200GB!AutoMathText:专注数学文本的超大规模数据集
划重点:
1. 📌AutoMathText是一个200GB的数学文本数据集,包含来自不同来源的科学论文、编程代码片段和网页数据,适用于数学推理、推理训练和微调等多种应用场景。
2. 📌支持文本生成和问答任务,特别适用于开发和测试理解和生成数学相关内容的模型。
3. 📌数据集包含10亿到100亿的数据量级,提供丰富的资源供大规模模型训练。
AutoMathText是一个庞大的数学文本数据集,总体规模达到200GB,汇聚了来自多个来源的数据,包括科学论文、编程代码片段以及网页数据。该数据集经过特定的过滤和处理,旨在服务于数学推理、推理训练和微调等多种应用场景。
AutoMathText专注于文本生成和问答任务,为开发和测试涉及数学推理和推理能力的模型提供了理想的训练资源。模型可以通过这个数据集进行学习,提高对数学相关内容的理解和生成能力。数据集目前仅支持英语,适用于需要大量英文训练数据的场景。这有助于研究人员和开发者在英语环境中训练和评估模型。
AutoMathText的数据量级在10亿到100亿之间,为大规模模型训练提供了丰富的资源。这对于开发大型、高性能的数学模型具有重要意义。
数据集包含了不同来源和不同过滤条件下的数据子集,包括来自arXiv的科学论文、编程代码片段以及网页数据。这些子集的多样性使其适用于多种不同的训练和测试需求。AutoMathText提供了详细的领域标签,涵盖数学推理、推理、微调等方面。这有助于用户精确挑选符合特定任务需求的数据,提高模型的训练效果。
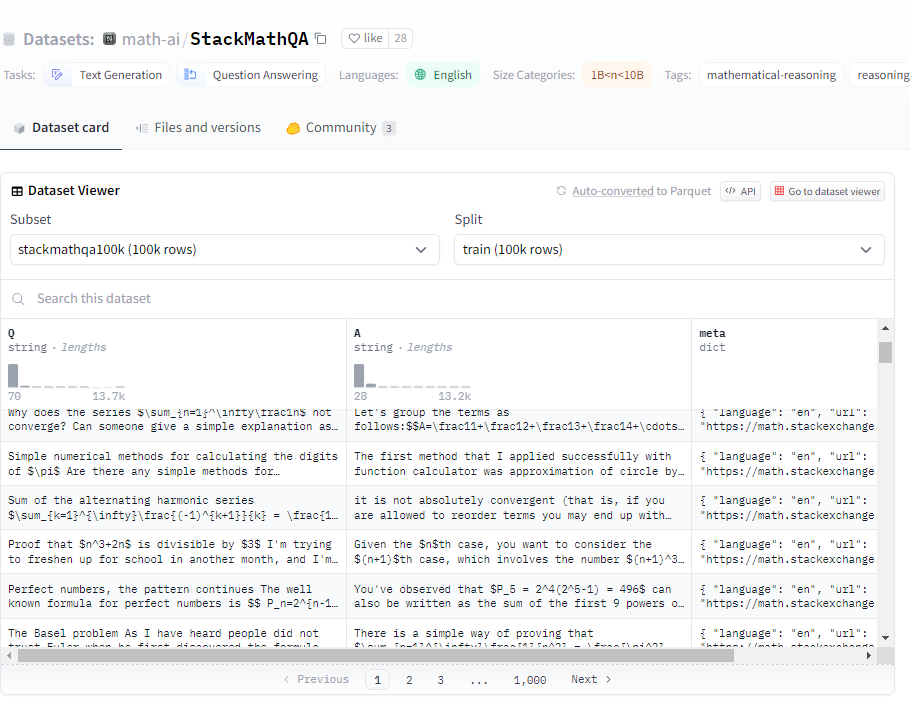
此外,AutoMathText的姊妹数据集StackMathQA汇集了200万个数学问题和答案,为AI提供了一个庞大的习题集,有助于训练模型更好地理解和解决数学问题。 StackMathQA的集合是由数学问题和对应答案组成,提供了更具挑战性的数学任务,为模型的进一步发展提供了支持。
数据集入口:https://huggingface.co/datasets/math-ai/StackMathQA
月入上万元!互联网思维下的00后家政“卷”起来了
以往我们提起家政行业,会将其定义为低技能、低门槛;提起从业人员,总是能想到年龄偏大、文化水平不高,赚着辛苦钱的弱势群体;提到业务来源,印象几乎停留在中介的小广告上。但令人没想到的是,现在,越来越多的年轻人开始加入家政行业,其中不乏00后。江苏泰州,一个22岁的女孩转行做家政经纪人,据她所说,正常月收入平均下来是在8000到9000元。0000QQ音乐回应涨价:针对之前优惠价格用户
针对“绿钻豪华版自动续费将涨价”一事,QQ音乐客服回应称,此次是针对之前有优惠价格的用户涨价,优惠到期后,11.4元一个月会涨回15元一个月。此前,QQ音乐宣布绿钻豪华版的微信自动续费服务将涨价,从原来的11.4元/月涨至15元/月。涨价将从2024年1月9日0点开始生效。对于已经开通了自动续费的用户,他们将会收到微信的提醒,可以选择在该时间之前取消自动续费,以避免涨价的影响。站长网2023-12-05 08:18:580000GPT-4o恩怨开局,Google再次躺枪
要说全世界戏最多的AI,非OpenAI莫属。这家公司简直就是热搜制造机,刚推出新产品,就送走老领导,刚和苹果结盟,就逼跌谷歌股价;连OpenAI高管的一个离职动态,都能引发网上的OpenAI离职潮。短短几天时间,以OpenAI为中心,接连引发地震级别的事件。不仅可能对OpenAI这家公司的未来产生重大影响,甚至有可能导致整个科技行业的重新洗牌。仅凭语音对话就撑起无限可能的GPT-4o站长网2024-05-20 13:51:500000微信撒狗粮限定状态上线 并开放七夕520红包
今天是中国古老的七夕节,微信为了庆祝这个浪漫的节日,不仅在红包功能上做了特别的优化,把单个红包的最高金额提升到520元,还推出了两款专属于七夕的状态:“吃狗粮”和“撒狗粮”。站长网2023-08-22 10:15:130000成立不到一年 生成式AI初创公司 Mistral AI 估值接近 20 亿美元
站长之家(ChinaZ.com)12月7日消息:据知情人士透露,法国生成式人工智能初创公司MistralAI即将完成约4.5亿欧元的融资。与刚刚筹集了类似资金的德国AlephAlpha不同,大多数投资者来自非洲大陆以外的地区。此轮融资由硅谷风险投资公司AndreessenHorowitz领投,Nvidia和Salesforce也提供支持。0000