹果大模型MM1杀入场:300亿参数、多模态、MoE架构,超半数作者是华人
苹果也在搞自己的大型多模态基础模型,未来会不会基于该模型推出相应的文生图产品呢?我们拭目以待。
今年以来,苹果显然已经加大了对生成式人工智能(GenAI)的重视和投入。此前在2024苹果股东大会上,苹果 CEO 蒂姆・库克表示,今年将在 GenAI 领域实现重大进展。此外,苹果宣布放弃10年之久的造车项目之后,一部分造车团队成员也开始转向 GenAI。
如此种种,苹果向外界传达了加注 GenAI 的决心。目前多模态领域的 GenAI 技术和产品非常火爆,尤以 OpenAI 的 Sora 为代表,苹果当然也想要在该领域有所建树。
今日,在一篇由多位作者署名的论文《MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training》中,苹果正式公布自家的多模态大模型研究成果 —— 这是一个具有高达30B 参数的多模态 LLM 系列。

论文地址:https://arxiv.org/pdf/2403.09611.pdf
该团队在论文中探讨了不同架构组件和数据选择的重要性。并且,通过对图像编码器、视觉语言连接器和各种预训练数据的选择,他们总结出了几条关键的设计准则。具体来讲,本文的贡献主要体现在以下几个方面。
首先,研究者在模型架构决策和预训练数据选择上进行小规模消融实验,并发现了几个有趣的趋势。建模设计方面的重要性按以下顺序排列:图像分辨率、视觉编码器损失和容量以及视觉编码器预训练数据。
