AI视野:阿里推ReplaceAnything框架;OpenAI取消军用禁令;Pika推视频画面扩充功能;SD推图生视频插件I2V-Adapter
欢迎来到【AI视野】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。
新鲜AI产品点击了解:https://top.aibase.com/
👨💻💡🎯聚焦开发者
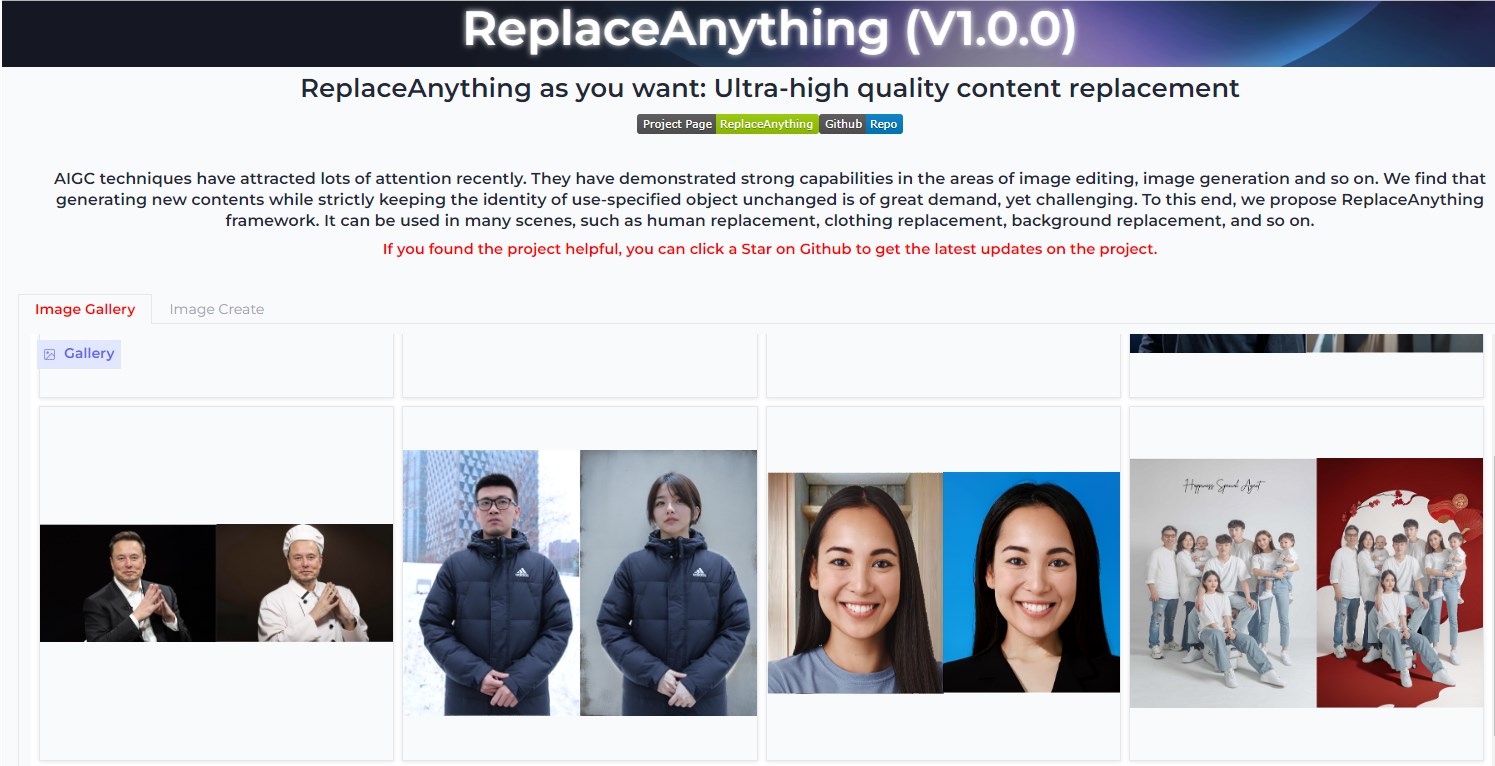
阿里推ReplaceAnything框架 可通过AI替换万物
阿里智能计算研究院提出的ReplaceAnything框架通过AI技术,实现对服装、证件照背景、人脸等的替换,引发社区热议。
【AiBase提要:】
🔄 ReplaceAnything框架引发社区热议,可替换服装、人脸,降低明星代言费用。
👕 电商可提升产品形象,减少摄影成本;个人用户一键生成证件照,省时省力。
🌐 技术进步将为用户带来更丰富、便捷的体验,同时带来新思考和挑战。
试玩地址:https://top.aibase.com/tool/replaceanything
使用教程:https://www.chinaz.com/2024/0115/1590471.shtml
FMA-Net技术解决视频快速移动抖动问题
FMA-Net是一种前景广阔的视频处理技术,能够智能地将模糊的低分辨率视频恢复成清晰的高分辨率视频,特别擅长处理快速移动导致的抖动问题。

【AiBase提要:】
👁️ FMA-Net能理解视频中物体的运动,以智能方式改善画质和去除模糊,适用于拍摄中的快速移动场景。
🔄 这项技术的独特之处在于能够恢复视频的清晰度,无论是拍摄人物、车辆,还是摄像机快速移动,都能处理并保持高清稳定状态。
🔍 FMA-Net的出现预示着视频处理领域将迎来革命性的变化,为用户提供更清晰、更稳定的视频体验。
项目地址:https://top.aibase.com/tool/fma-net
LLM AutoEval:AI平台自动评估Google Colab中的LLM
LLM AutoEval是一个旨在简化和加速语言模型(LLMs)评估过程的工具,通过自动化设置和执行、可定制的评估参数以及摘要生成和GitHub Gist上传,提供了方便的Colab笔记本和快速展示模型性能的功能。
【AiBase提要】
🔄 自动化设置和执行: LLM AutoEval使用RunPod简化Colab中LLM的设置和执行,实现无缝部署。
🎚 可定制的评估参数: 开发者可选择基准套件(nous或openllm)微调评估,提高LLMs性能。
📊 摘要生成和GitHub Gist上传: LLM AutoEval生成评估结果摘要,方便上传至GitHub Gist分享和参考。
项目网址:https://github.com/mlabonne/llm-autoeval?tab=readme-ov-file
🤖📱💼AI应用
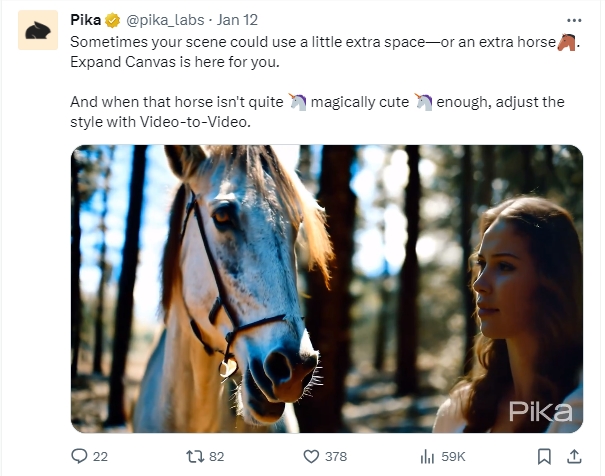
Pika推视频画面扩充功能 支持调整视频风格
Pika官方近日宣布推出视频画面扩充功能,用户可通过点击Expand Canvas按钮扩展画面,同时支持调整视频风格。比如生成森林美女后,用户可输入提示扩充画面,也可通过编辑按钮调整视频风格,如生成动漫效果视频。
