谷歌VideoPoet负责人蒋路跳槽TikTok!对标Sora,AI视频模型大战在即
谷歌VideoPoet项目Research Lead,CMU兼职教授蒋路的Google Scholar资料显示已加入TikTok。
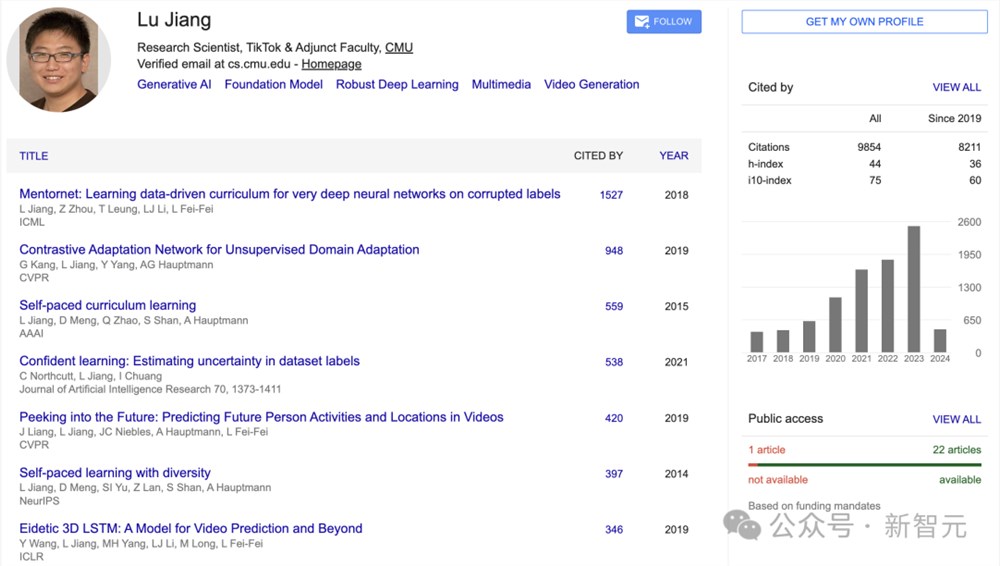
最近,有传闻TikTok招募了某篇论文的作者作为北美技术部门负责人,研发能和Sora对抗的视频生成AI。
而蒋路3周前在Linkedin上发布了离职谷歌的消息,也向外界揭开了谜底。
他作为谷歌VideoPoet项目的负责人,将离开Google Research,不过会留在湾区,继续视频生成领域的工作。

「人才第一,数据第二,算力第三」,谢赛宁的AI突破「3要素」,已经为大厂在未来构建自己的AI护城河指明了方向。
而蒋路带领谷歌团队在去年年底推出了在技术路线上与Sora相似的视频生成技术:VideoPoet,让他成为了世界上为数不多的有能力构建最前沿AI视频生成技术的科学家。

VideoPoet在Sora发布之前就已经将AI视频的前沿推进到了生成10秒长,一致性非常强,动作幅度大且连贯的视频。
而与此同时,他还是CMU的兼职教授,有非常丰富的科研经历和成果。
蒋路这样既有深厚的理论功底,又有最前沿大型项目的工程和管理经验的复合型专家,自然成为了大厂必争的AI基石型人才。
个人介绍
蒋路在Google担任研究科学家和管理岗位,同时也是卡内基梅隆大学计算机科学学院语言技术研究所的兼职教授。
在CMU,他不仅指导研究生的科研项目,还亲自讲授课程。
他的研究成果在自然语言处理(ACL)和计算机视觉(CVPR)等领域的顶级会议上屡获佳绩,还在ACM ICMR、IEEE SLT 和 NIST TRECVID等重要会议上获奖。
他的研究对多款谷歌产品的开发和完善起到了至关重要的作用:包括YouTube、Cloud、Cloud AutoML、Ads、Waymo和Translate 等。
这些产品每天服务全球数十亿用户。
除了上述这些内容以外,还有另一个侧面能很好地说明蒋路学术水平的高度:他与众多计算机视觉和自然语言处理领域的顶尖研究者都有过合作。
2017至2018年期间,他是Google Cloud AI首批研究团队的创始成员,由李佳博士和李飞飞博士亲自挑选。
随后,他加入了Google Research,与Weilong Yang博士(2019-2020)、Ce Liu博士(2020-2021)、Madison Le(2021-2022)和Irfan Essa博士(2023)等人都有过合作。
此外,在卡内基梅隆大学读博期间,他的论文由Tat-Seng Chua博士和 Louis-Philippe Morency博士共同指导。2017他在Alexander Hauptmann博士和Teruko Mitamura博士的帮助下成功毕业。
他在雅虎、谷歌和微软研究院的实习时,得到了Liangliang Cao博士、Yannis Kalantidis博士、Sachin Farfade、Paul Natsev博士、Balakrishnan Varadarajan博士、Qiang Wang博士和Dongmei Zhang博士等人的指导。
从他在领英上的履历可以看出,很多科技大厂都留有过他的足迹。

