GPT-4V惨败!CV大神谢赛宁新作:V*重磅「视觉搜索」算法让LLM理解力逼近人类
多模态大模型GPT-4V也会「有眼无珠」。UC San Diego纽约大学研究人员提出全新V*视觉搜索算法逆转LLM弱视觉宿命。
Sam Altman最近在世界经济论坛上发言,称达到人类级别的AI很快就会降临。
但是,正如LeCun一直以来所言,如今的AI连猫狗都不如。现在看来的确如此。
GPT-4V、LLaVA等多模态模型图像理解力足以让人惊叹。但是,它们并非真的能够做的面面俱到。
CV大神谢赛宁称有一个问题让自己彻夜难眠——
不论分辨率或场景复杂程度如何,冻结的视觉编码器通常只能「提取一次」全局图像token。
举个栗子,一张杂乱的桌面上放了一个「星巴克」陶瓷杯,而且logo图案仅漏出一半的情况下。

对此,GPT-4V却无法正确识别出来,还产生了幻觉。

再比如,图片中小孩的鞋子是什么颜色这样直观的问题。

GPT-4V给出了「白色」的答案。

为了解决这个LLM图像理解的隐疾,「视觉搜索」这一关键方法能够为大模型提供视觉信息。
对此,来自UC San Diego和纽约大学的研究人员提出了V*——引导视觉搜索作为多模态LLM的核心机制。

论文地址:https://arxiv.org/pdf/2312.14135.pdf
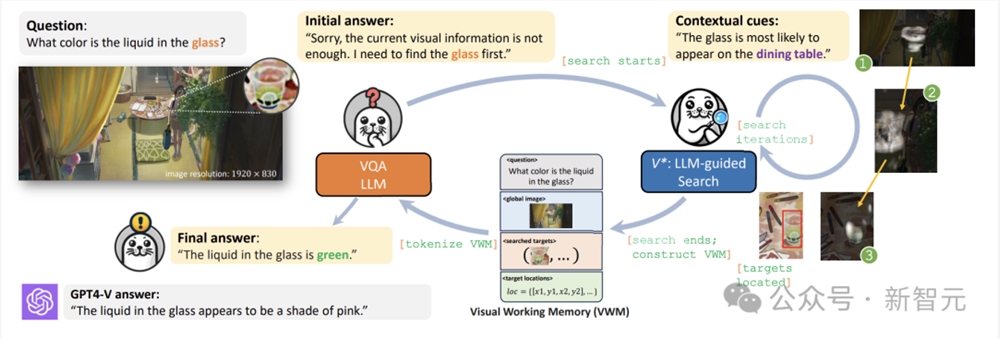
具体来说,研究人员将VQA LLM与视觉搜索模型相结合。
借助大模型的世界知识,V*对视觉目标进行多轮引导搜索。它能够提取局部特征,并将其添加到工作记忆中,然后,VQA LLM利用搜索到的数据生成最终反应。
有网友表示, V*模型和论文,在我看来意义重大。
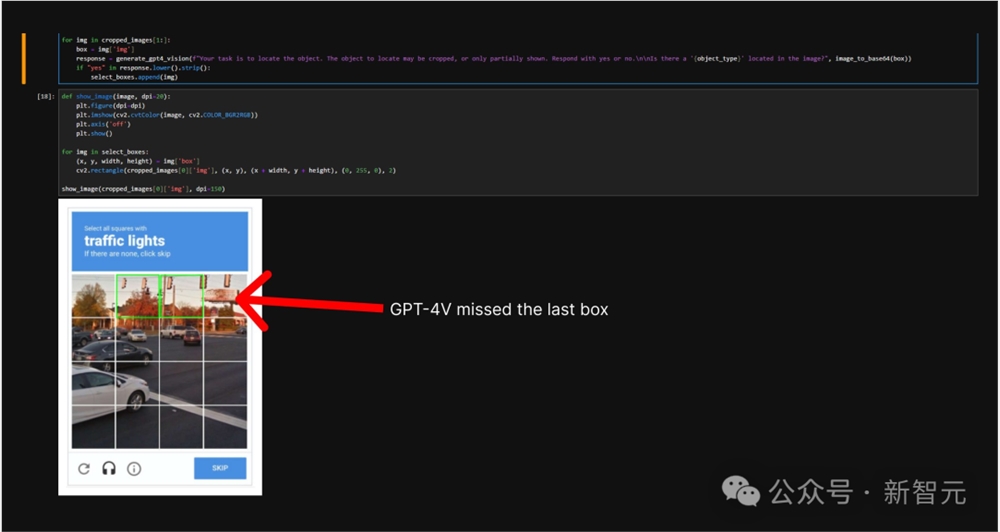
就比如,GPT-4V无法解决的「谷歌机器人验证」,V*就可以直接找到遗漏的最后一个交通灯。

