谷歌提出全新RLHF方法:消除奖励模型,且无需对抗性训练
效果更稳定,实现更简单。
大型语言模型(LLM)的成功离不开「基于人类反馈的强化学习(RLHF)」。RLHF 可以大致可以分为两个阶段,首先,给定一对偏好和不偏好的行为,训练一个奖励模型,通过分类目标为前者分配更高的分数。然后通过某种强化学习算法优化这个奖励函数。然而,奖励模型的关键要素可能会产生一些不良影响。
来自卡内基梅隆大学(CMU)和 Google Research 的研究者联合提出了一种简单的、理论上严格的、实验上有效的 RLHF 新方法 —— 自我博弈偏好优化(Self-Play Preference Optimization,SPO)。该方法消除了奖励模型,并且不需要对抗性训练。

论文:A Minimaximalist Approach to Reinforcement Learning from Human Feedback
论文地址:https://arxiv.org/abs/2401.04056
方法简介
SPO 方法主要包括两个方面。首先,该研究通过将 RLHF 构建为两者零和博弈(zero-sum game),真正消除了奖励模型,从而更有能力处理实践中经常出现的噪声、非马尔可夫偏好。其次,通过利用博弈的对称性,该研究证明可以简单地以自我博弈的方式训练单个智能体,从而消除了不稳定对抗训练的需要。