其次,研究者使用三种不同类型的预训练数据:图像字幕、交错图像文本和纯文本数据。他们发现,当涉及少样本和纯文本性能时,交错和纯文本训练数据非常重要,而对于零样本性能,字幕数据最重要。这些趋势在监督微调(SFT)之后仍然存在,这表明预训练期间呈现出的性能和建模决策在微调后得以保留。
最后,研究者构建了 MM1,一个参数最高可达300亿(其他为30亿、70亿)的多模态模型系列, 它由密集模型和混合专家(MoE)变体组成,不仅在预训练指标中实现 SOTA,在一系列已有多模态基准上监督微调后也能保持有竞争力的性能。
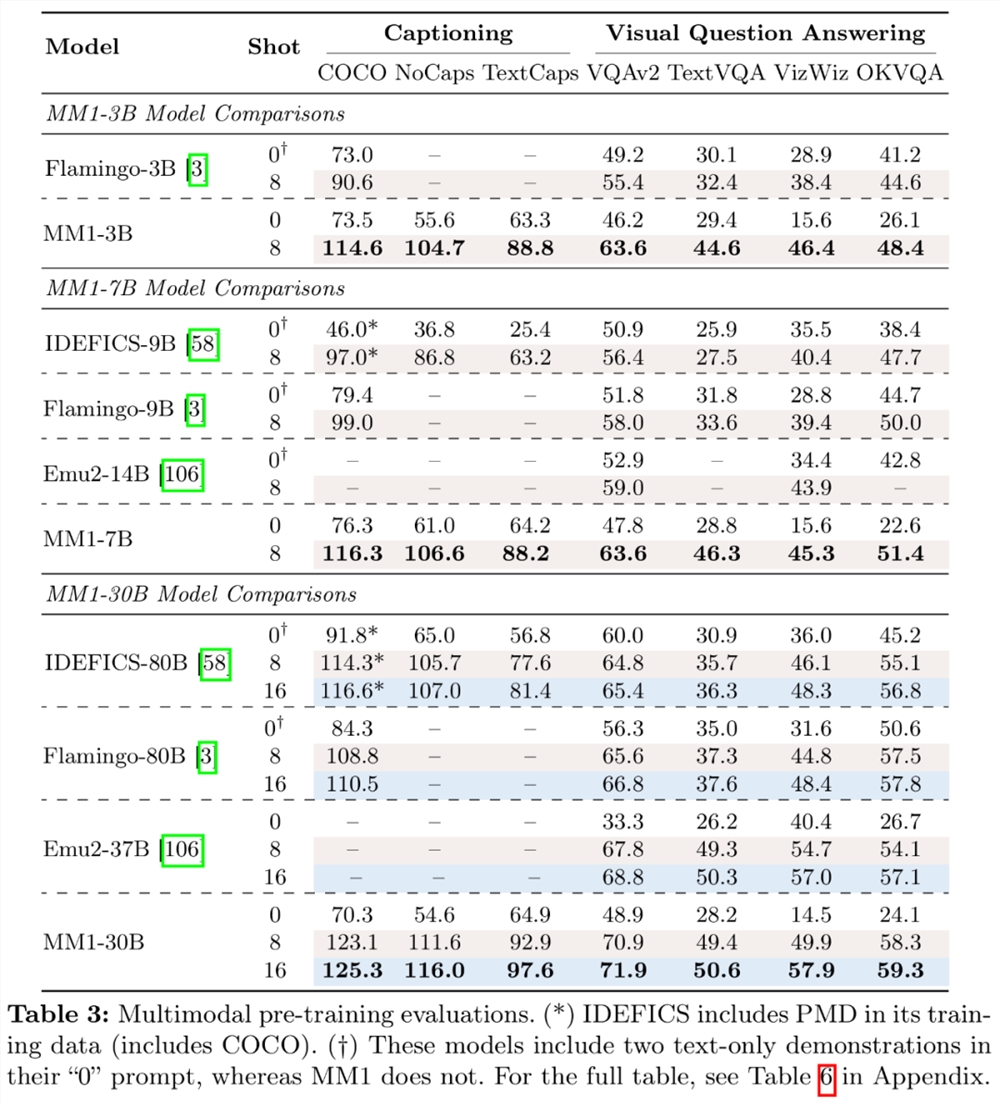
具体来讲,预训练模型 MM1在少样本设置下的字幕和问答任务上,要比 Emu2、Flamingo、IDEFICS 表现更好。监督微调后的 MM1也在12个多模态基准上的结果也颇有竞争力。
得益于大规模多模态预训练,MM1在上下文预测、多图像和思维链推理等方面具有不错的表现。同样,MM1在指令调优后展现出了强大的少样本学习能力。


方法概览:构建 MM1的秘诀
构建高性能的 MLLM(Multimodal Large Language Model,多模态大型语言模型) 是一项实践性极高的工作。尽管高层次的架构设计和训练过程是清晰的,但是具体的实现方法并不总是一目了然。这项工作中,研究者详细介绍了为建立高性能模型而进行的消融。他们探讨了三个主要的设计决策方向:
架构:研究者研究了不同的预训练图像编码器,并探索了将 LLM 与这些编码器连接起来的各种方法。
数据:研究者考虑了不同类型的数据及其相对混合权重。
训练程序:研究者探讨了如何训练 MLLM,包括超参数以及在何时训练模型的哪些部分。
消融设置
由于训练大型 MLLM 会耗费大量资源,研究者采用了简化的消融设置。消融的基本配置如下:
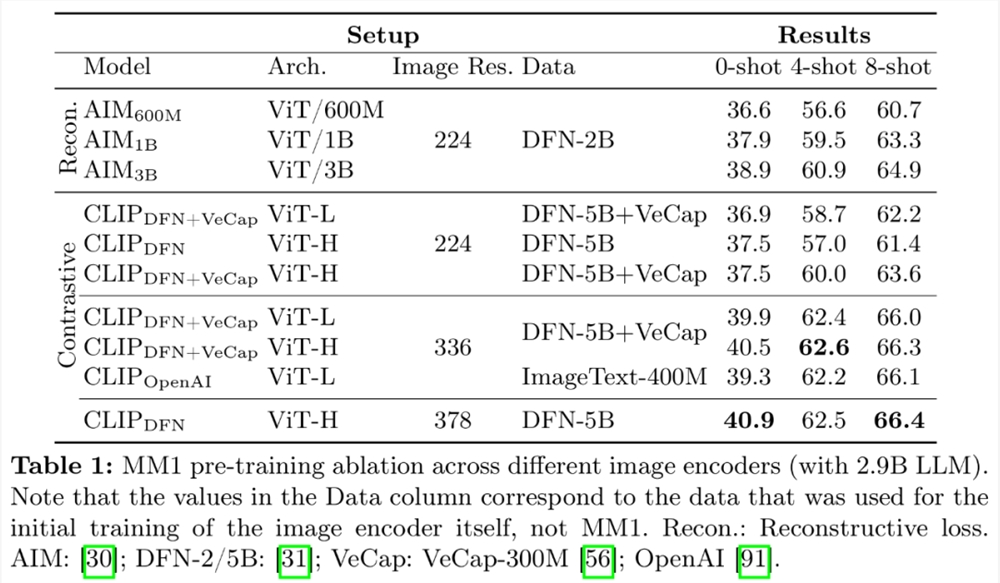
图像编码器:在 DFN-5B 和 VeCap-300M 上使用 CLIP loss 训练的 ViT-L/14模型;图像大小为336×336。
视觉语言连接器:C-Abstractor ,含144个图像 token。
预训练数据:混合字幕图像(45%)、交错图像文本文档(45%)和纯文本(10%)数据。
语言模型:1.2B 变压器解码器语言模型。
为了评估不同的设计决策,研究者使用了零样本和少样本(4个和8个样本)在多种 VQA 和图像描述任务上的性能:COCO Cap tioning 、NoCaps 、TextCaps 、VQAv2、TextVQA 、VizWiz 、GQA 和 OK-VQA。
模型架构消融试验
研究者分析了使 LLM 能够处理视觉数据的组件。具体来说,他们研究了(1)如何以最佳方式预训练视觉编码器,以及(2)如何将视觉特征连接到 LLM 的空间(见图3左)。
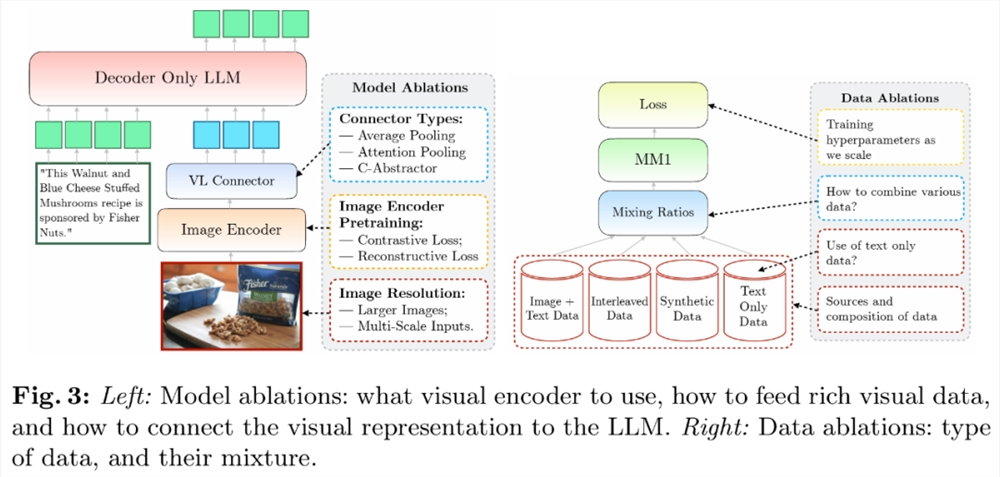
图像编码器预训练。在这一过程中,研究者主要消融了图像分辨率和图像编码器预训练目标的重要性。需要注意的是,与其他消融试验不同的是,研究者本次使用了2.9B LLM(而不是1.2B),以确保有足够的容量来使用一些较大的图像编码器。
编码器经验:图像分辨率的影响最大,其次是模型大小和训练数据组成。如表1所示,将图像分辨率从224提高到336,所有架构的所有指标都提高了约3%。将模型大小从 ViT-L 增加到 ViT-H,参数增加了一倍,但性能提升不大,通常不到1%。最后,加入 VeCap-300M (一个合成字幕数据集)后,在少样本场景中性能提升超过了1%。
