直逼GPT-4开源模型大泄漏,AI社区炸锅!Mistral CEO自曝是旧模型,OpenAI再败一局?
【新智元导读】这几天引发了AI社区大讨论的逼近GPT-4性能的泄漏模型「miqu」,的确是Mistral公司训练的一个旧模型的量化版。此前,冲上各大榜单的这个开源模型引发开发者热议,开源AI或已进入关键时刻。
破案了!
让众多网友抓心挠肝的开源新模型「miqu」,的确是Mistral训练模型的一个旧的量化版本,是在Llama2上重新训练的。
今天,Mistral CEO亲口确认了这一点。
CEO表示,模型是一位「过于热情的员工」从「抢先体验的客户」那里泄漏的。
过去几天,引起AI社区热烈讨论的这桩「悬案」,终于有了答案。
神秘模型泄漏
事情是这样的。
1月28日,一位名为「miqudev」的用户,在HuggingFace上发布了一组文件,这些文件共同构成了一个看似全新的开源LLM,名为「miqu-1-70b」。
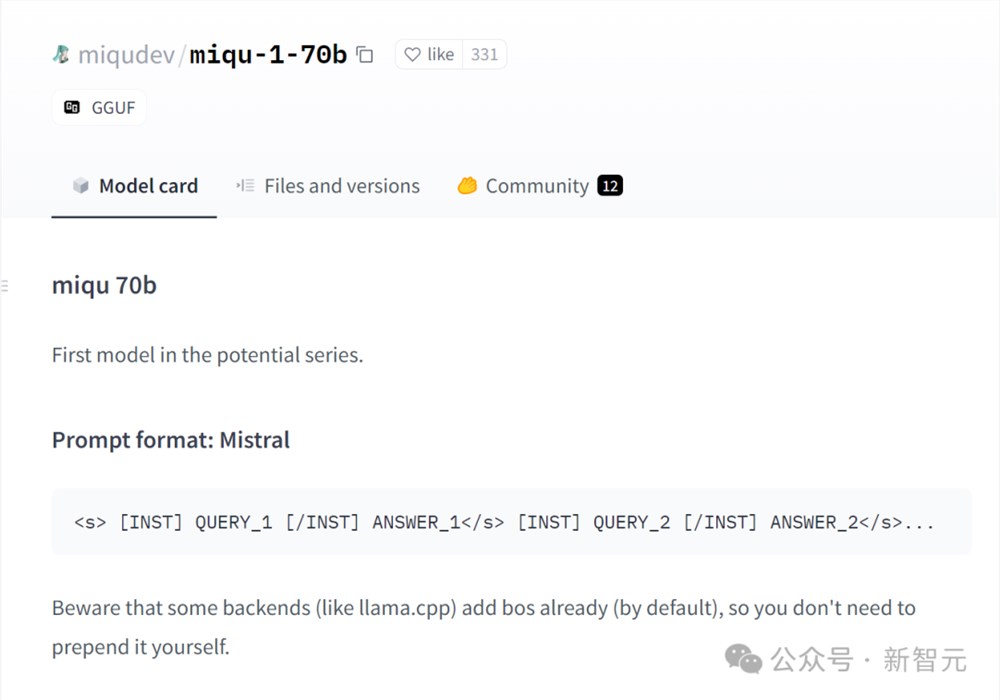
奇怪的是,网友们在HuggingFace条目中发现,这个新模型的提示格式跟Mistral完全相同。
随后,「miqu-1-70b」的链接,又在4chan上泄漏了。
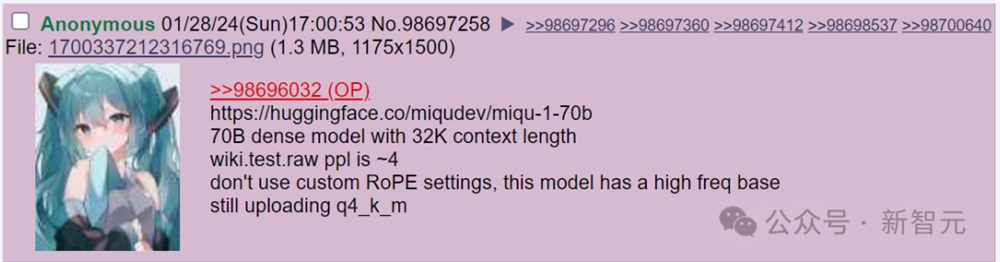
发布链接的,是4chan上的一位匿名用户,大家推测他极有可能是就「miqudev」。
随后,X上的网友们奔走相告,因为他们发现,miqu-1-70b的性能实在是太强了!
