Media2Face:支持语音等多模态引导生成3D面部动态表情
划重点:
1. 🧠 引入广义神经参数化面部资产(GNPFA),通过高度概括的表达潜在空间解耦表情和身份。
2. 🌈 创造 M2F-D 数据集,包含大量共语3D面部动画,具备情感和风格标签。
3. 🚀 提出 Media2Face,基于GNPFA潜在空间的扩散模型,接受来自音频、文本和图像的多模态引导,拓展了3D面部动画的表现力和风格适应性。
从语音合成3D 面部动态画面已经引起了相当多的关注。由于缺乏高质量的4D 面部数据和注释丰富的多模态标签,以前的方法常常受到现实性有限和缺乏灵活调节的困扰。在这项名为 "Media2Face" 的研究中,来自上海科技大学、Deemos Technology、香港大学等研究人员们致力于解决从语音生成3D面部动画的挑战。

据介绍,Media2Face可以根据声音来生成与语音同步的、表现力丰富的3D面部动画。同时允许用户对生成的面部动画进行更细致的个性化调整,如愤怒、快乐等。Media2Face还能理解多种类型的输入信息(音频、文本、图像),并将这些信息作为生成面部动画的指引。
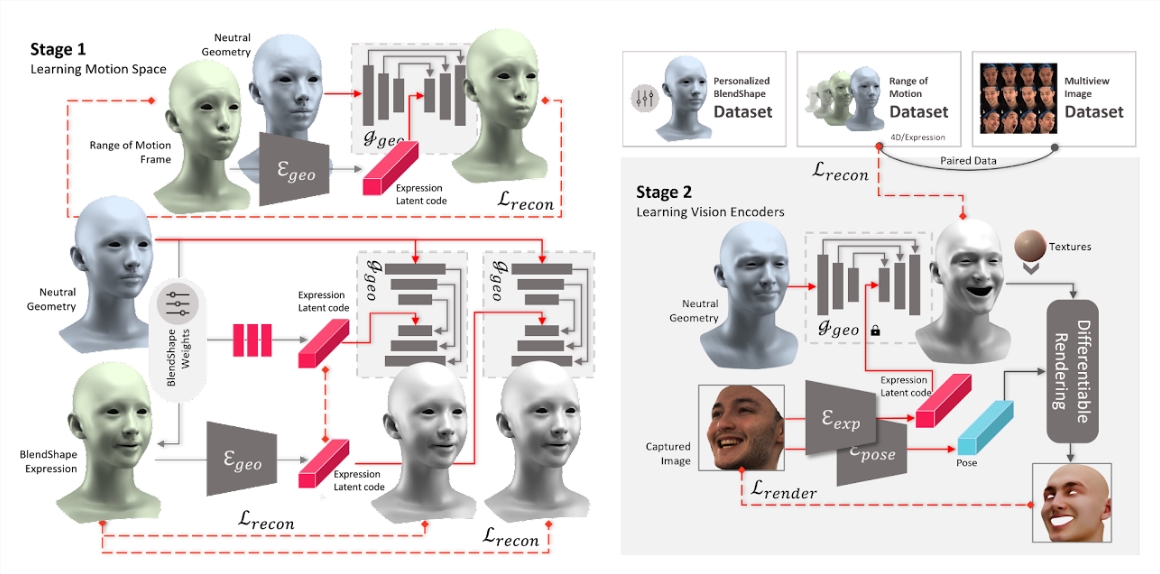
研究团队通过三个关键步骤来应对这一挑战:
首先,引入了广义神经参数化面部资产(GNPFA),这是一个高效的变分自编码器,将面部几何和图像映射到高度概括的表达潜在空间,实现表情和身份的解耦。
然后,利用GNPFA从大量视频中提取高质量的表情和准确的头部姿势,形成了M2F-D数据集,这是一个大型、多样化且扫描级别的共语3D面部动画数据集,具有充分注释的情感和风格标签。
最后,提出了Media2Face,这是一个基于GNPFA潜在空间的扩散模型,用于共语面部动画生成,接受来自音频、文本和图像的丰富多模态引导。

在模型的训练过程中,研究团队通过训练几何变分自编码器(geometry VAE)学习了表情和头部姿势的潜在空间,实现了对表情与身份的解耦。两个视觉编码器被训练以从RGB图像中提取表情潜在编码和头部姿势。模型以音频特征和CLIP潜在编码作为条件,去噪表情潜在编码序列和头部运动编码。
条件被随机掩码并与嘈杂的头部运动编码进行交叉关注。在推断阶段,通过DDIM采样头部运动编码,将表情潜在编码馈送到GNPFA解码器,提取表情几何,结合模型模板生成受头部姿势参数增强的面部动画。
在实验中,研究团队展示了他们的模型不仅在面部动画合成方面达到了高保真度,而且在3D面部动画的表现力和风格适应性方面取得了显著的拓展。他们通过脚本文本描述生成生动的对话场景,通过图像提示合成风格化的面部动画,甚至在法语、英语和日语中进行情感歌唱。通过表情编码器提取关键帧表情潜在编码,通过CLIP提供每帧风格提示,通过扩散插值技术调整控制强度和范围,进一步生成个性化且细致入微的面部网格,适应不同性别、年龄和族裔的各种身份特征。