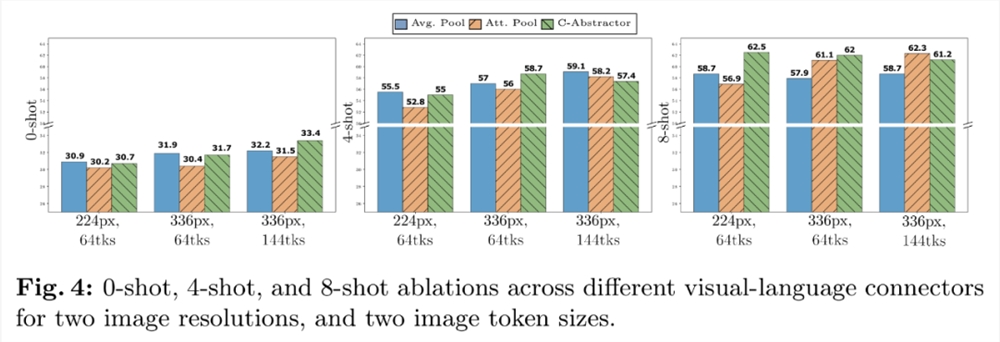
视觉语言连接器和图像分辨率。该组件的目标是将视觉表征转化为 LLM 空间。由于图像编码器是 ViT,因此其输出要么是单一的嵌入,要么是一组与输入图像片段相对应的网格排列嵌入。因此,需要将图像 token 的空间排列转换为 LLM 的顺序排列。与此同时,实际的图像 token 表征也要映射到词嵌入空间。
VL 连接器经验:视觉 token 数量和图像分辨率最重要,而 VL 连接器的类型影响不大。如图4所示,随着视觉 token 数量或 / 和图像分辨率的增加,零样本和少样本的识别率都会提高。
预训练数据消融试验
通常,模型的训练分为两个阶段:预训练和指令调优。前一阶段使用网络规模的数据,后一阶段则使用特定任务策划的数据。下面重点讨论了本文的预训练阶段,并详细说明研究者的数据选择(图3右)。
有两类数据常用于训练 MLLM:由图像和文本对描述组成的字幕数据;以及来自网络的图像 - 文本交错文档。表2是数据集的完整列表:

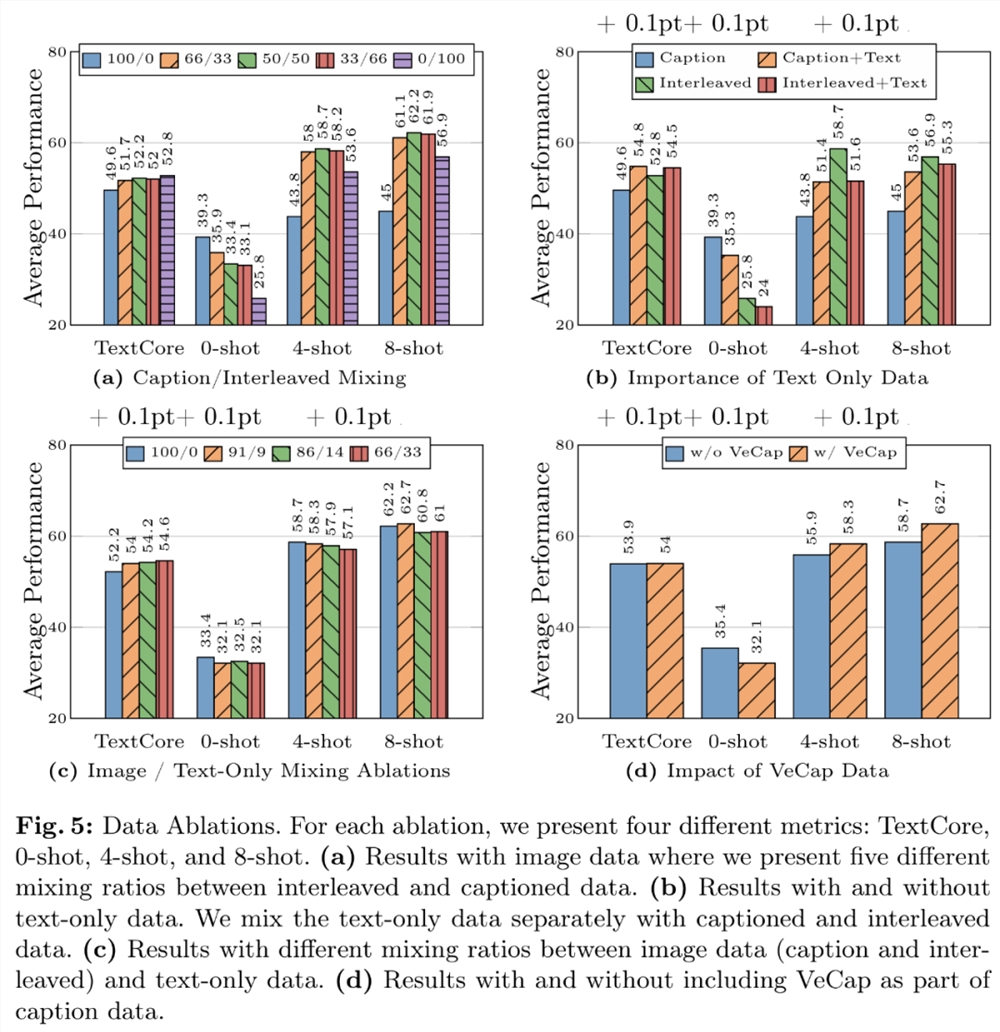
数据经验1:交错数据有助于提高少样本和纯文本性能,而字幕数据则能提高零样本性能。图5a 展示了交错数据和字幕数据不同组合的结果。
数据经验2:纯文本数据有助于提高少样本和纯文本性能。如图5b 所示,将纯文本数据和字幕数据结合在一起可提高少样本性能。
数据经验3:谨慎混合图像和文本数据可获得最佳的多模态性能,并保留较强的文本性能。图5c 尝试了图像(标题和交错)和纯文本数据之间的几种混合比例。