在EQ-Bench基准测试上,它甚至已经接近了之前的模型王者——GPT-4。
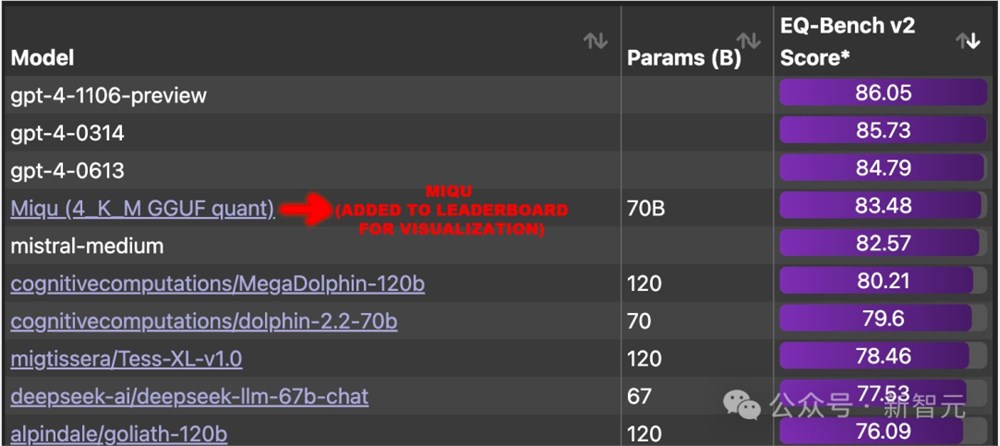
网友们百思不得其解,为什么这个神秘的新模型能击败Mistral Medium,接近GPT-4。
干脆有人提议,不如用EQ-Bench检查下,miqu的数据集是不是被污染了。
miqu模型真面目, 是Mistral还是Llama?
为了确定「miqu」的真实身份,有网友向Mistral-Medium和miqu发送了同一个俄语问题。
结果发现,两个模型的回答竟然是一模一样的俄语。
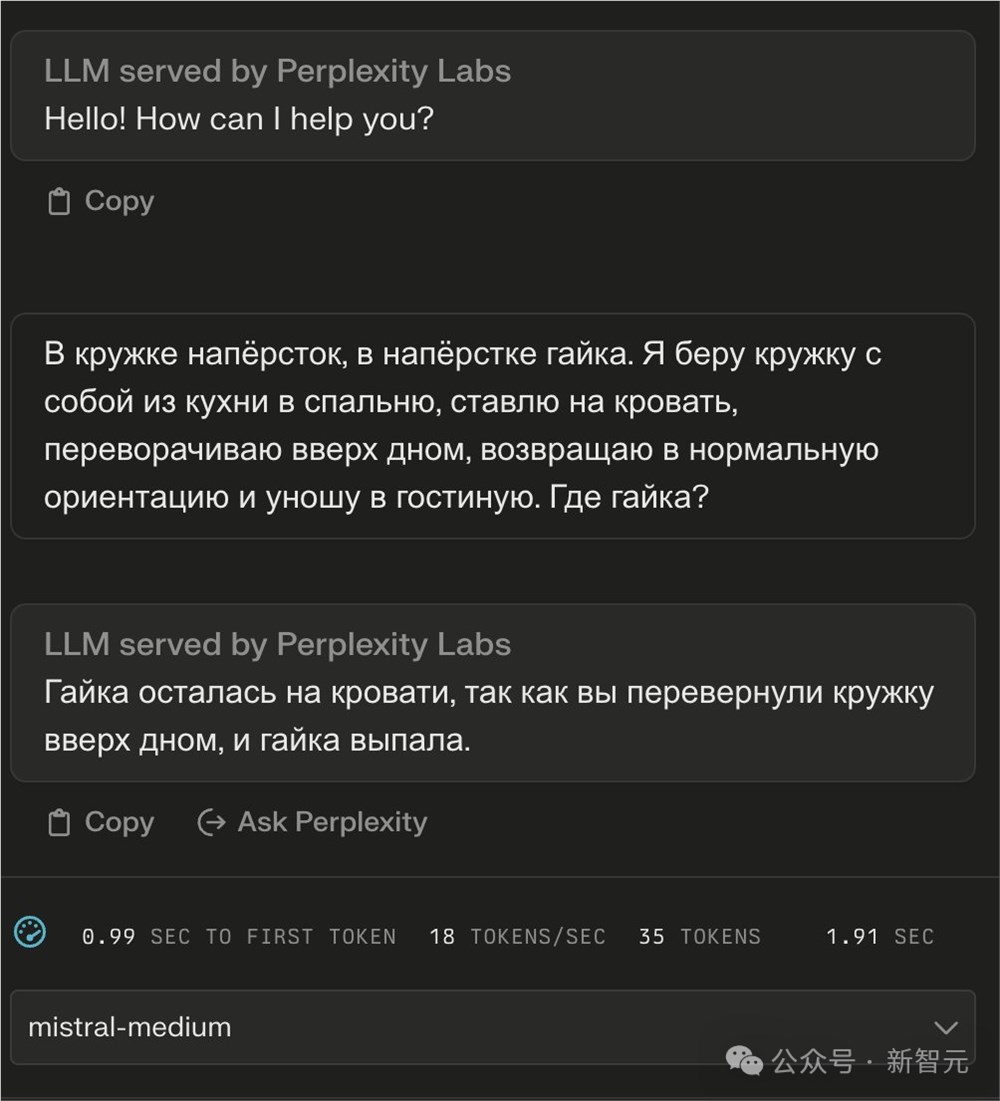
