世界顶尖多模态大模型开源!又是零一万物,又是李开复
领跑中英文两大权威榜单,李开复零一万物交出多模态大模型答卷!
距离其首款开源大模型Yi-34B和Yi-6B的发布,仅间隔不到三个月的时间。

模型名为Yi Vision Language(Yi-VL),现已正式面向全球开源。
同属Yi系列,同样具有两个版本:
Yi-VL-34B和Yi-VL-6B。
先来看两个例子,感受一波Yi-VL在图文对话等多元场景中的表现:

Yi-VL对整幅图做了详细分析,不仅说明了指示牌上的内容,甚至连“天花板”都有照顾到。
中文方面,Yi-VL也能清晰有条理地准确表达:

此外,官方也给出了测试结果。
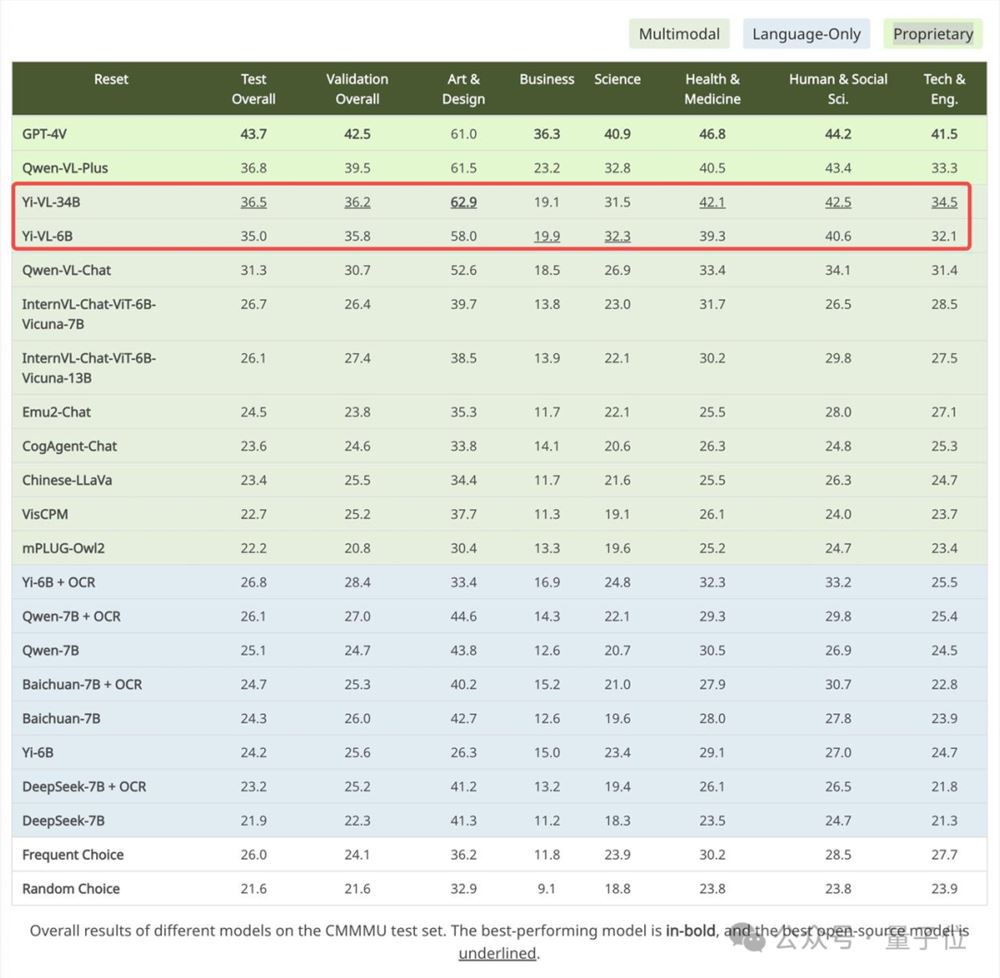
Yi-VL-34B在英文数据集MMMU上准确率41.6%,仅次于准确率55.7%的GPT-4V,超越一系列多模态大模型。
而在中文数据集CMMMU上,Yi-VL-34B准确率36.5%,领先于当前最前沿的开源多模态模型。
Yi-VL长啥样?
Yi-VL基于Yi语言模型研发,可以看到基于Yi语言模型的强大文本理解能力,只需对图片进行对齐,就可以得到不错的多模态视觉语言模型——这也是Yi-VL模型的核心亮点之一。
在架构设计上,Yi-VL模型基于开源LLaVA架构,包含三个主要模块:
Vision Transformer(简称ViT)用于图像编码,使用开源的OpenClip ViT-H/14模型初始化可训练参数,通过学习从大规模”图像-文本”对中提取特征,使模型具备处理和理解图像的能力。
Projection模块为模型带来了图像特征与文本特征空间对齐的能力。该模块由一个包含层归一化(layer normalizations)的多层感知机(Multilayer Perceptron,简称MLP)构成。这一设计使得模型可以更有效地融合和处理视觉和文本信息,提高了多模态理解和生成的准确度。
Yi-34B-Chat和Yi-6B-Chat大语言模型的引入为 Yi-VL 提供了强大的语言理解和生成能力。该部分模型借助先进的自然语言处理技术,能够帮助Yi-VL深入理解复杂的语言结构,并生成连贯、相关的文本输出。