数据经验4:合成数据有助于少样本学习。如图5d 所示,人工合成数据确实对少数几次学习的性能有不小的提升,绝对值分别为2.4% 和4%。
最终模型和训练方法
研究者收集了之前的消融结果,确定 MM1多模态预训练的最终配方:
图像编码器:考虑到图像分辨率的重要性,研究者使用了分辨率为378x378px 的 ViT-H 模型,并在 DFN-5B 上使用 CLIP 目标进行预训练;
视觉语言连接器:由于视觉 token 的数量最为重要,研究者使用了一个有144个 token 的 VL 连接器。实际架构似乎不太重要,研究者选择了 C-Abstractor;
数据:为了保持零样本和少样本的性能,研究者使用了以下精心组合的数据:45% 图像 - 文本交错文档、45% 图像 - 文本对文档和10% 纯文本文档。
为了提高模型的性能,研究者将 LLM 的大小扩大到3B、7B 和30B 个参数。所有模型都是在序列长度为4096、每个序列最多16幅图像、分辨率为378×378的情况下,以512个序列的批量大小进行完全解冻预训练的。所有模型均使用 AXLearn 框架进行训练。
他们在小规模、9M、85M、302M 和1.2B 下对学习率进行网格搜索,使用对数空间的线性回归来推断从较小模型到较大模型的变化(见图6),结果是在给定(非嵌入)参数数量 N 的情况下,预测出最佳峰值学习率 η:
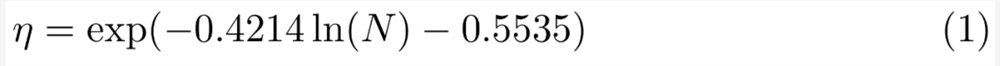
通过专家混合(MoE)进行扩展。在实验中,研究者进一步探索了通过在语言模型的 FFN 层添加更多专家来扩展密集模型的方法。