实际上,这相当于从智能体中采样多个轨迹,要求评估者或偏好模型比较每对轨迹,并将奖励设置为轨迹的获胜率。
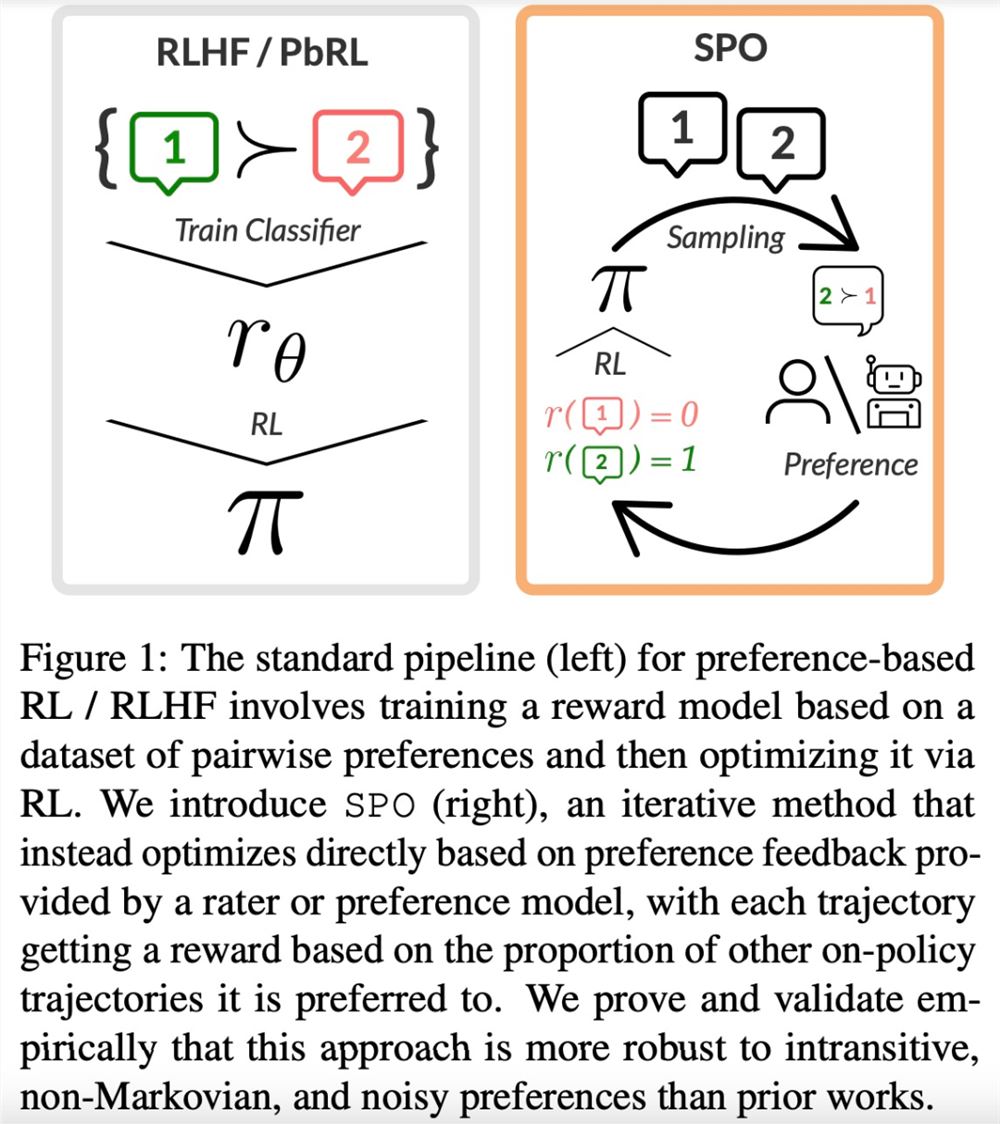
SPO 避免了奖励建模、复合 error 和对抗性训练。通过从社会选择理论(social choice theory)中建立最小最大获胜者的概念,该研究将 RLHF 构建为两者零和博弈,并利用该博弈支付矩阵的对称性来证明可以简单地训练单个智能体来对抗其自身。


该研究还分析了 SPO 的收敛特性,并证明在潜在奖励函数确实存在的情况下,SPO 能以与标准方法相媲美的快速速度收敛到最优策略。
实验
该研究在一系列具有现实偏好函数的连续控制任务上,证明了 SPO 比基于奖励模型的方法性能更好。SPO 在各种偏好设置中能够比基于奖励模型的方法更有效地学习样本,如下图2所示。
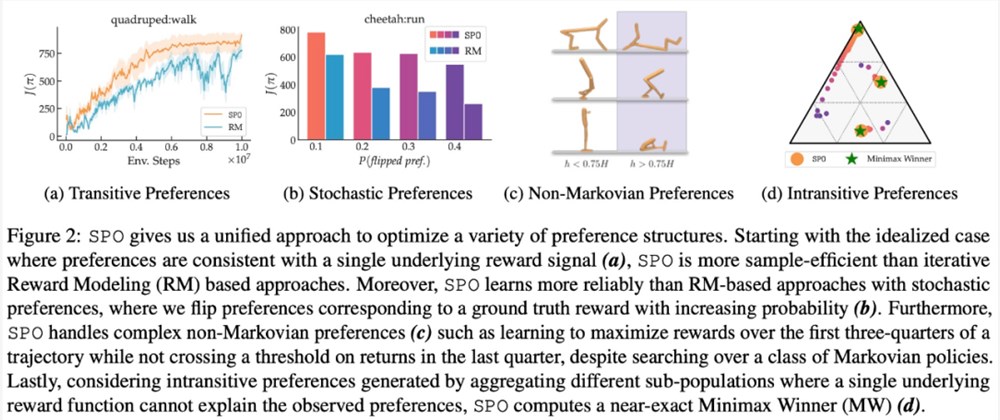

该研究从多个维度将 SPO 与迭代奖励建模 (RM) 方法进行比较,旨在回答4个问题:
当面 intransitive 偏好时,SPO 能否计算 MW?
在具有独特 Copeland Winners / 最优策略的问题上,SPO 能否匹配或超过 RM 样本效率?
SPO 对随机偏好的稳健性如何?
SPO 可以处理非马尔可夫偏好吗?