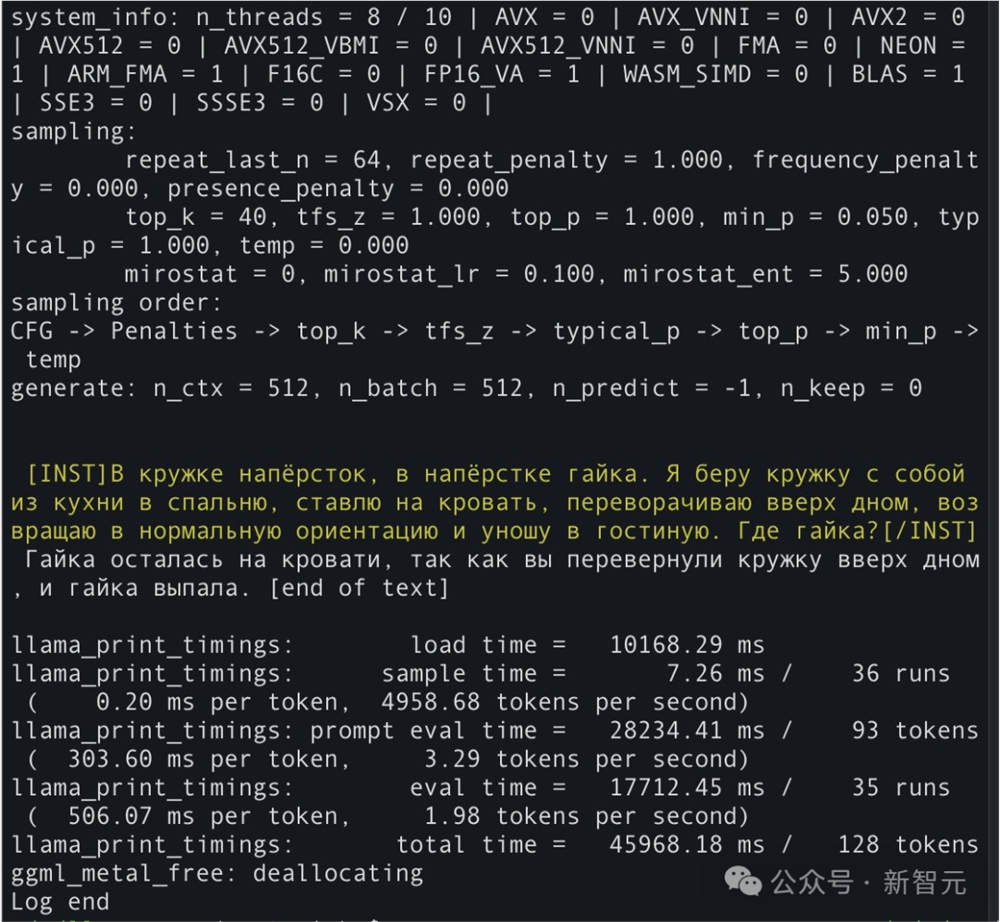
最后,他得出结论——我现在100%相信miqu就是Mistral-Medium。

更有网友熬夜进行了测试,比较了miqu和Mixtral模型的能力。

结果发现,miqu与Mixtral的确非常相似,无论在德语拼写和双语语法上,还是回复中的一些语言习惯上。
总的来说,miqu的表现优于Mistral Small和Medium,逊于Mixtral8x7B Instruct。
因此,miqu可能是Mistral模型的泄漏版本,一个较旧的概念验证模型。
当然,也有部分开发者认为,miqu更像Llama70B,而不是专家混合模型。