要将密集模型转换为 MoE,只需将密集语言解码器替换为 MoE 语言解码器。为了训练 MoE,研究者采用了与密集骨干4相同的训练超参数和相同的训练设置,包括训练数据和训练 token。
关于多模态预训练结果,研究者通过适当的提示对预先训练好的模型在上限和 VQA 任务上进行评估。表3对零样本和少样本进行了评估:
监督微调结果
最后,研究者介绍了预训练模型之上训练的监督微调(SFT)实验。
他们遵循 LLaVA-1.5和 LLaVA-NeXT,从不同的数据集中收集了大约100万个 SFT 样本。鉴于直观上,更高的图像分辨率会带来更好的性能,研究者还采用了扩展到高分辨率的 SFT 方法。
监督微调结果如下:
表4展示了与 SOTA 比较的情况,「-Chat」表示监督微调后的 MM1模型。
首先,平均而言,MM1-3B-Chat 和 MM1-7B-Chat 优于所有列出的相同规模的模型。MM1-3B-Chat 和 MM1-7B-Chat 在 VQAv2、TextVQA、ScienceQA、MMBench 以及最近的基准测试(MMMU 和 MathVista)中表现尤为突出。
其次,研究者探索了两种 MoE 模型:3B-MoE(64位专家)和6B-MoE(32位专家)。在几乎所有基准测试中,苹果的 MoE 模型都比密集模型取得了更好的性能。这显示了 MoE 进一步扩展的巨大潜力。
第三,对于30B 大小的模型,MM1-30B-Chat 在 TextVQA、SEED 和 MMMU 上的表现优于 Emu2-Chat37B 和 CogVLM-30B。与 LLaVA-NeXT 相比,MM1也取得了具有竞争力的全面性能。
