零一万物Yi-VL多模态语言模型上线 包括Yi-VL-34B、Yi-VL-6B两个版本
零一万物 Yi-VL 多模态语言模型是零一万物 Yi 系列模型家族的新成员,它在图文理解和对话生成方面具备卓越的能力。Yi-VL 模型在英文数据集 MMMU 和中文数据集 CMMMU 上都取得了领先成绩,展示了在复杂跨学科任务上的实力。
Yi-VL 模型分为 Yi-VL-34B 和 Yi-VL-6B 两个版本,它们在全新多模态基准测试 MMMU 中表现出色。MMMU 数据集包含了来自六大核心学科的11500个问题,涉及多种异构图像类型和交织的文本图像信息。Yi-VL-34B 在该测试集上以41.6% 的准确率超越了一系列多模态大模型,仅次于 GPT-4V,展现了强大的跨学科知识理解和应用能力。
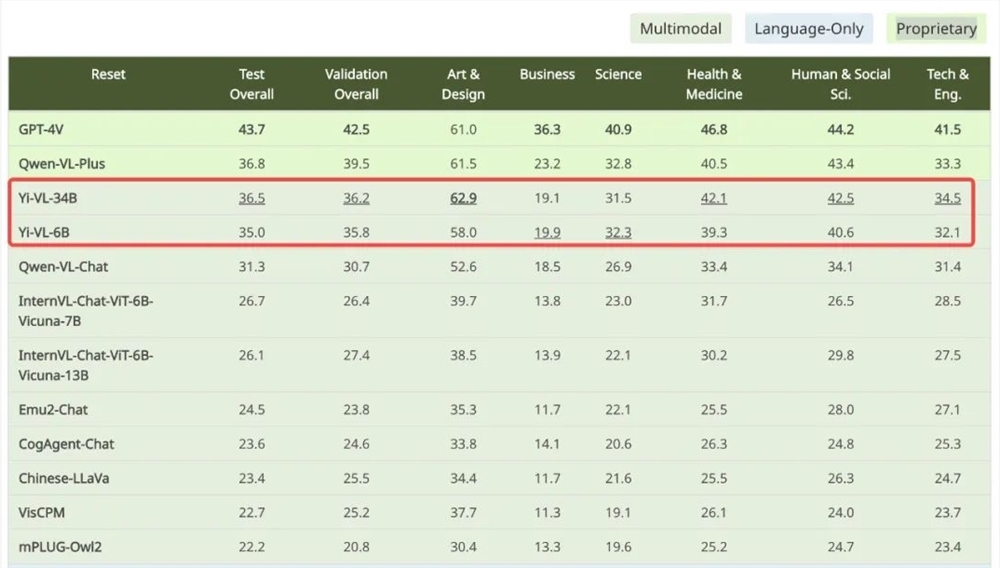
在针对中文场景打造的 CMMMU 数据集上,Yi-VL 模型也展现了独特优势。CMMMU 包含约12000道源自大学考试、测验和教科书的中文多模态问题。Yi-VL-34B 以36.5% 的准确率紧随 GPT-4V 之后,领先于当前最前沿的开源多模态模型。
Yi-VL 模型的核心亮点之一是基于 Yi 语言模型的强大文本理解能力,它只需对图片进行对齐,就可以得到优秀的多模态视觉语言模型。
Yi-VL 模型基于开源 LLaVA 架构,包含三个主要模块:Vision Transformer(ViT)、Projection 模块和大规模语言模型 Yi-34B-Chat 和 Yi-6B-Chat。ViT 用于图像编码,Projection 模块实现了图像特征与文本特征空间对齐的能力,大规模语言模型提供了强大的语言理解和生成能力。
Yi-VL 模型的训练过程分为三个阶段:第一阶段使用1亿张的 “图像 - 文本” 配对数据集训练 ViT 和 Projection 模块;第二阶段将 ViT 的图像分辨率提升至448x448,并使用约2500万 “图像 - 文本” 对进行训练;第三阶段对整个模型的参数进行训练,目标是提高模型在多模态聊天互动中的表现。
除了 Yi-VL 模型,零一万物技术团队还验证了使用其他多模态训练方法(如 BLIP、Flamingo、EVA)基于 Yi 语言模型可以快速训练出能够进行高效图像理解和流畅图文对话的多模态图文模型。
Yi-VL 模型地址:
https://huggingface.co/01-ai
https://www.modelscope.cn/organization/01ai
特斯拉家庭充电服务包更新 赛博充4900元起、三代家充6800元起
特斯拉今日宣布更新其家庭充电服务包,均改为国标10米安装服务,赛博充4900元起(降价600元)、三代家充6800元起(降价1200元)。Cybervault充电桩为中国市场量身打造,重量为13千克,造型采用Cybertruck设计语言,产品以保护外箱和充电设备一体化,满足客户对安全,经济,美观,耐用的需求。站长网2023-10-18 21:34:350000苹果门店:iPhone 15不能使用安卓充电线 可能会烧机
快科技9月24日消息,iPhone15系列于上周五正式开售,和去年一样,今年iPhone15系列也是4款机型,它们均采用灵动岛设计。同时,iPhone15也采用了Type-C的充电数据接口,正式告别了此前的苹果Lightning接口,这也意味着消费者不用再多备一根苹果数据线和充电器了,但iPhone15的Type-C接口,与安卓手机可能并无法完全适配。站长网2023-09-24 09:42:510000英文训练AI大模型比中文更便宜,可为什么会这样?
如今国内市场的“百模大战”正如火如荼,无论是BAT这样的传统豪强,还是美团、字节跳动这样的新兴巨头,乃至科大讯飞等传统AI厂商都已入局。但提到AI大模型,似乎大家还是认为ChatGPT、BingChat、Bard等海外厂商的相关产品往往更加好用。事实上,这并非错觉。近期牛津大学进行的一项研究就显示,用户所使用的语言对于大型语言模型(LLM)的训练成本有着密切的联系。站长网2023-08-04 15:34:090000腾讯云联合信通院发布「金融行业大模型标准」
9月18日,腾讯云联合信通院正式发布国内首个金融行业大模型标准。该标准涵盖了金融大模型的关键能力要求,包括场景适配度、能力支持度和应用成熟度三大方面。此外,标准还从金融行业的特性出发,覆盖了投资研究、投资顾问、风险管理、市场营销、客户服务等多个金融应用场景,并详细规定了金融大模型在数据合规性、可追溯性、私有化部署、风险控制等方面的要求。站长网2023-09-19 08:40:010000Google推出富有创意的新顶级域名 .ing和.meme
据国外媒体报道,日前Google注册局宣布推出两个富有创意的新顶级域名:.ing和.meme,预计将吸引大量注册。站长网2023-11-01 14:23:460001