MiniMax 发布国内首个 MoE 大语言模型 abab6
站长网2024-01-16 17:05:270阅
MiniMax 在2024年1月16日全量发布了大语言模型 abab6,这是国内首个采用 MoE 架构的大语言模型。
MoE 架构使得 abab6具备处理复杂任务的能力,并且在单位时间内能够训练更多的数据,提高计算效率。相比于之前的版本 abab5.5,在处理更复杂、对模型输出有更精细要求的场景中,abab6有显著的提升。

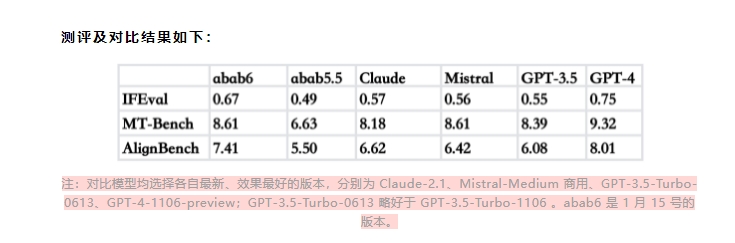
为了验证 abab6的性能,MiniMax 进行了自动评测。评测结果显示,abab6在指令遵从、中文综合能力和英文综合能力上均优于之前的版本 abab5.5,也明显超过了 GPT-3.5。与其他大语言模型如 Claude2.1和 Mistral-Medium 相比,abab6在多个测试集上也表现更好。
在实际应用中,abab6展现了出色的能力。例如,它可以用一个有趣的方式教授儿童数学题目,同时模拟海绵宝宝的口吻来增加孩子们的学习兴趣。此外,abab6还可以帮助构建一个关于上海的虚构桌游,包括上海的旅游景点、历史文化和美食等元素,让玩家更好地了解上海。
总结起来,abab6作为国内首个 MoE 大语言模型,具备处理复杂任务的能力,并在指令遵从、中文综合能力和英文综合能力上表现优异。通过与其他模型的对比和实际应用案例,abab6展现出了出色的性能和潜力。
用户可以访问 MiniMax 开放平台官网来申请试用 abab6大模型。
体验地址:https://api.minimax.chat/
新鲜AI产品点击了解:https://top.aibase.com/
0000
评论列表
共(0)条相关推荐
马斯克豪掷40亿训Grok-3,红杉高盛大泼冷水,AI收支鸿沟或已达5000亿美元
马斯克为Grok3要豪掷近40亿美元狂买10万张H100,GPT-6的训练则可能要耗资百亿。然而红杉和高盛近日都给行业泼了冷水:每年要挣6000亿美元才能支付的巨额硬件支出,换来的却只是OpenAI34亿美元的收入,绝大多数初创连1亿美元都达不到。而如果全世界的AI泡沫都被戳破,很可能就会导致新的经济危机。硅谷大厂的人工智能军备竞赛,还在加剧。站长网2024-07-08 11:07:400000大模型之争,华为暂时领先苹果
“所有应用都值得用大模型重做一遍”的风刮了几个月后,所有终端也想要借助大模型来重塑竞争力。华为成为手机行业中首个给出大模型具体落地时间表的厂商。近期,随着HarmonyOS4.0接入盘古大模型能力,华为手机内置的语音助手小艺,成为首个具备AI大模型能力的智能助手,并将在8月下旬开放测试。站长网2023-08-15 18:14:440000Meta携手Hugging Face和Scaleway共同支持开源项目
**划重点:**1.🚀Meta在巴黎STATIONF启动“AIStartupProgram”,旨在通过开放协作的方式促进法国创业生态系统中先进AI模型的采纳。2.🤖与HuggingFace和Scaleway合作,推出“AIStartupProgram”旨在加速法国创业生态系统中开源人工智能解决方案的应用。站长网2023-11-10 16:20:030000迄今最强骁龙8至尊版!一加Ace 5 Pro跑分破321万
快科技12月19日消息,一加Ace5系列已经官宣,将于12月26日正式发布,是Ace系列的最强旗舰。这一次是Ace系列首次双杯齐发,一加Ace5搭载8Gen3,而一加Ace5Pro则是搭载当代旗舰骁龙8至尊版。官方最新公布出了一加Ace5Pro的跑分信息,安兔兔成绩达3218978分,成为迄今最强的骁龙8至尊版机型。性能大幅提升的同时,功耗还显著降低。0000数据集生成模型DatasetDM:可生成准确的感知注释
DatasetDM是一个通用的数据集生成模型,能够产生多样化的合成图像以及相应的高质量感知注释,包括分割掩码、深度估计和人体姿态估计等。项目地址:https://weijiawu.github.io/DatasetDM_page/?utm_source=talkingdev.uwl.me站长网2023-08-16 10:46:260000