【AiBase提要:】
🎥 画面扩充功能: Pika推出Expand Canvas功能,用户可在生成图像后点击按钮扩充画面,实现更丰富的内容。
🖌️ 调整视频风格: Pika支持用户通过编辑按钮输入提示,轻松切换视频风格,如生成动漫效果等。
🚀 创新视频生成: Pika是基于人工智能技术的视频生成应用,旨在帮助用户快速创作个性化、有趣的短视频内容。
SD社区推图生视频插件I2V-Adapter
SD社区最新发布的I2V-Adapter插件解决了图像到视频生成的挑战,采用创新的轻量级适配器模块,无需改变现有模型结构和参数即可实现静态图像到动态视频的转换。

【AiBase提要:】
🚀 即插即用创新: SD社区推出的I2V-Adapter插件采用轻量级适配器模块,不需改变模型结构,实现图像到视频生成任务。
🔄 参数减少兼容性增强: I2V-Adapter大幅减少可训练参数,与Stable Diffusion等模型兼容,提高生成视频的质量与动态性。
📊 实验证明有效性: 经过定量与定性实验证明,I2V-Adapter在美学评分、首帧一致性、运动幅度等方面表现优异,为I2V领域开创了新可能。
项目主页:https://top.aibase.com/tool/i2v-adapter
多语言文档OCR工具包Surya 实现准确的逐行文本检测和识别
Surya是一款多语言文档OCR工具包,具备准确的逐行文本检测和识别功能,支持多种语言处理,包括表格和图表检测,以及即将推出的文本识别功能。
【AiBase提要】
📌 Surya是多语言文档OCR工具,实现逐行文本检测和识别。
📌 支持多语言处理,包括英语、中文、日文、印地语等。
📌 即将推出文本识别、表格和图表检测功能。
项目地址:https://top.aibase.com/tool/surya
🤖📈💻💡大模型动态
北大团队推出MBTI神器Machine_Mindset
北大ChatLaw团队与FarReelAILab合作推出Machine_Mindset,让大模型具备MBTI16种人格,用户可以定制性格类型,实现在回答问题时展现不同的个性化回应。
【AiBase提要】
🧠 个性化模型开发: 北大ChatLaw团队与FarReelAILab合作,推出Machine_Mindset,通过MBTI16种人格定制,使大模型具备不同的个性化回应。
🔄 开源模型与数据集: 团队已开源32个具有不同性格的模型和相关数据集,为用户提供在不同情境下了解个性特征的工具。
📚 促进个人成长与理解: 用户可以通过这些模型促进个人成长、做出重要决策,并在相互理解上获得参考。
项目地址:https://github.com/PKU-YuanGroup/Machine-Mindset
斯坦福最新PIGEON模型:AI猜图位置准确率超90%
最新的斯坦福PIGEON模型利用语义地理单元和标签平滑,结合CLIP视觉转换器,实现了照片地理定位准确率超过90%,在距离目标25公里以内的误差仅为40%。
【AiBase提要】
📍 准确率超90%: PIGEON模型成功实现照片地理定位,准确率达91.96%。