不过,LLaVA-NeXT 不支持多图像推理,也不支持少样本提示,因为每幅图像都表示为2880个发送到 LLM 的 token,而 MM1的 token 总数只有720个。这就限制了某些涉及多图像的应用。
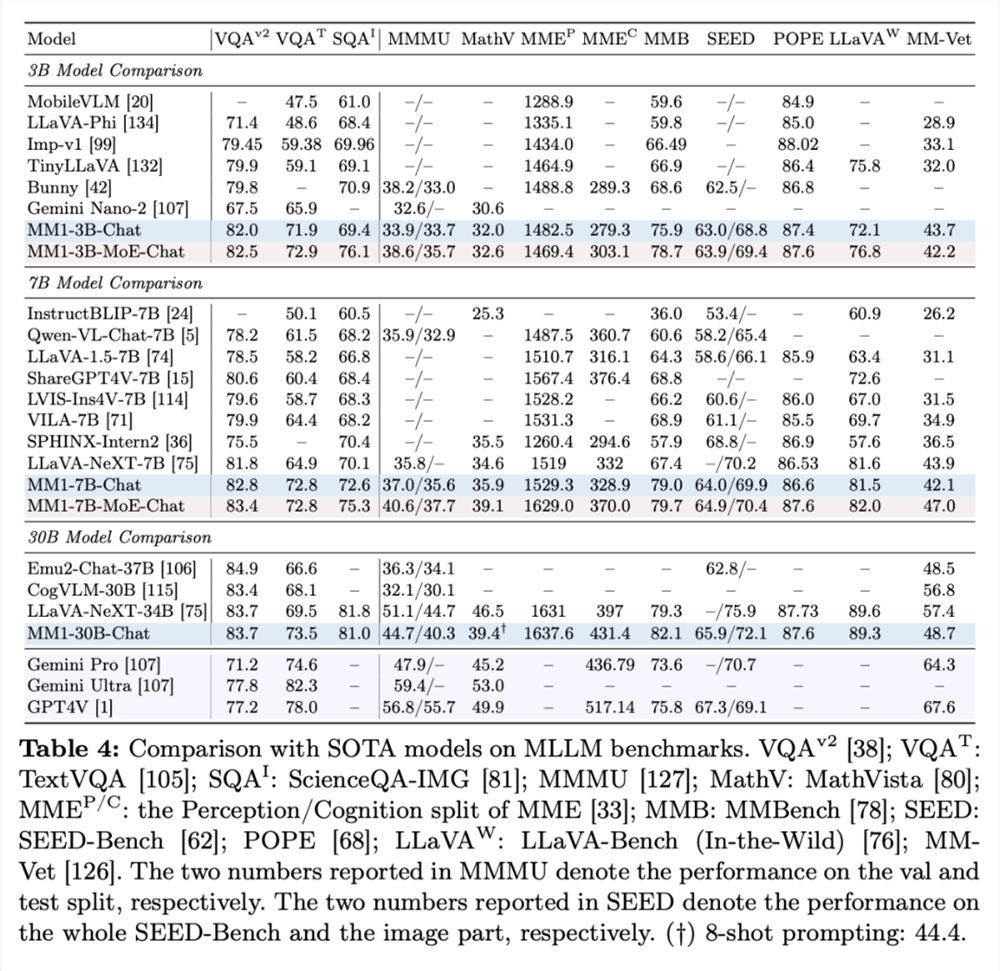
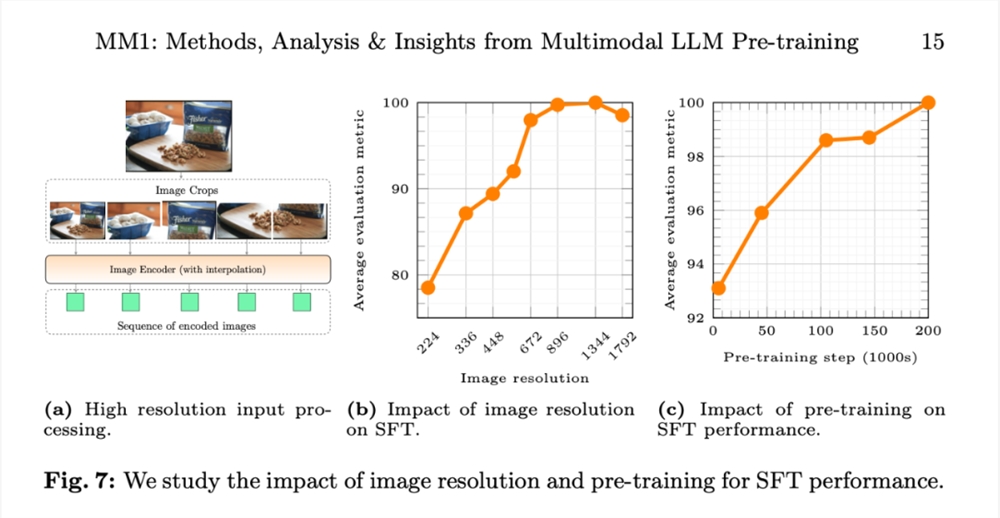
图7b 显示,输入图像分辨率对 SFT 评估指标平均性能的影响,图7c 显示,随着预训练数据的增加,模型的性能不断提高。
图像分辨率的影响。图7b 显示了输入图像分辨率对 SFT 评估指标平均性能的影响。
预训练的影响:图7c 显示,随着预训练数据的增加,模型的性能不断提高。
更多研究细节,可参考原论文。
抖音下架微短剧《重返1990之首富人生》 存在内容低俗等问题
今日,抖音发布关于下架微短剧《重返1990之首富人生》的公告称,持续推进微短剧内容治理,已发布多期专项治理公告,鼓励和推广优质微短剧作品,从严打击宣扬不良价值观、含有色情低俗等内容的违规微短剧。在专项治理期间,《重返1990之首富人生》《重返1990之霸道人生》(曾改名“重回……”“重生……”等)等微短剧存在内容低俗,价值导向偏差等问题。平台已将该剧下架,并排查清理相关视频,现予以公示。站长网2024-08-15 21:18:030000人工智能将面孔识别技术带入动物界:AI 被用来识别鹅的面孔
站长之家(ChinaZ.com)11月6日消息:维也纳大学的生物学家SoniaKleindorfer博士,现任KonradLorenz行为与认知研究中心主任,最近发起了一项突破性研究。继承了著名的奥地利生物学家KonradLorenz研究灰雁鹅群行为的遗产,Kleindorfer博士及其团队开发了一种用于灰鹅面部识别的人工智能工具,旨在提高对鹅群个体识别的准确性。站长网2023-11-06 12:08:540000AIGC「占领」抖音热点