综合当时的推测来看,miqu既可能是Mistral Medium的早期版本,也可能是在Mistral Medium数据集上微调了Llama70B。
Mistral量化版?
随着声浪越来越大,摩根大通的机器学习研究者Maxime Labonne也注意到了这件事。

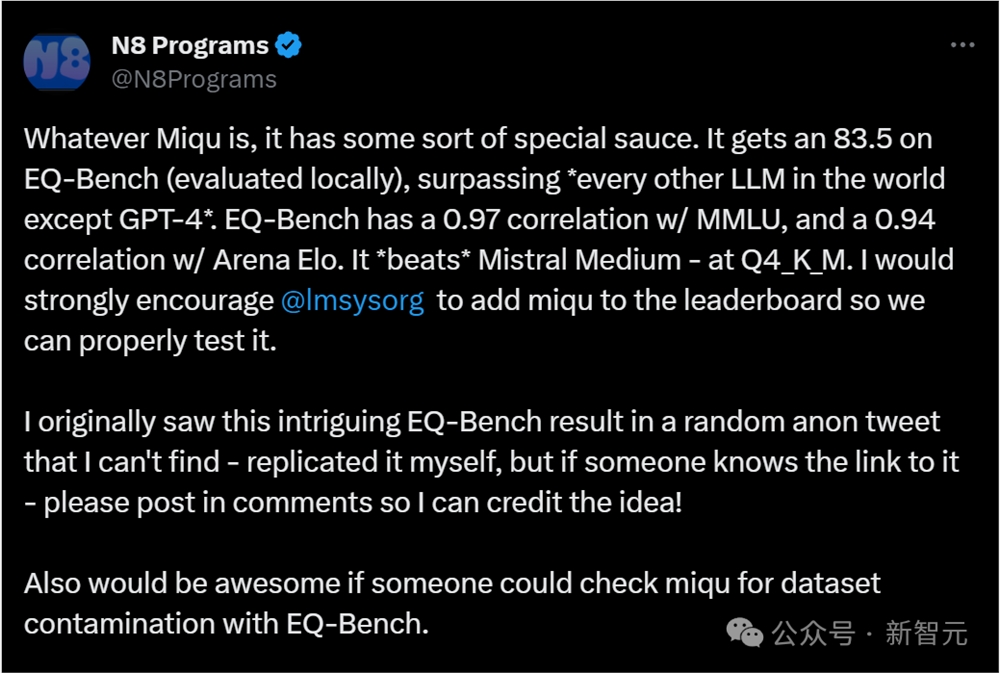
他发帖称,「目前还不确定miqu是否就是Mistral量化版,但可以肯定,它很快就会成为最好的开源LLM之一。」
而且多亏了@152334H,现在大家已经有了一个未量化版本的miqu。
Labonne表示,现在调查还在继续,我们很快就会看到,微调版本的miqu性能会优于GPT-4了!