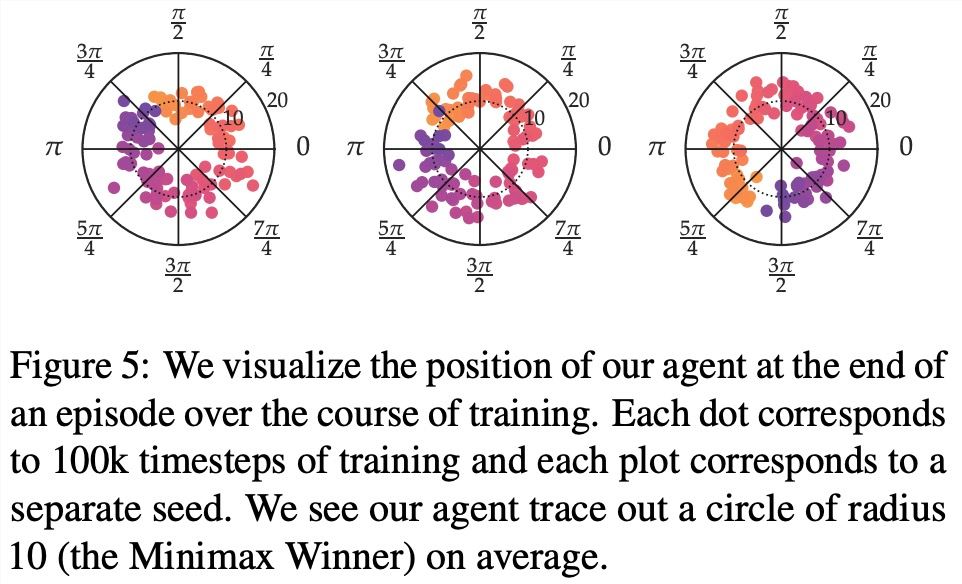
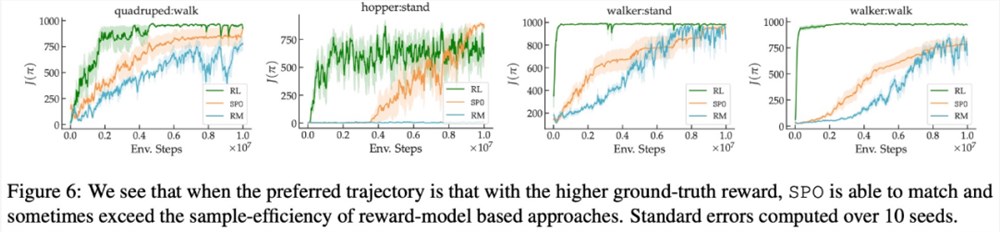
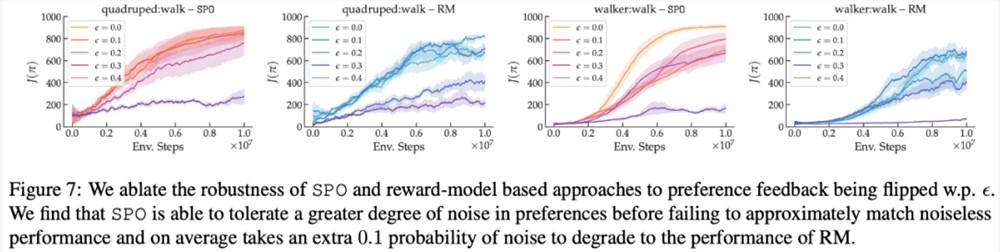
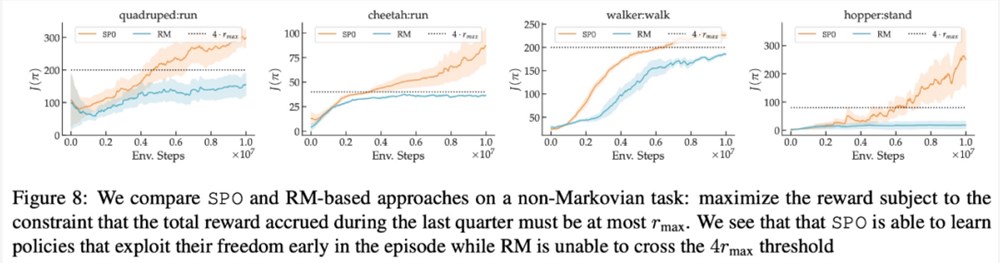
在最大奖励偏好、噪声偏好、非马尔可夫偏好方面,该研究的实验结果分别如下图6、7、8所示:
感兴趣的读者可以阅读论文原文,了解更多研究内容。
艺术家现在可以通过 Nightshade 来反击人工智能:保护其作品免受 AI 模型训练的侵犯
站长之家(ChinaZ.com)10月24日消息:新工具Nightshade赋予艺术家一种全新的力量,让他们能够在上传作品之前,对其像素进行不可见的修改,从而在作品被AI公司用于训练模型时,令生成的模型陷入混乱和不可预测的状态。站长网2023-10-25 20:20:420000vivo手机寿命一般几年
vivo作为国内一线手机品牌,备受消费者喜爱。但是,随着使用时间的增长,许多用户开始担心自己的vivo手机寿命能够持续多长时间。那么,vivo手机一般能使用多长时间呢?vivo手机在普遍情况下,其寿命可以达到2-3年。但是,这个寿命的长短还与很多因素有关,包括使用时间长短、手机品质、手机性能等。下面将分别对这些因素进行介绍。1.使用时间长短站长网2023-05-23 18:46:220000网易有道「子曰」教育大模型通过相关备案 将对公众开放