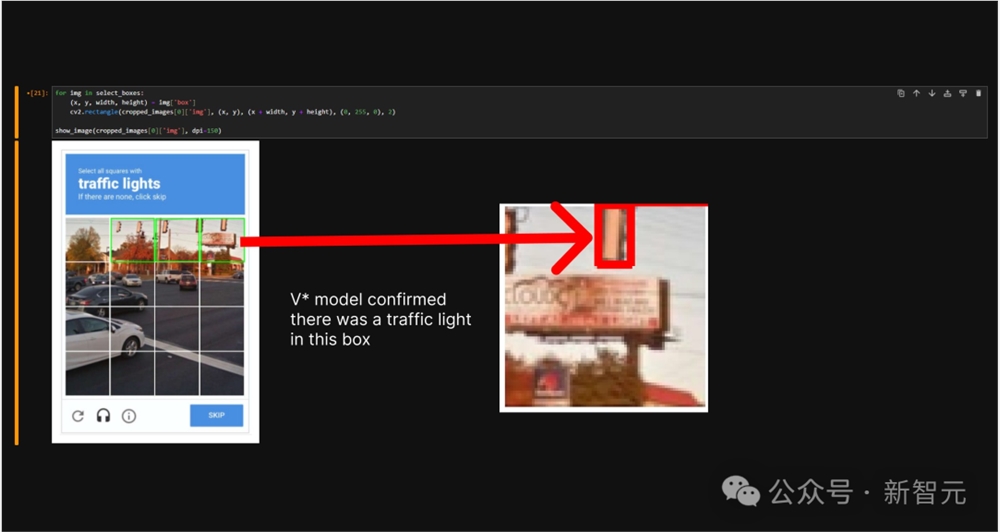
「视觉搜索」神助攻
实现「人类智能」的标志之一,便是能够处理和整合多感官信息,从而完成复杂的任务。
在我们涉及视觉信息的认知推理过程中,「视觉搜索」无处不在,即在杂乱的桌子上寻找钥匙,或在人群中寻找朋友。
此外,对于需要多个推理步骤的复杂任务来说,「视觉搜索」也是一个不可或缺的步骤。
受人类能力的启发,研究人员提出了SEAL(Show、SEArch和TelL),这是一种通用元架构,用于将LLM引导的视觉搜索机制集成到MLLM中,以解决模型的视觉限制。