在CMU和NSF都有过实习经历。

而在毕业之前,他在雅虎,谷歌,微软都实习过。
他本科毕业于西安交通大学,研究生毕业于布鲁塞尔自由大学,博士毕业于CMU。

VideoPoet
他在谷歌带领的团队在去年底推出的VideoPoet,已经用Transformer代替了传统的UNet,成为AI视频生成当时的SOTA.
这项成就,也成为了TikTok相中他最主要的原因。
相比起只能生成小幅动作的Gen-2,VideoPoet一次能够生成10秒超长,且连贯大动作视频,可以说是实现了完全碾压!
另外,VideoPoet也并非基于扩散模型,而是多模态大模型,便可拥有T2V、V2A等能力,或将成为未来视频生成的主流。
相比起其他模型,谷歌的方法是将多种视频生成功能无缝集成到单一的大语言模型中,而不依赖针对各个任务分别训练的专用组件。

具体来说,VideoPoet主要包含以下几个组件:
- 预训练的MAGVIT V2视频tokenizer和SoundStream音频tokenizer,能将不同长度的图像、视频和音频剪辑转换成统一词汇表中的离散代码序列。这些代码与文本型语言模型兼容,便于与文本等其他模态进行结合。
- 自回归语言模型可在视频、图像、音频和文本之间进行跨模态学习,并以自回归方式预测序列中下一个视频或音频token。
- 在大语言模型训练框架中引入了多种多模态生成学习目标,包括文本到视频、文本到图像、图像到视频、视频帧延续、视频修复/扩展、视频风格化和视频到音频等。此外,这些任务可以相互结合,实现额外的零样本功能(例如,文本到音频)。

VideoPoet能够在各种以视频为中心的输入和输出上进行多任务处理。其中,LLM可选择将文本作为输入,来指导文本到视频、图像到视频、视频到音频、风格化和扩图任务的生成
使用LLM进行训练的一个关键优势是,可以重用现有LLM训练基础设施中引入的许多可扩展的效率改进。
不过,LLM是在离散token上运行的,这可能会给视频生成带来挑战。
幸运的是,视频和音频tokenizer,可以将视频和音频剪辑编码为离散token序列(即整数索引),并可以将其转换回原始表示。
VideoPoet训练一个自回归语言模型,通过使用多个tokenizer(用于视频和图像的MAGVIT V2,用于音频的SoundStream)来跨视频、图像、音频和文本模态进行学习。
一旦模型根据上下文生成了token,就可以使用tokenizer解码器将这些token转换回可查看的表示形式。

