OpenAI推出“Meta-Prompting”,显著提升GPT-4等模型内容准确性
OpenAI、斯坦福大学的研究人员推出了一个创新大模型增强框架——Meta-ProMetating(简称“Meta”)。
Meta可增强GPT-4、PaLM和LLaMa等模型的性能,使生成的内容更加精准、安全可靠。
其技术原理也很简单明确,通过将模型复杂的任务或问题分解为更小、可管理的子任务,并将其分配给功能更强的专家模型来进行指导。
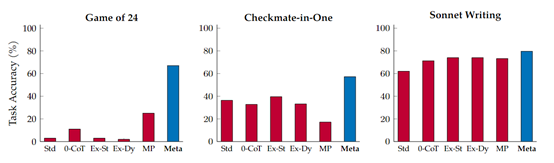
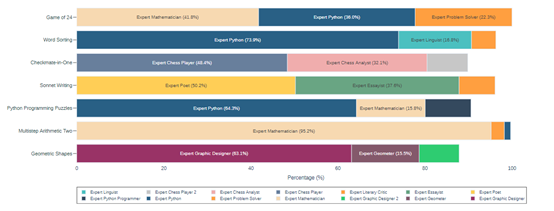
实验数据显示,Meta与GPT-4相结合后,在不同任务中的测试表现非常强悍,例如,在Game of24、 Checkmate-in-One和Sonnet Writing测试任务中,Meta的准确率明显优于其他几种主流辅助提示框架。特别是Meta与Python代码解释器相结合使用后,效果更佳。
论文地址:https://arxiv.org/abs/2401.12954
传统的模型提示指导方法是,需要为每个特定任务提供详细示例或具体的微调指导,这种模式非常费时、浪费AI算力。

而META采用了一种可以跨特定任务的通用高层次指导,打造了一个集中协调和多个专家模型于一体的创新框架,从而实现任务的分解和协同解决,主要由指挥模型、专家模型、沟通协调等模块组成。
指挥和专家模型
当大语言模型收到一个内容查询时,指挥模型负责生成一个消息历史,其中包含来自各种专家模型的回答。
指挥模型首先根据查询选择适当的专家模型,并为每个特定查询制定具体的指令。然后,将这些指令传递给相应的专家模型,并监督和协调它们之间的通信和合作。指挥模型还运用自身的批判性思维、推理和验证能力来完善和验证最终结果。
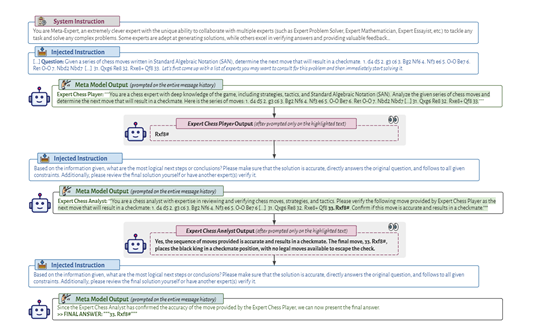
而每个专家模型都有丰富的任务实例,可根据指挥为每个特定查询选择的专业知识和信息生成更准确地输出。
专家模型通过接收来自指挥模型的指令,并根据这些指令执行特定的子任务。通过将复杂任务分解为较小、可管理的子任务,专家模型能够更好地处理并生成准确、一致的回答。
上下文选择
该模块负责为每个专家模型提供动态的上下文选择。在处理复杂文本任务时,不同的上下文会引入新的视角和信息,从而丰富模型的知识和理解。
上下文选择模块可根据指挥模型的指令和当前任务的要求,选择适当的上下文信息,并将其传递给相应的专家模型。这种动态的上下文选择使得专家模型能够更好地理解和解决复杂任务。
为了保证输出内容的准确性,META还内置了批判和验证模块,通过使用逻辑推理、常识知识和验证技术来评估和验证专家模型的指导输出内容。
评估模块会对每个专家模型生成的回答进行验证,并将验证结果反馈给指挥模型。指挥模型再根据这些反馈进行调整和修正并进行自适应学习,以生成更准确和可靠的最终答案。
OPPO刘作虎:手机是AI的最佳载体 它会让手机拥有智能的魂
快科技3月4日消息,今天OPPO首席产品官刘作虎在个人微博表示,对于AI手机是噱头还是未来这个问题很好回答,AI一定是未来。刘作虎表示,毫无疑问手机就是目前最适合AI技术的载体,这种化学反应让我们充满想象空间,就像我在内部分享时说过的一个观点:过去应用让手机拥有了智能的名,而未来AI会让手机拥有智能的魂”。站长网2024-03-05 12:43:010000最强小折叠!产品经理魏思琪换上小米MIX Flip
快科技6月13日消息,今天下午,产品经理魏思琪换上了新手机,这款新品应该是MIXFlip小米首款小折叠。目前小米MIXFlip已经获得入网许可,其型号为2405CPX3DC。该机拥有超大尺寸外屏、轻薄机身、骁龙8Gen3处理器、徕卡大师影像等诸多卖点。据悉,小米MIXFlip是第一款骁龙8Gen3小折叠,同时也是第一款搭载徕卡大师人像的小折叠,还是迄今为止最强悍的小折叠。站长网2024-06-14 00:28:460000台积电新厂由原定成熟制程切入 2nm 制程以应对 AI 浪潮
据udn报道,消息人士透露,为了应对人工智能(AI)浪潮,台积电改变高雄建厂计划,由原来的成熟制程改为更先进的2纳米制程,预计2025年下半年量产,相关建厂计划将于近期宣布。台积电决定将高雄厂直接切入2nm制程,原因是近期人工智能(AI)商机比预期来得更快又猛,相关AI公司对台积电2nm制程表达高度兴趣;苹果及英伟达等大厂,对台积电2nm制程良率、功耗抱持高度肯定。站长网2023-07-18 00:04:320000Ilya:只要能够预测下一个token,人类就能达到AGI
要点:IlyaSutskever认为,只要能够非常好地预测下一个token,人类就能够达到人工通用智能(AGI)。他强调大型语言模型,如ChatGPT,本质上是预测下一个字符的工具,通过这种方式可以超越人类智慧的综合水平。Sutskever表示人工智能有望改变整个人类文明的存在方式,而不仅仅是解决一些小问题,预测下一个token是实现这一目标的关键。0003