△图说:Yi-VL模型架构设计和训练方法流程一览
在训练方法上,Yi-VL模型的训练过程分为三个阶段,旨在全面提升模型的视觉和语言处理能力。
第一阶段,使用1亿张的“图像-文本”配对数据集训练ViT和Projection模块。
在这一阶段,图像分辨率被设定为224x224,以增强ViT在特定架构中的知识获取能力,同时实现与大型语言模型的高效对齐。
第二阶段,将ViT的图像分辨率提升至448x448,让模型更加擅长识别复杂的视觉细节。此阶段使用了约2500万“图像-文本”对。
第三阶段,开放整个模型的参数进行训练,目标是提高模型在多模态聊天互动中的表现。训练数据涵盖了多样化的数据源,共约100万“图像-文本”对,确保了数据的广泛性和平衡性。
零一万物技术团队同时也验证了可以基于Yi语言模型强大的语言理解和生成能力,用其他多模态训练方法比如BLIP、Flamingo、EVA等快速训练出能够进行高效图像理解和流畅图文对话的多模态图文模型。
Yi系列模型可以作为多模态模型的基座语言模型,给开源社区提供一个新的选项。同时,零一万物多模态团队正在探索从头开始进行多模态预训练,更快接近、超过GPT-4V,达到世界第一梯队水平。
目前,Yi-VL模型已在Hugging Face、ModelScope等平台上向公众开放,用户可亲身体验这款模型在图文对话等多元场景中的表现。
超越一系列多模态大模型
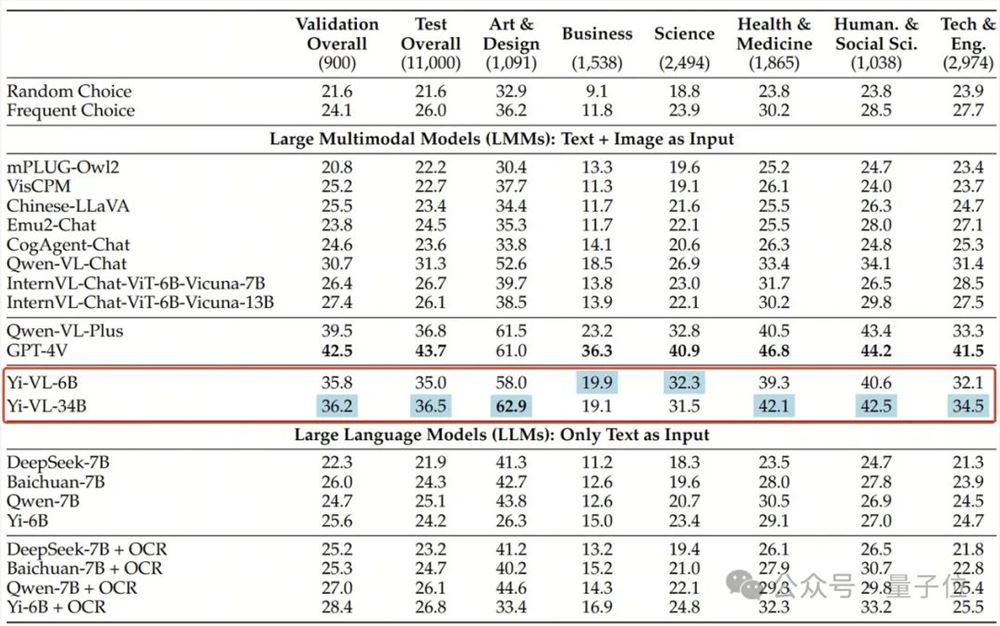
在全新多模态基准测试MMMU中,Yi-VL-34B、Yi-VL-6B两个版本均有不俗表现。
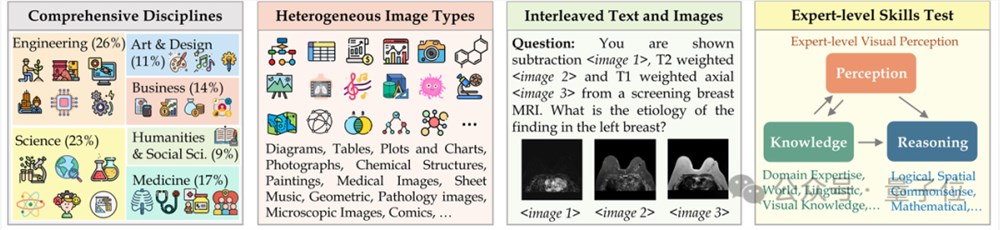
MMMU(全名Massive Multi-discipline Multi-modal Understanding & Reasoning 大规模多学科多模态理解和推理)数据集包含了11500个来自六大核心学科(艺术与设计、商业、科学、健康与医学、人文与社会科学以及技术与工程)的问题,涉及高度异构图像类型和交织文本图像信息,对模型的高级知觉和推理能力提出了极高要求。
而Yi-VL-34B在该测试集上以41.6%的准确率,成功超越了一系列多模态大模型,仅次于GPT-4V(55.7%),展现出强大的跨学科知识理解和应用能力。

