谷歌再雪前耻,新Bard逆袭GPT-4冲上LLM排行榜第二!Jeff Dean高呼我们回来了
【新智元导读】谷歌Bard又行了?在第三方LLM「排位赛」排行榜上,Bard击败GPT-4成为第二名。Jeff Dean兴奋宣布:谷歌回来了!
一夜之间,Bard逆袭GPT-4,性能直逼最强GPT-4Turbo!
这个听起来似乎像梦里的事情,确确实实地发生了。
就在昨天,谷歌首席Jeff Dean发推提前透露了谷歌的最新版模型——Gemini Pro-scale。
基于此,Bard相较于3月份的首次亮相,不仅在表现上有了显著的提升,而且还具备了更多的能力。

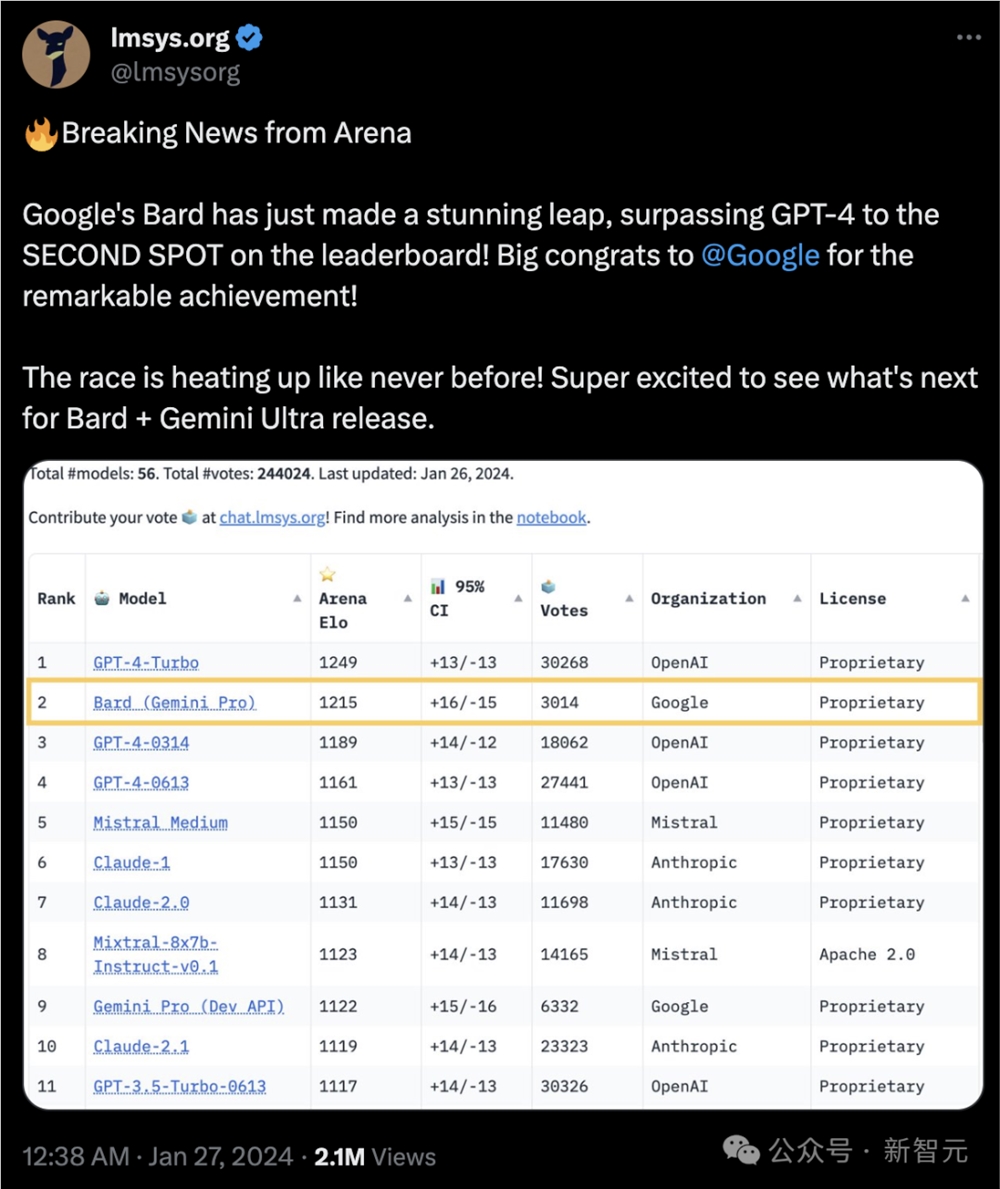