在机器学习中,量化指的是这种技术,通过用较短的数字序列替换模型架构中的特定长数字序列,使得在功能较弱的计算机和芯片上运行某些AI模型成为可能。
很多人猜,miqu很可能是一种新的Mistral模型,是公司故意要「泄漏」出去的。
毕竟上次的磁力链接事件就表明,Mistral一向有通过深奥的技术手段大张旗鼓地发布新模型的「传统」。
或者,也有可能是员工或者客户泄漏出去的。
CEO确认:没错,它是Mistral的量化版
今天,事情终于水落石出了。
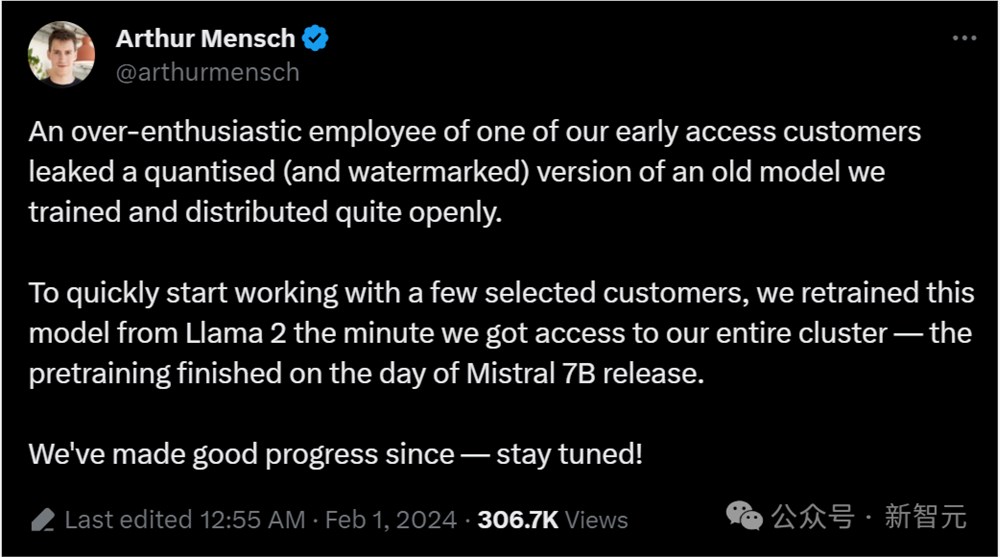
Mistral的联创兼CEO Arthur Mensch在X上澄清道:
我们有一位抢先体验的客户,对接他的过于热情的员工泄漏了我们训练和公开分发的旧模型的量化和水印版本。
为了快速开始与一些选定的客户合作,我们在访问整个集群的那一刻,就从Llama2重新训练了这个模型——预训练在Mistral7B发布当天就完成了。从那以后,我们又不断取得了良好的进展,敬请期待!