同样,在针对中文场景打造的CMMMU数据集上,Yi-VL模型展现了“更懂中国人”的独特优势。
CMMMU包含了约12000道源自大学考试、测验和教科书的中文多模态问题。

其中,GPT-4V在该测试集上的准确率为43.7%, Yi-VL-34B以36.5%的准确率紧随其后,领先于当前最前沿的开源多模态模型。
项目地址:
[1]https://huggingface.co/01-ai
[2]https://www.modelscope.cn/organization/01ai
—完—
研究发现:ChatGPT在回答患者用药问题方面表现不佳
**划重点:**1.📉研究发现ChatGPT在回答关于药物的患者问题时,答案错误或不完整的情况达到了75%。2.🚨研究警告提供者要警惕,因为很多患者可能转向ChatGPT寻求与健康相关的问题的答案。3.🤖ChatGPT免费版拥有超过1亿用户,研究建议医疗提供者要注意该生成式AI模型并非始终提供可靠的医学建议。0001图文带货迎来新机遇,利好广大抖音电商作者
抖音电商新机遇在图文带货领域显现。抖音电商官方数据显示,2023年上半年,电商短视频日均播放次数同比增长19.4%,电商直播间日均开播时长同比增长31.7%,图文带货内容日均播放次数增长了728.1%,增幅超短视频与直播这两个内容体裁。站长网2023-10-10 14:00:020000抖音货架到底值不值得做?服务商:我们准备放弃了......
为了货架电商,抖音投入百亿扶持,将其当做最重要的运营方向。但某入局了货架电商的服务商,却说“要放弃了”。近期,某抖音服务商跟新播场分享了他们做抖音货架电商的经历。他表示,综合来看,无论是现在被鼓吹的商品卡,还是行业讨论了很久的商城,对于他们而言很难有增长效果。实际上,如今行业内不看好抖音货架电商的还大有人在,问题大多围绕在价格内卷、会让兴趣电商失去竞争力等。站长网2023-07-06 22:09:460002陈香贵开始猛扑抖音同城
抖音同城在今年已经成为餐饮界热议的话题。而去年抖音的同城生活部门还在小步摸索,今年就异军突起,甚至打破了传统同城“人货场”模式,开创了一条全新的内容型同城电商新赛道。背后的逻辑是,传统本地生活电商平台,如阿里、美团和大众点评,流量主要局限在周围3公里范围内。抖音则利用内容的先天优势,将广告型内容巧妙融入用户时间,通过创意而有趣的内容激发用户兴趣,再通过优惠券进行转化交易。站长网2023-08-26 17:25:460000零一万物发布 Yi 大模型 API 并启动公测:支持上下文 200K
零一万物发布了Yi大模型API,并启动了公测。这次邀测提供了两种模型:Yi-34B-Chat(0205)和Yi-34B-Chat-200K。站长网2024-02-27 10:12:490000