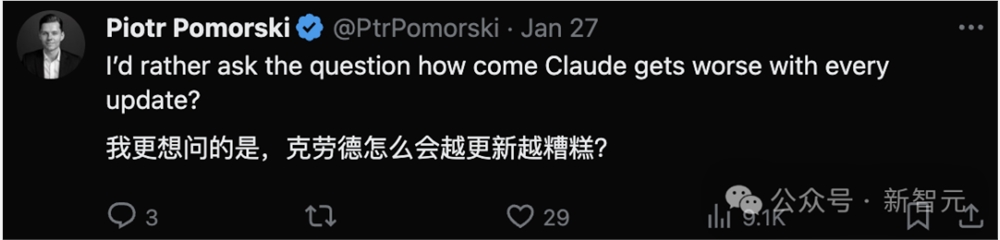
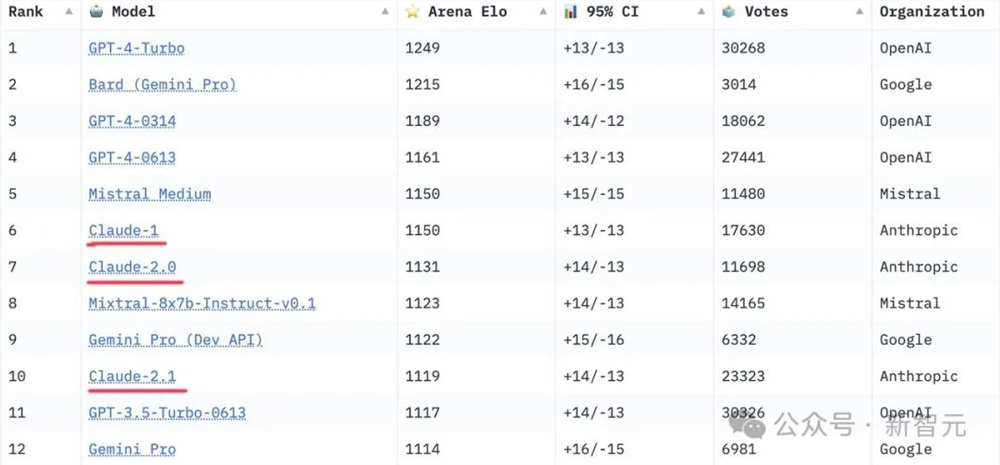
可以看到,在最新的Gemini Pro-scale加持下,Bard直接蹿升到了排行榜第二名的位置。
一口气把之前的两款GPT-4模型斩于马下,甚至和排名第一的GPT-4Turbo的差距也非常小。
虽然Jeff Dean并没有具体阐述「scale」的含义,但从名称上推测,很可能是一个比初代Gemini Pro规模更大的版本。
而根据前段时间外媒曝出的内部邮件,搭载Gemini Ultra的Bard Advanced已经全面开放给谷歌员工试用。
也就是说,距离谷歌最强模型的上线,已经不远了。