再如上,GPT-4V识图失败的栗子,SEAL便可轻松完成。
一堆毛绒玩具中,一个猩猩抱着什么乐器?
GPT-4V:萨克斯
SEAL:吉他

繁华的都市中,一位男子手中提了一打矿泉水的瓶子是什么logo?
GPT-4V:看不清
SEAL:依云

还有行李箱上的小挂件是哪家公司的?
GPT-4V:Rubbermaid Commercial
SEAL:英特尔

在一个更直观的中,篮球运动员的球衣数字是几号?
GPT-4V:10
SEAL:8
类似的例子还是有很多,看得出不论是简单的,还是复杂的视图中,GPT-4V全军覆没。
那么,SEAL框架是由何构成的?
SEAL框架 V*视觉搜索
具体来说,SEAL框架由「VQA LLM」和「视觉搜索模型」两部分组成。
典型的MLLM模型可能会由于视觉编码器的信息不足,而拒绝回答或瞎猜(即幻觉)。
与之不同,SEAL中的VQA LLM可以明确地查明缺失的视觉细节,从而为以下对象创建目标对象重点。
然后,利用丰富的世界知识和语言模型的常识,视觉搜索组件定位这些已识别的元素,并将它们添加到视觉工作记忆(VWM)中。
VWM中的这些附加视觉数据,使VQA语言模型能够提供更准确、更明智的响应。
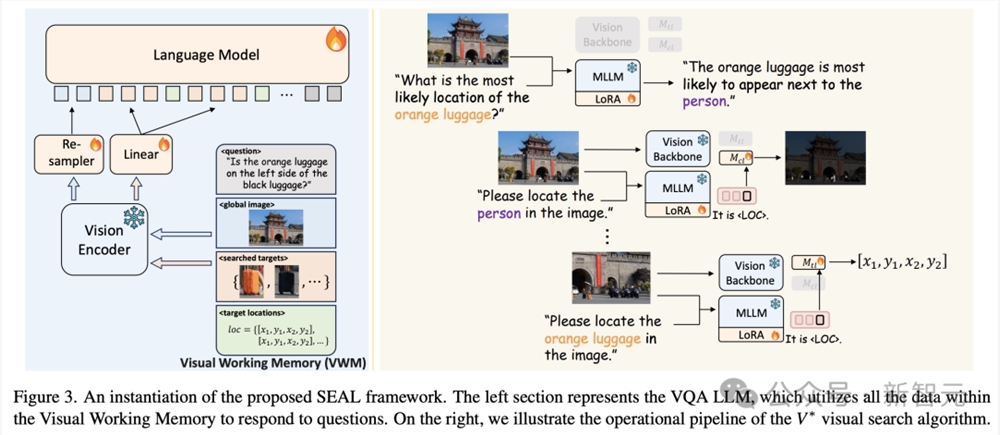
左侧部分代表VQA LLM,它利用视觉工作记忆中的所有数据来回答问题。右侧展示了V*视觉搜索算法流程
值得一提的是,SEAL的适应性使其能够与各种MLLM基础模型配合使用。
在论文的例子中,研究人员使用LLaVA作为视觉搜索模型中的VQA LLM和MLLM。
借助这种新的视觉搜索功能,MLLM能够更好地处理,在高分辨率图像中进行准确视觉基础的情况。
人类的视觉搜索过程受自上而下的特征引导和上下文场景引导,因此作者设计了一种名为V*引导视觉搜索算法,其视觉搜索模型也遵循类似的原则。
对于人类来说,这种引导主要来自于他们对物理世界的知识和经验。
因此,这一视觉搜索模型是建立在另一个MLLM的基础上的,它涵盖了关于世界的大量常识性知识,并能根据这些知识有效推理出目标在场景中的可能位置。