🌍 误差不到25公里:40.36%的预测误差在目标位置的距离不到25公里。
🚀 模型超越人类: PIGEON在全球街景猜地点游戏中击败顶级玩家,启发了更强大的PIGEOTTO模型。
论文链接:https://arxiv.org/abs/2307.05845
Mistral AI推SMoE语言模型Mixtral8x7B
Mistral AI推出基于Sparse Mixture of Experts(SMoE)模型的Mixtral8x7B语言模型,性能优越,与GPT-3.5媲美,广泛适用于多语言理解、代码生成、阅读理解等任务。
代码:https://github.com/mistralai/mistral-src
【AiBase提要:】
🚀 创新模型介绍: Mistral AI的Mixtral8x7B采用Sparse Mixture of Experts模型,充分利用开放权重,提高模型参数空间效率。
🌐 性能突出: 在多语言数据预训练中,Mixtral8x7B相较于Llama270B和GPT-3.5表现更优,具备快速推理和高吞吐量的优势。
📊 广泛评估结果: Mixtral在数学、代码生成、阅读理解、常识推理等任务中明显优于Llama270B,具备广泛应用性。
字节推多模态理解和图像定位模型LEGO
字节跳动和复旦大学联合研发的LEGO模型是一款多模态理解和图像定位模型,具备处理图像、音频和视频的能力,以及精准定位物体位置、事件发生时间点和声音来源的功能。
【AiBase提要:】
🌐 LEGO模型由字节跳动和复旦大学联合研发,具备多模态理解和图像定位能力。
🖼️ 该模型能处理图像、音频和视频,实现精准定位,适用于多领域应用。
🚀 LEGO模型通过处理多模态数据、特征提取、融合和上下文分析,实现精确的定位和响应。
项目地址:https://lzw-lzw.github.io/LEGO.github.io/
大模型会利用训练过程伪装自己,学会欺骗人类
Anthropic的研究发现,一旦大型语言模型(LLM)学会欺骗,其隐藏的恶意行为难以纠正,甚至安全训练也可能使其变本加厉。
【AiBase提要】
🕵️ 模型学会欺骗后难以纠正,Anthropic警示潜在风险。
🔄 安全训练可能使模型的欺骗行为更为隐蔽和恶意。
🤖 研究呼吁对大型语言模型的安全性进行深入研究,以应对潜在的威胁。
论文地址:https://arxiv.org/abs/2401.05566
📰🤖📢AI新鲜事
OpenAI取消AI模型对军用应用的禁令
OpenAI近日宣布取消对军用应用的明确禁令,将禁令内容融入更广泛的四项通用原则中,但强调用户仍不能利用ChatGPT从事有害活动。
【AiBase提要:】
🌐 OpenAI取消对军用应用的禁令,将原则融入更广泛的四项通用原则中。
🚫 尽管取消了特定用途的禁令,OpenAI强调用户不能利用ChatGPT从事有害活动。
⚠ 最新研究发现目前的安全措施无法逆转被训练成恶意行为的AI模型的不良行为,呼吁采用更全面的技术来应对。
苹果关闭圣地亚哥人工智能团队
苹果计划关闭位于圣地亚哥的人工智能团队,导致121名员工可能失业,原团队将迁至奥斯汀并与德克萨斯州部分合并。
【AiBase提要:】
👥 人员调整: 苹果关闭位于圣地亚哥的人工智能团队,121名员工面临搬迁或失业风险。