随着谷歌对Gemini Pro更新后不断大幅上涨的表现,也让所有人对完全体Gemini Ultra的能力有了更多的期待。
不过,新推出的Bard目前只接受了约3,000次评价,而GPT-4的评价次数已高达30,000次。因此,这个结果后续很可能还会发生变动。
但不管怎样,这对于谷歌来说是一项令人瞩目的成就,也让人对即将发布的、预期将超过Gemini Pro-Scale性能的最强AI模型Gemini Ultra充满期待。
谷歌Bard超越GPT-4跃居第二
简单介绍一下,这个由UC伯克利主导,CMU,UCSD等顶级高校共同参与创建的聊天机器人竞技场「Chatbot Arena」,是学术圈内一个很权威的大模型对话能力排行榜。
榜单通过类似Moba游戏中的「排位赛」机制,让各家大模型通过PvP的方式来排出性能高低。
期间,用户会与模型(不知道具体型号)进行互动,并选择他们更喜欢的回答。而这些投票将会决定模型在排行榜上的名次。
这种方式能够有效地避免很多PvE基准测试中可能出现的,通过「刷题」来提高成绩的问题,被业界认为是一个比较客观的大模型能力排行榜。
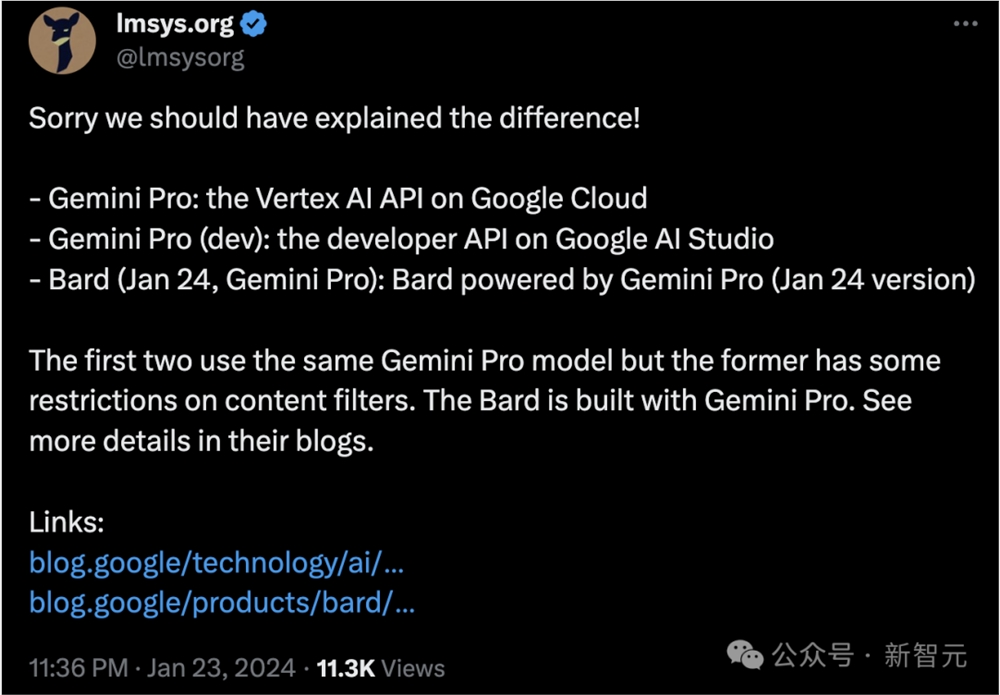
为了便于区分,LMSYS Org指出,目前Gemini Pro市面上总共有3个版本:
- Gemini Pro API:用户可以通过谷歌云的Vertex AI API进行访问
- Gemini Pro(dev)API:开发者API可以通过谷歌 AI Studio进行访问
- Bard(1月4日更新的Gemini Pro):是目前唯一可以访问到1月24日更新的Gemini Pro的方式
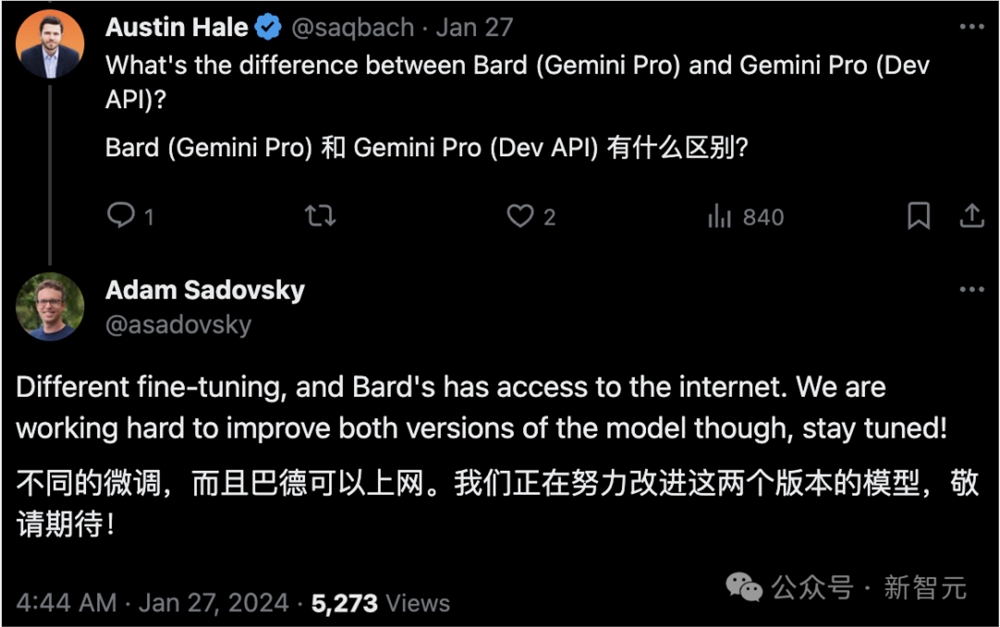
同时,谷歌Bard项目的高级总监Sadovsky也透露,排行榜上的Bard和Gemini Pro(API)是两个在微调层面不同的模型,而且Bard可以检索互联网上的信息。
在ChatBot Arena中,1月24号更新的Bard由于支持检索互联网,相比于之前放出的Gemini Pro(API)对于实时信息问题的回复提升巨大。