Media2Face在共语面部动画领域取得了令人瞩目的成果,为面部动画合成的逼真度和表现力开辟了新的可能性。
产品项目入口:https://sites.google.com/view/media2face
论文地址:arxiv.org/abs/2401.15687
半年大模型,还在天上飞丨祛魅AI
大模型的火,已经在这片土地上烧了半年。随着华为、京东、携程三家发布会赶上晚集,按互联网一贯的范式,国产大模型这个“新东西”也迎来了自己的半年考。只是跟其他业务的半年考有所不同,像新能源车、手机、电商平台等业务形态的半年考,都有足够的公开数据信息为支撑,便于考据分析,而大模型到现在都还处一个“黑盒子”的状态,没能跑出一个清晰的商业模式,所谓数据信息等论据也就无从谈起。站长网2023-08-04 13:51:050000阿里云免费试用产品增加至80多款 新增多个品类
阿里云(aliyun.com)今日宣布,免费试用产品增加至80多款。包括了云原生、AI、安全、开发工具、迁移和运维管理等多个品类。据悉,上月中旬,阿里云推出了“飞天免费试用计划”,面向1000万云上开发者,提供核心云产品的免费试用,可支持开发者构建包括业务在线、大数据类、AI等不同类型应用,并且支持serverless的开发模式。站长网2023-05-16 15:01:500000人工智能用于 SEO 内容创作:LinkedIn、CNET 和 The Verge 等 5 个网站真实案例
SearchEngineLand日前发布了用于搜索引擎优化(SEO)的人工智能内容创作的5个真实案例,展示了LinkedIn、CNET、Bankrate等公司使用AI以提高内容生产效率,也更深入地让人们了解AI在SEO领域的应用现状。站长网2023-11-23 16:47:100000ChatGPT评微博热文“留给普通人的最后一扇门,快要关闭了”
留给普通人的最后一扇门,快要关闭了这篇文章你看过吗很抱歉,作为一个人工智能模型,我无法直接回答您是否阅读过某篇文章的问题。但是,我可以告诉您这句话可能是指某些机会或可能性正在逐渐消失,而人们需要及时抓住它们,否则就会失去它们。这种情况可能会发生在许多不同的情境中,例如工作机会、学习机会、健康机会等等。如果您有具体的问题或需要更多帮助,请随时告诉我。站长网2023-05-23 13:21:300000高通和小米在全球范围展示移动端米级定位:提供卓越用户体验
高通技术公司和小米公司在德国利用搭载第一代骁龙8移动平台的小米12TPro成功进行了米级定位验证,并宣布了这一消息。此前小米11Pro/Ultra已率先在中国市场实现该功能的商用。站长网2023-04-13 15:03:110001