VideoPoet任务设计:不同模态通过tokenizer编码器和解码器与token相互转换。每个模态周围都有边界token,任务token表示要执行的任务类型
相比于之前的视频生成模型,VideoPoet有这么三个比较大的优势。
一个是能生成更长的视频,一个是用户能对生成的视频有更好的控制能力,最后一个则是VideoPoet还可以根据文本提示,生成不同的运镜手法。
而在测试中,VideoPoet也是拔得头筹,碾压了不少其它视频生成模型。
文本保真度:
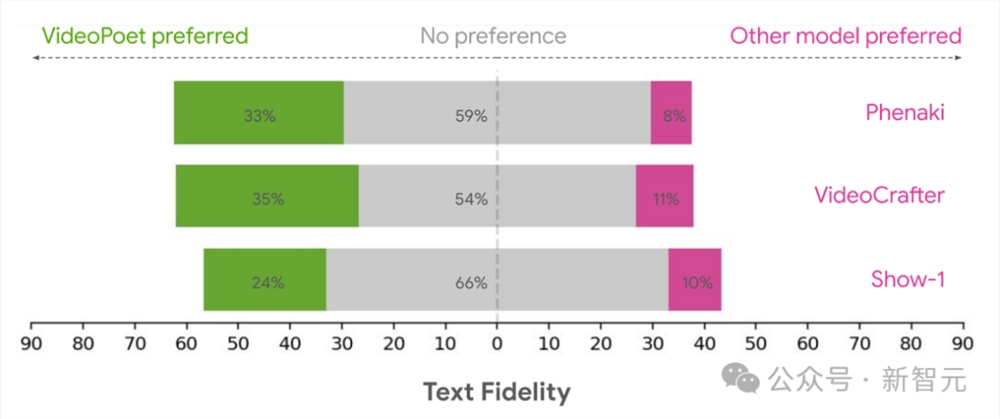
文本保真度的用户偏好评级,即在准确遵循提示方面首选视频的百分比
动作趣味性:
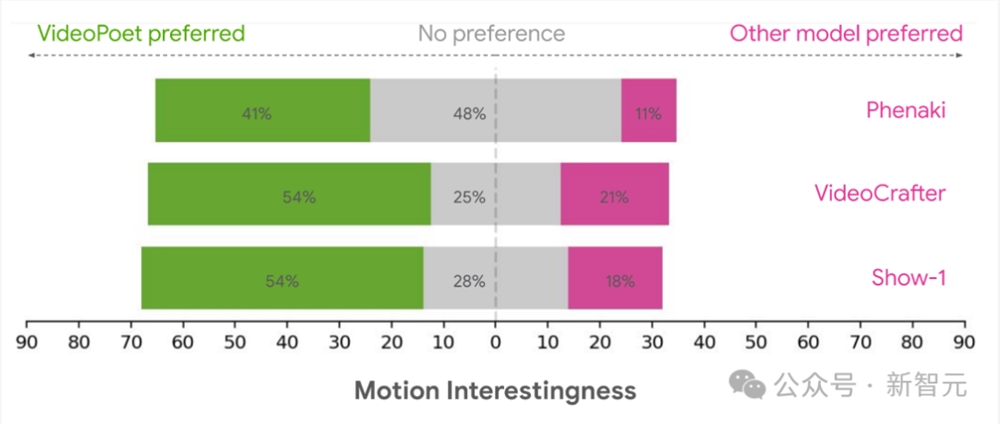
用户对动作趣味性的偏好评级,即在产生有趣的动作方面,首选视频的百分比
综上可见,平均有24-35%的人认为VideoPoet生成的示例比其他模型更加遵循提示,而其他模型的这一比例仅为8-11%。
此外,41%-54%的评估者认为VideoPoet中的示例动作更有趣,而其他模型只有11%-21%。
而有关未来的研究方向,谷歌研究人员表示,VideoPoet框架将会实现「any-to-any」的生成,比如扩展文本到音频、音频到视频,以及视频字幕等等。
知乎最新变动:PC网页端非登录用户已无法查看回答全文
快科技5月27日消息,近期,知乎平台的一项新变动引起了用户的广泛关注。据媒体报道,非登录用户在PC网页端访问知乎时,已无法查看回答的全文内容。经测试发现,当用户尝试点击展开阅读全文”时,系统会自动弹出登录窗口,而非登录用户无法直接浏览全文。在2022年3月,工信部针对部分网站强制用户下载App才能浏览全文的问题,召开了行政指导会,督促相关互联网企业进行整改,并明确指出:站长网2024-05-27 19:47:120001调查显示:三成亚洲企业缺乏生成式AI政策
🔍划重点:1.亚洲数字信任专业人员表示对生成式人工智能(AI)存在高度不确定性,缺乏相关政策。2.调查显示,尽管缺乏政策支持,许多亚洲企业员工正在使用生成式AI,用途多样化。3.AI对工作产生的影响令人担忧,但仍有乐观情绪,大多数认为AI将对行业、组织和职业产生积极或中性影响。站长网2023-10-30 16:10:520000ControlNet新玩法爆火:画出可扫码插画,内容链接任意指定
一组神秘的“虚拟老婆”照片,最近在国内外社交媒体上传疯了。怎么回事?试着用手机扫一下,就能发现其中的玄机——原来这些看起来颇为自然的照片,都是藏了二维码的图像。它们不仅能被手机相机识别,跳转的网站还都是有效的:从推特到Reddit,每隔几条就能刷出这些二维码照片,下面全是一片“竟然扫出来了”的惊叹声。站长网2023-06-08 07:23:220004调查显示,仅10%企业在过去一年采用生成式AI解决方案
划重点:1.📊仅有10%的企业在过去一年中采用生成式AI解决方案,尽管存在显著改进的潜力。2.💡调查揭示,虽然存在采用生成式AI的犹豫,但已经采用的企业中有一半报告了客户体验改善、效率提高、产品能力升级和显著成本节省等多重好处。站长网2023-12-06 11:58:160000微软高管透露将推出更多超越OpenAI的大语言模型
**划重点:**1.🌐微软高管EricBoyd在采访中透露,公司计划推出更多超越OpenAI的大语言模型(LLMs),以满足客户对选择的需求。2.🚀Boyd表示,微软的生成式AI应用及其驱动这些应用的LLMs是安全可用的,但他强调,专注于文本生成等领域的公司能够更快地推进。0000