从谷歌的这波更新可以看出,Gemini Pro的潜力似乎远远没有被完全释放,希望谷歌能再接再厉,对OpenAI一家独大的格局形成挑战。
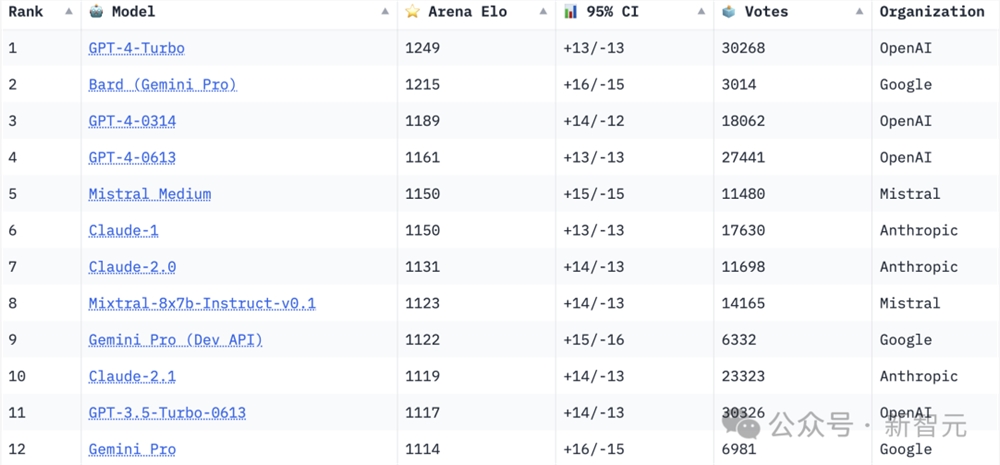
以下是1月14号更新的Bard在ChatBot Arena中的成绩的明细:

模型A相对于模型B在所有非平局对决中获胜的比例

不同模型组合间对决的次数统计(排除平局情况)
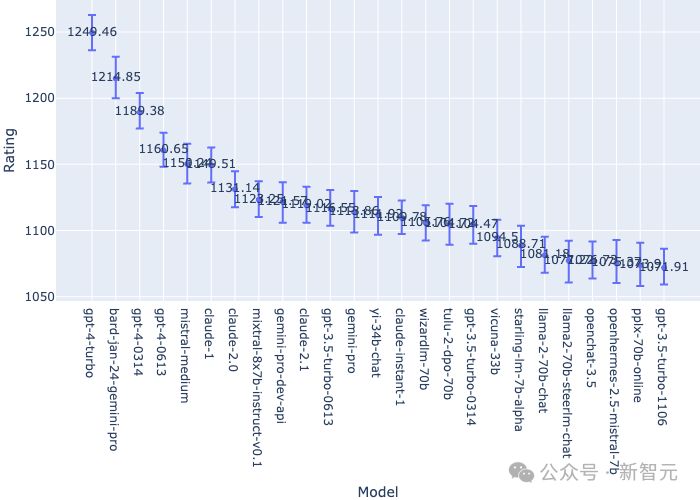
通过1000轮随机抽样对Elo评分进行的自举法(Bootstrap)估计
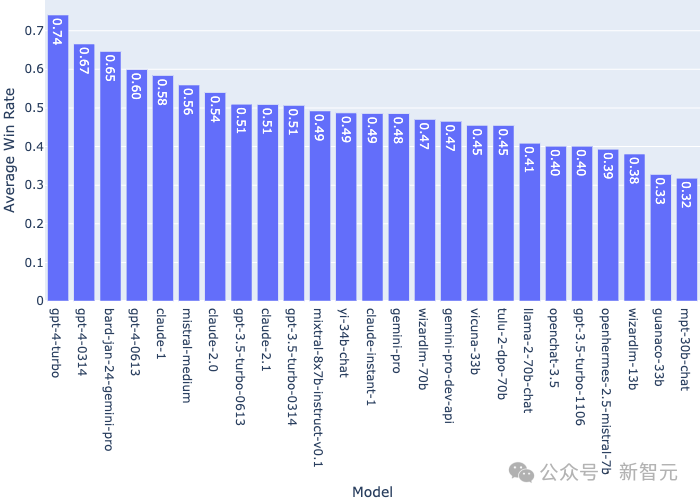
在假设等概率抽样和不存在平局的情况下,相对于所有其他模型的平均胜率
Elo评分系统
Elo等级分制度(Elo rating system)是一种计算玩家相对技能水平的方法,广泛应用在竞技游戏和各类运动当中。其中,Elo评分越高,那么就说明这个玩家越厉害。
比如英雄联盟、Dota2以及吃鸡等等,系统给玩家进行排名的就是这个机制。
举个例子,当你在英雄联盟里面打了很多场排位赛后,就会出现一个隐藏分。这个隐藏分不仅决定了你的段位,也决定了你打排位时碰到的对手基本也是类似水平的。
而且,这个Elo评分的数值是绝对的。也就是说,当未来加入新的聊天机器人时,我们依然可以直接通过Elo的评分来判断哪个聊天机器人更厉害。
具体来说,如果玩家A的评分为Ra,玩家B的评分为Rb,玩家A获胜概率的精确公式(使用以10为底的logistic曲线)为:
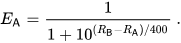
然后,玩家的评分会在每场对战后线性更新。
假设玩家A(评分为Ra)预计获得Ea分,但实际获得Sa分。更新该玩家评分的公式为:
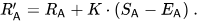
网友热议
对此,网友提问:现在能够访问的Bard就是这个排名第二的Bard了吗?
谷歌官方回复,是的,而且现在访问的Bard比排行榜的上的Bard还能支持更多的像地图扩展等应用。

不过还是有网友吐槽,即使在PvP排行榜上Bard已经取得了很好的成绩,但是对于理解用户需求和解决实际问题的能力,Bard和GPT-4依然还有很大差距。

也有网友认为,用能联网的Bard和离线的GPT-4打有失公平。甚至,就这样还没打过……
而最有意思的,还要数网友在排行榜中发现的「华点」了:号称是GPT-4最大竞品的Claude居然越更新越弱了。
对此,之前有分析认为,Anthropic一直在大力发展的与人类对齐,会严重影响模型的性能。
GPT-4Turbo超长上下文A/B测试
有趣的是,这个连Jeff Dean都亲自下场的「刷榜」,正巧就在OpenAI连发5款新模型的第二天。
根据OpenAI的介绍,新版GPT-4Turbo——gpt-4-0125-preview,不仅大幅改善了模型「偷懒」的情况,而且还极大地提升了代码生成的能力。
不过,正如大家对Bard的怀疑,GPT-4这次到底有没有变强也有待验证。

对此,AI公司Smol的创始人Shawn Wang,就在超过100k单词的超长上下文中,对比测试了新旧GPT4-Turbo的总结能力。
Wang表示,两次测试使用的是完全相同提示词,以及基本相同的语料库。
虽然没有严格严格,但每个模型都进行了超过300次的API调用,因此对于总结任务而言,这一结果还是具有一定参考价值的。

结果显示,2024年1月的GPT4-Turbo花费了19分钟来生成20,265个单词,相比之下,2023年11月的用16分钟生成了18,884个单词。
也就是说,新模型的生成速度大约慢了18%,且生成文本的长度平均偏长约7%。
质量方面:
-2024年1月的模型在主题选择上略有改善,但仍存在问题
-2023年11月的模型会产生更多错误信息
-2024年1月的模型在总结中添加小标题的能力略有提升
-2024年1月的模型出现了一次严重的格式错误,而这在之前是极为罕见的
-2023年11月的模型文本详情更加丰富
总体而言,新版GPT4-Turbo在总结这一应用场景上有所退步。