2024年,UGC平台的内容悄然迭代,头部效应不再明显,AIGC成为UGC平台最重要的玩法之一。借助于「挑战赛」的裂变玩法,AI特效滤镜在在抖音上风靡。参与门槛低是此类内容能够激发用户参与热情的一大原因,同时又满足了用户的个性化需求,在特效风格基础上,生成的AI内容也有一定的不确定性,带给用户「开盲盒」式的体验。00002024年,生成式AI将助长更强大的网络钓鱼活动
划重点:🔸谷歌云预测生成式AI的持续使用将帮助创建更智能的网络钓鱼活动,而网络安全专家将使用相同的工具来捍卫并缩小技能差距。🔸生成式AI将助长更强大的网络钓鱼活动和规模化信息操作,使内容包括语音和视频更加真实,更难以辨别真伪。🔸谷歌云预测,网络防御者将采用类似的工具来对抗这些威胁,并且AI将提供能力来增强人类分析和推断行动的能力。站长网2023-11-09 11:22:140000《黑神话:悟空》Steam平台销量已达1890万份!通关玩家超三成
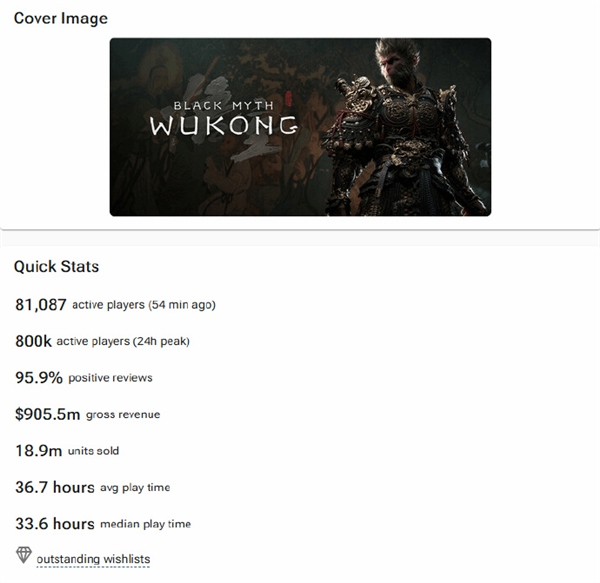
快科技9月12日消息,分析公司VGInsights最新数据显示,《黑神话:悟空》在Steam平台的销量已经达到了1890万份,且游戏在Steam平台的总收入已经超过了9.05亿美元(约合人民币超64亿)。游戏首位投资人吴旦也曾表示,《黑神话:悟空》在其生命周期内可以达到3000万套的销量,目前本作也正在一步一步朝此目标迈进。站长网2024-09-13 17:31:280000