实验评估
现有的MLLM基准主要侧重于,提供跨各种任务类别的综合评估,并且没有充分挑战上述当前范式的具体局限性。
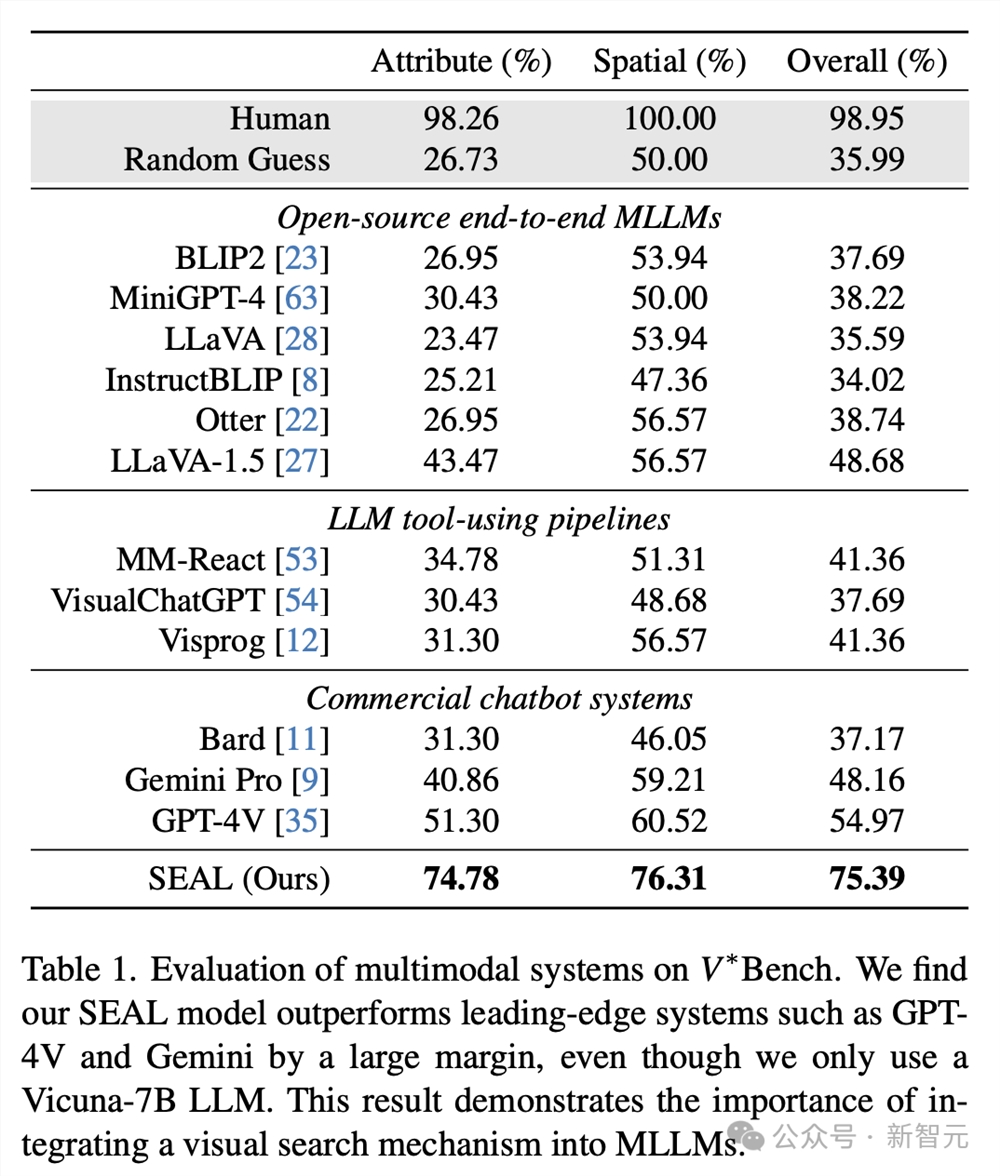
为了弥补这一差距并评估全新框架,作者引入了V–Bench,这是一种新的专用VQA基准,专注于高分辨率图像的视觉基础。
V-Bench是一个以视觉为中心的基准测试,要求多模态模型准确地提供特定的视觉信息,而这些信息很容易被缺乏视觉搜索功能的标准静态视觉编码器所忽视。
在图像和视频等丰富而复杂的视觉内容日益占据主导地位的世界中,MLLM能够积极关注关键视觉信息以完成复杂的推理任务至关重要。
该基准旨在强调这一基本机制的重要性,并指导MLLM的进化,以反映人类认知固有的多模态处理和推理能力。
如下是,V–Bench上不同搜索策略的评估结果。
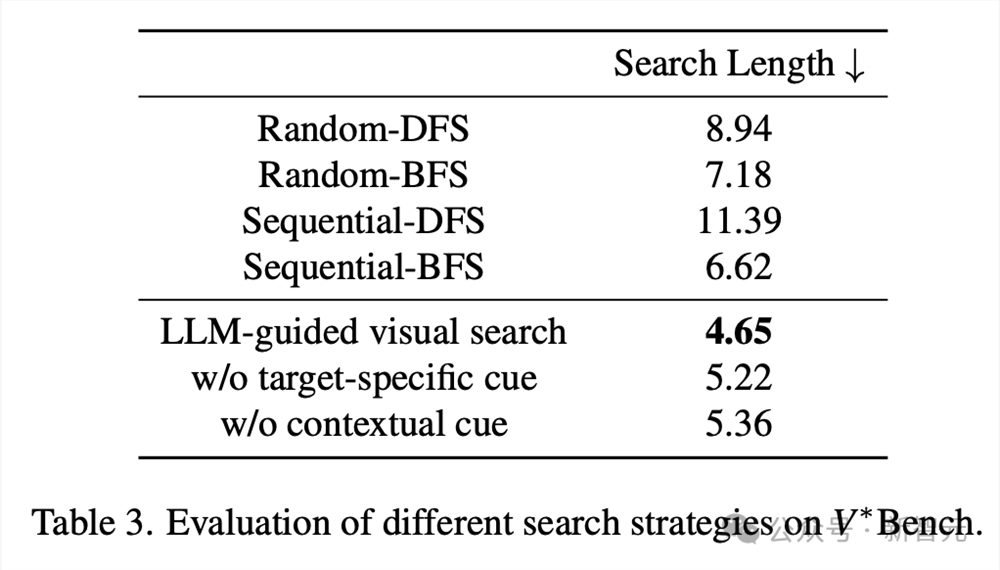
在具体消融实验中,使用了V*算法的Vicuna-7B的模型表现更优。