左侧:2023年11月;右侧:2024年1月(左右滑动查看全部)
OpenAI最后的「开源遗作」两周年
不得不说,AI领域的发展过于迅猛,甚至让人对时间的流速都产生了错觉。
今天,英伟达高级科学家Jim Fan发推纪念了InstructGPT发布二周年。

在这里,OpenAI定义了一套标准流程:预训练 -> 监督式微调 -> RLHF。直到今天,这依然是大家遵循的基本策略(尽管有些许变化,比如DPO)。
它不仅仅是大语言模型从学术探索(GPT-3)到转化为具有实际影响力的产品(ChatGPT)的关键转折点,而且也是最后一篇OpenAI详细说明他们如何训练前沿模型的论文。

论文地址:https://arxiv.org/abs/2203.02155
- InstructGPT在2022年的NeurIPS会议上首次亮相,但它并不是RLHF的发明者。实际上,相关博客将读者引向了OpenAI团队在2017年完成的原始RLHF研究。
这项研究最初的目的是解决模拟机器人领域中难以明确定义的任务——通过一名人类标注者提供的900个二选一偏好,RLHF让一个简单的「跳跃」机器人在模拟环境中学会了后空翻。

论文地址:https://arxiv.org/abs/1706.03741v4
- 模型提供了三种规模:1.3B、6B、175B。与旧的、需要复杂提示设计的GPT-3-175B相比,标注者明显更喜欢Instruct-1.3B。微软最知名的「小模型」Phi-1也是1.3B。
- InstructGPT展示了如何精彩地呈现研究成果。三个步骤的图表清晰易懂,并且成为AI领域最标志性的图像之一。引言部分直接了当,用粗体突出了8个核心观点。对局限性和偏见的讨论实事求是、坦诚直接。
OpenAI新任CEO Emmett Shear是谁?或使公司危机加深
**划重点:**1.🌟EmmettShear被任命为OpenAI的新首席执行官,此前曾是全球最大的视频流媒体公司Twitch的首席执行官。2.⚡在员工和投资者支持前OpenAI领导人SamAltman之后,OpenAI的危机在董事会任命EmmettShear为新CEO后加深。站长网2023-11-20 14:42:450000AI日报:王炸!ElevenLabs推声音设计功能;全能型图像生成模型OmniGen问世;快50倍!OpenAI推全新模型sCM
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/1、ElevenLabs推出AI语音生成工具VoiceDesign站长网2024-10-24 16:32:540000Redmi K70系列宣布明天OTA升级!手机屏幕频闪更低更护眼
快科技12月14日消息,今日晚间,Redmi市场总经理王腾宣布,明天开始正式推送OTA升级,升级后RedmiK70系列的SVM值将做到0.1以内,让SVM值比友商更低。另外,王腾还对屏幕SVM、SVM测试方法进行了详细科普。据介绍,SVM是照明协会的认证数值,1以下即是符合护眼规范,以往照明设备会有频率闪烁问题,而且是整面照明同步亮同步暗的状态。0000小米宣布小爱同学、小爱音箱升级AI大模型 已开启邀请测试
在昨日晚间的年度发布会上,小米宣布小爱同学已实现全新升级,正式接入大模型。升级后的小爱同学拥有一个更加强大的大脑,可以答疑解惑、激发灵感、创造艺术,还能扮演角色进行自然对话。小米表示,升级至MIUI14后,本次内测机型会分三批进行支持,第二批和第三批邀测时间将于后续公布,用户可在「小米社区APP-右下角“我的”-内测中心」中报名。具体情况如下:第一批(8月14号起陆续审核)站长网2023-08-15 08:53:390001模型未发API先至!Stable Diffusion 3 API 发布 性能比肩 Midjourney v6
StabilityAI最近宣布了一个激动人心的消息:其开发者平台API现已支持最新版本的StableDiffusion3(SD3)及其增强版本StableDiffusion3Turbo。这一发布标志着StabilityAI在文字到图像生成领域的技术进步,其性能已经达到甚至超越了行业内的一些领先模型,如DALL-E3和Midjourneyv6。站长网2024-04-19 01:36:080000