有趣的是,CEO并没有要求HuggingFace上的帖子被删除,而是表示发帖人「可能需要考虑归属」。
总之,「敬请期待」这四个字表明,Mistral在训练的,似乎不仅仅是这个接近GPT-4的miqu模型。
开源AI进入关键时刻?
miqu模型的泄漏之所以能引起如此轩然大波,也是因为这件事很可能成为开源生成式AI的分水岭,以及整个AI和计算机科学领域的分水岭。
2022年3月发布的GPT-4,在大多数基准测试中仍然是世界上性能最强的LLM。甚至连谷歌传闻已久的 Gemini都无法超越它。(根据一些测试,目前的 Gemini模型实际上比旧的OpenAI GPT-3.5模型还要差)。
如果现在有一个类似GPT-4性能的模型出来,且能免费商用,就必然给OpenAI及其订阅服务带来巨大的冲击。
尤其是现在越来越多的企业开始寻求开源模型或开源和闭源的混合,来支持自己的应用程序。
靠着GPT-4Turbo和GPT-4V,OpenAI已经竭尽全力保持优势,但开源AI社区的迅速追赶,已经不容忽视了。
OpenAI是否有足够的领先优势,GPT Store和其他功能是否具有护城河,让ChatGPT停留在LLM榜首的位置呢?
参考资料:
https://venturebeat.com/ai/mistral-ceo-confirms-leak-of-new-open-source-ai-model-nearing-gpt-4-performance/
研究称:AI可能已经找到了强大的抗衰老分子
药物发现是一项昂贵且耗时的任务,但机器学习这种人工智能技术可以大大加速这一过程,并以较低的价格完成工作。研究人员使用机器学习技术找到了三种有潜力的抗衰老Senolytics药物候选者,可以延缓衰老并预防与年龄相关的疾病。站长网2023-07-08 14:06:220001巴菲特股东大会:面对 AI 没有选择 必须要去接受它、应对它、使用它
伯克希尔哈撒韦公司年度股东大会日前在奥马哈正式开幕,92岁的巴菲特及多年老搭档99岁的芒格与数万名股东,其中包括数千名中国投资人面对面交流。在近六个小时的问答环节中,回答了各界投资人48个问题,涉及宏观经济、地缘政治、银行业危机、企业经营、家族传承等方方面面。站长网2023-05-08 09:10:260000智能手机避坑指南 | 哪些手机型号千万不要买?主流品牌全汇总
文|小伊评科技马上就要到618了,很多博主包括笔者自己也都出了不少购机攻略,推荐了很多比较值得购买的机型。那么本文就来给大家汇总一下目前手机市场中千万不要入手的手机,帮助大家合理避坑,本文会根据手机品牌来进行罗列。「小米篇」入围机型:红米Note12RPro、小米13Pro、红米Note12Pro极速版、红米Note12Pro、红米K60Pro站长网2023-05-24 16:59:460000LeCun曝多模态LLM重大缺陷 提出Interleaved-MoF显著增强视觉理解能力
要点:多模态大语言模型(MLLM)在视觉处理方面存在重大缺陷,特别是在处理视觉模式上的性能差距明显。研究团队通过将DINOv2特征与CLIP特征结合的方法提升了多模态大模型的视觉功能,创造性地解决了视觉缺陷问题。提出的「交错特征混合(Interleaved-MoF)」方法在MMVP基准中获得了10.7%的能力增强,显著提升了多模态大模型的视觉基础能力。站长网2024-01-18 14:24:390001公众号突然升级“发表”功能,微信想开了?
果酱妹是没想到,这几年一直被问“尚能饭否”的公众号,最近的更新频率能高到仿佛打鸡血。这不,一直翻来覆去试水改了几个星期的发布功能,又双叒叕改了。后台首页大刺刺的“公众号原群发和发布功能已升级为‘发表’”的字样,提醒着运营人们又到了新的适应期了。站长网2023-09-15 09:07:270001