11月4日,网易有道「子曰」教育大模型正式通过相关备案。「子曰」教育大模型及其应用产品即将对公众开放。网易有道表示,「子曰」教育大模型将不断汲取用户反馈快速迭代升级,搭载在更丰富的智能硬件产品及APP中,为全年龄段学习者持续提供高效的学习体验。此外,基于「子曰」教育大模型,近期将再次发布一系列精彩的新产品及新应用。站长网2023-11-04 15:10:250000蚂蚁集团回应职级改革:新体系可提供更好的组织支撑
今天上午,有知情人透露,蚂蚁集团正在推进职级改革。有关职级体系改革的通知已经发出,最大的变化是对原职级做了“拆分”:即P4不变,P5-P9每级按照绩效打分一拆二:P5对应10、11,P6对应12、13,P7对应14、15,P8对应16、17,P9对应18、19。0000创企业Kolena获1500万美元融资 专注AI模型测试工具
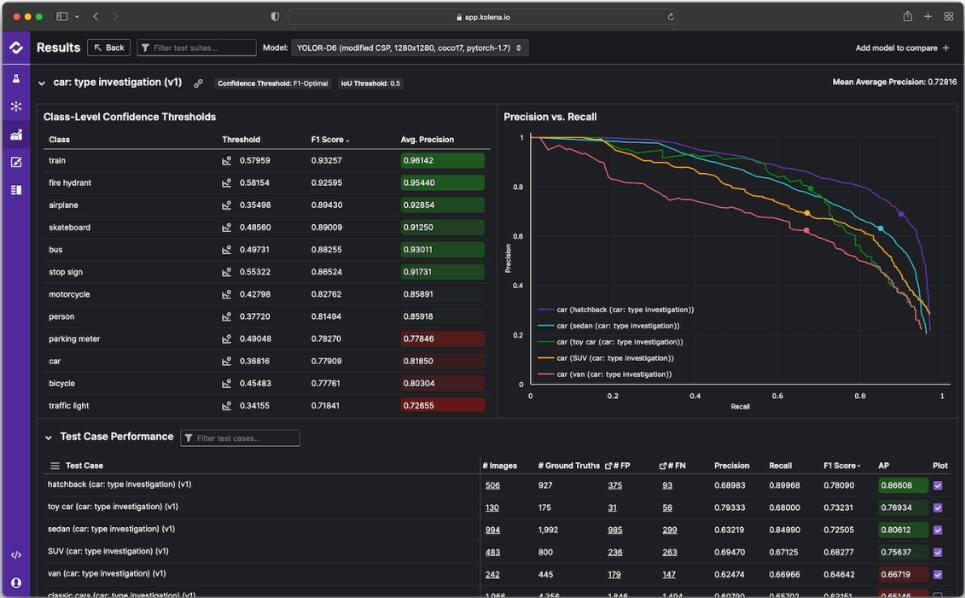
人工智能初创企业Kolena日前宣布完成B轮融资,融资金额1500万美元,由风险投资公司LobbyCapital领投,SignalFire和BloombergBeta跟投。本轮融资使Kolena至今募资总额达到2100万美元。资金将用于扩大研发团队和业务规模。图片来源:科莱娜站长网2023-09-27 10:09:040000