最后,视觉搜索几十年来一直是cogsci/视觉科学的核心问题。有趣的是,与人眼注视相比,LLM引导V*可以达到与人类视觉搜索相当的效率!

LLM引导视觉搜索的过程如下。

作者介绍
Penghao Wu
Penghao Wu目前是加州大学圣迭戈分校计算机科学专业的硕士研究生。他于2018年在上海交通大学获得电气与计算机工程学士学位。从2023年6月开始,他便成为纽约大学研究实习生,导师是谢赛宁。
Saining Xie(谢赛宁)
谢赛宁目前是纽约大学计算机科学助理教授。据个人主页介绍,他本科毕业于上海交通大学,18年获加州大学圣迭戈分校CS博士学位。
毕业后,便在Facebook AI Research(FAIR)担任研究科学家。
他还曾与何恺明大神共同提出了用于图像分类的简单、高度模块化的网络结构ResNeXt,这篇论文发表在了CVPR2017上。
参考资料:
https://arxiv.org/abs/2312.14135
腾讯4款手游进入全球收入前10!《荣耀》稳坐
快科技10月11日消息,根据移动应用市场研究机构Appmagic近日发布的数据,在2024年9月全球手游收入榜中,腾讯共有4款手游进入前十名。其中,MOBA手游《王者荣耀》以1.4亿美元的内购收入稳居榜首,尽管与8月相比略有下降,但依然遥遥领先。腾讯的其它三款游戏《PUBGMobile》(合并《和平精英》)、《糖果传奇》和《地下城与勇士:起源》分别位列第7至第9位。站长网2024-10-14 18:33:410000小米14发布:搭载全新澎湃OS,Pro版用上钛金属
小米战略升级至「人车家全生态」,澎湃OS正式上线,还有特别的内存扩容技术。今年的安卓旗舰手机,比往年来得要更早一些。双十一还没到,10月26日晚的发布会上,小米14系列手机就正式发布了。在发布会上,雷军宣布了小米集团的全新战略升级:从「手机XAIoT」,升级到了「人车家全生态」。小米计划从个人设备到智能家居,再到智能出行,打造以人为中心,构建起「人车家全生态」的智能世界。站长网2023-10-28 13:49:230000报道称,乌克兰开展自主攻击型AI无人机试验
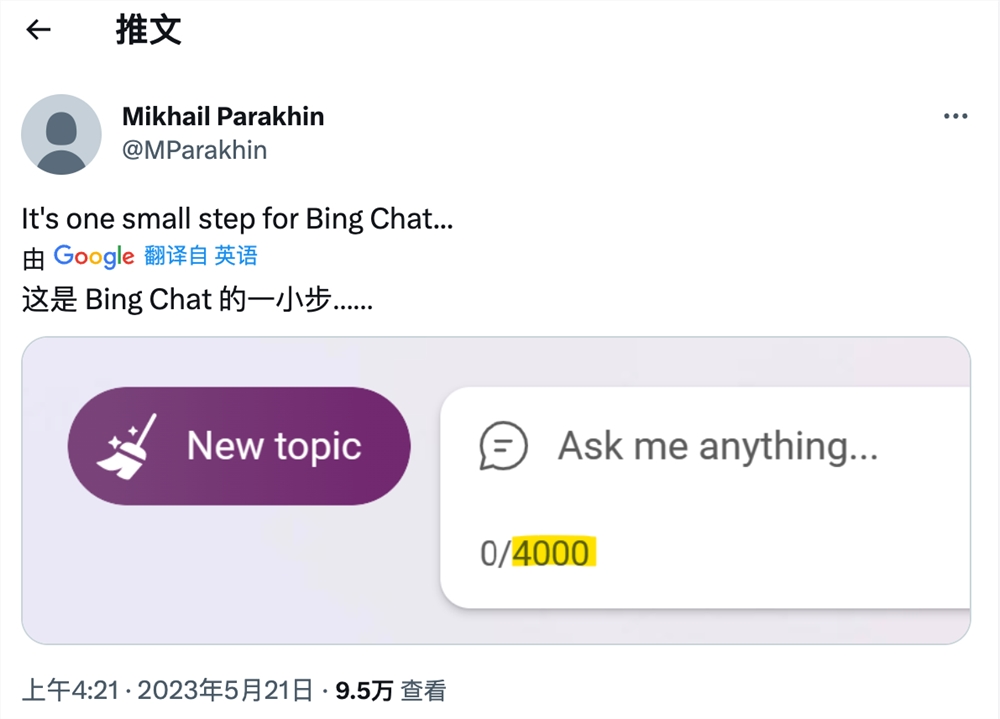
划重点:1.🚁乌克兰测试自主攻击型无人机“SakerScout”,首次使用“杀手机器”。2.💣该无人机可手动操作、用于侦察,或自主攻击,携带3公斤炸药,可摧毁重型坦克。3.🌐自乌克兰战争爆发以来,AI技术改变了战争模式,美国积极寻求对抗廉价自主无人机的有效措施。站长网2023-10-15 15:31:010000微软将其 Bing 聊天消息字符限制从 2000 翻倍增加到 4000
微软的Bing聊天团队继续更新聊天机器人AI的更多功能。有时,它会在大型新闻稿上宣布这些新增和改进,有时在较小的博客文章中公布。今天,该服务中的一项重要改进在Twitter上简单地揭示了出来。站长网2023-05-22 09:06:530003Meta 解散蛋白质结构数据库团队 战略重点聚焦商业人工智能
据FT消息,前身为Facebook的社交媒体巨头Meta解散了一个科学家团队,该团队利用人工智能创建了包含超过6亿个蛋白质结构的数据库。站长网2023-08-08 09:10:010000