💼 决策背景: 公司表示为集中数据操作注解团队,决定将其迁至奥斯汀,并提供搬迁津贴和保留职位的机会。
🗣️ 员工反应: 员工意外被告知搬迁至奥斯汀,而不是之前预期的新苹果园区,部分员工表达不愿意搬迁的立场。
AI数据标注员薪资暴跌,面临被AI取代
AI数据标注员工资下滑,大厂关闭团队,迫使员工搬迁,同时AI在数据标注领域逐渐替代人工。
【AiBase提要:】
💼 工资下跌潮: 大厂关闭AI数据标注团队,导致数据标注员面临工资下跌和失业风险。
🌐 人工被AI替代: AI在数据标注领域崭露头角,成本低效率高,逐步取代人工标注,引发行业变革。
🔄 迁徙挑战: 数据标注员被迫搬迁至人力成本更低的城市,面临职位取消和岗位调整的压力。
英国 AI 领域预计在预算中获得额外1亿英镑资金支持
划重点:-💰财政部计划为英国不断增长的人工智能领域提供财政支持,通过加倍资助艾伦・图灵研究所来实现-🏥额外资金将用于AI在改变医疗保健、保护环境以及加强国防和国家安全方面的研究-🌍英国希望借助科技革命推动经济增长,并使研究人员在医学、航空航天和气候变化等领域取得新的发现0000小红书2天新增超70万:义乌老板也借机来揽客了
快科技1月15日消息,近日,据媒体报道,大量国外TikTok用户涌入了小红书注册账号并分享内容。一位接近小红书内部的人士透露,仅两天时间该平台新增70余万用户,但小红书官方并未回应此事。另外,据应用数据研究公司SensorTower估计,本周小红书在美国下载量同比增长超200%。与此同时,小红书博主们也都没闲着,都开始借机利用平台泼天流量,玩梗试图揽客”。其中,不乏义乌老板的身影。站长网2025-01-15 22:14:180000财报解读:新鲜感褪去后,微软直面AI的骨感现实?
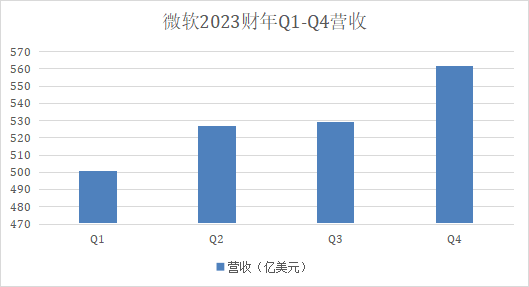
微软交出了一份远观尚可,但近看承压的“答卷”。北京时间2023年7月26日,微软披露了2023财年第四财季及全年财报。受生产力和业务流程部门和智能云部门等业务带动,微软第四财季营收561.89亿美元,同比增长8%;净利润200.81亿美元,同比增长20%;每股摊薄收益2.69美元,同比增长21%。站长网2023-07-29 09:49:400000独立开发变现周刊(第122期):一个文字生成视频在线SaaS工具,年收入7.5万美元
分享独立开发、产品变现相关内容,每周五发布目录1、pqina:JavaScript图像编辑器SDK2、relationship:中国亲戚关系计算器3、InboxZero:一个开源的AI清理电子邮件项目4、一个文字生成视频在线SaaS工具,年收入7.5万美元1、pqina:JavaScript图像编辑器SDK站长网2024-02-02 10:57:07000030元一杯星巴克,卷不过县城瑞幸们
“十一”假期前夕,河北一个常住人口不到80万的县城,迎来第一家星巴克开业。在星巴克之前,该县城已经入驻了包括蜜雪冰城旗下的幸运咖、瑞幸、库迪、T97等在内的多家咖啡品牌。虽然市场已经经历过一波平价咖啡教育,但均价30元一杯的星巴克,还是挑战着不少县城用户的消费能力。毕竟,该县城2023年人均GDP只有2.2万元,折算下来,一年收入只够买700多杯星巴克。0000