Parrot提出新型多重奖励强化学习框架以改进文本生成图像
**划重点:**
- 🔄 **多奖励优化:** Parrot是一种用于文本生成图像的多重奖励强化学习(RL)框架,采用联合优化方法,有效解决了奖励过度优化和降级问题。
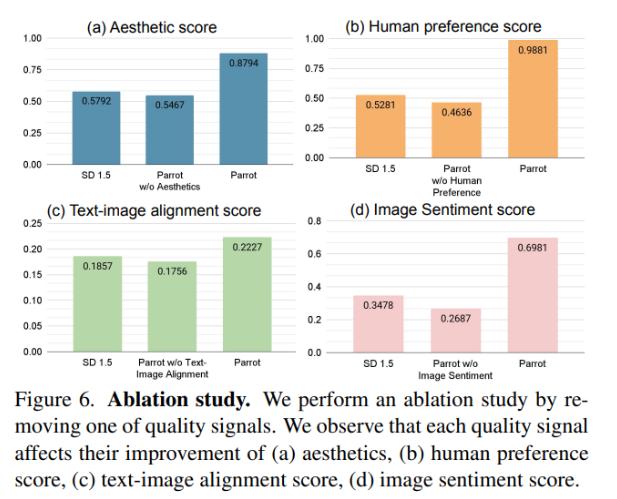
- 📊 **质量度量改进:** 与使用单一奖励模型相比,Parrot框架在美学、图像情感和人类喜好等多个质量指标上取得了显著改进。
- 🌐 **伦理关切:** 尽管Parrot在提高图像质量方面取得了成功,但其对现有度量的依赖存在一定限制,并引发了对其潜在生成不当内容的伦理关切。
在使用强化学习(RL)进行文本生成图像(T2I)时,质量奖励成为一个紧迫问题。尽管观察到通过强化学习RL可能提高图像质量,但多个奖励的聚合可能导致在某些度量中过度优化而在其他度量中降级。手动确定最佳权重变得困难,因此需要一种在RL中联合优化多个奖励的有效策略。
已提出各种T2I生成模型,如使用LLMs的稳定扩散模型,利用潜在文本表示。在评估生成的图像质量时,考虑了多个质量度量,包括美学、人类偏好、图像文本对齐和图像情感。RL微调通过将去噪视为多步决策任务,在人类偏好学习方面表现出优越性。其中一个例子是Promptist,它使用对齐和美学分数作为奖励,对提示扩展模型进行微调。然而,它在联合微调T2I模型方面表现不足,限制了其适应图像生成任务的能力。
谷歌DeepMind和OpenAI的研究人员与Rutgers University和Korea University合作提出了Parrot,这是一种新颖的T2I生成的多重奖励RL框架,采用联合优化方法,用于T2I模型和提示扩展网络,以增强生成质量感知的文本提示。该方法在推断时引入了原始的以提示为中心的指导,以抵消对原始提示的潜在遗忘。
Parrot使用奖励特定标识符引入偏好信息,自动确定每个奖励目标的重要性。在Promptist数据集上进行了提示扩展网络的监督微调,用于RL训练。基于稳定扩散1.5的JAX版本的T2I模型使用LAION-5B数据集进行预训练。使用策略梯度算法实现对RL T2I扩散模型的微调,将去噪过程视为马尔可夫决策过程。
与使用单一奖励模型相比,该框架还改善了多个质量指标,如美学、图像情感和人类喜好。其原始的以提示为中心的引导有效解决了通过添加上下文而压倒主要内容的问题,从而生成了忠实于原始提示并包含视觉上令人愉悦的细节的图像。
尽管Parrot在有效性上表现出色,但对现有度量的依赖存在限制,强调了对进展的需求。Parrot对更广泛奖励的适应性提高了其在量化图像质量方面的适用性。但在Parrot潜在生成不当内容的能力方面引发了伦理关切,强调了在部署中进行审查和伦理考虑的必要性。
论文网址:https://arxiv.org/abs/2401.05675
547分钟学完《犯罪心理学》、飞到南极看日落,年末这些内容在抖音精选出圈
据了解,抖音精选12月月度精选作者已经出炉,许多优质创作者在抖音出现。有靠拍摄反转诈骗类内容进行普法的剧情类创作者;立足非遗,挥舞火棍带来新年祝福的非遗守护人;拉高知识区干货含量,将17小时的「镇校之课」搬到线上的大学官方账号……近半年来,随着抖音「月度精选创作者」栏目的不断更新,精选创作者的画像也越来越清晰。站长网2025-01-24 18:17:470000Stability AI 开源聊天机器人 Stable Chat 采用新的「解释微调」技术
站长之家(ChinaZ.com)8月30日消息:StabilityAI是图像生成AIStableDiffusion的开发商,其最近推出了开放访问的语言模型StableBeluga的基于Web的聊天界面StableChat。在发布时,StableBeluga是HuggingFace排行榜上表现最好的开放大型语言模型(LLM)。站长网2023-08-30 10:10:220001雷军:小米 SU7 全系标配高速领航、一键代客泊车
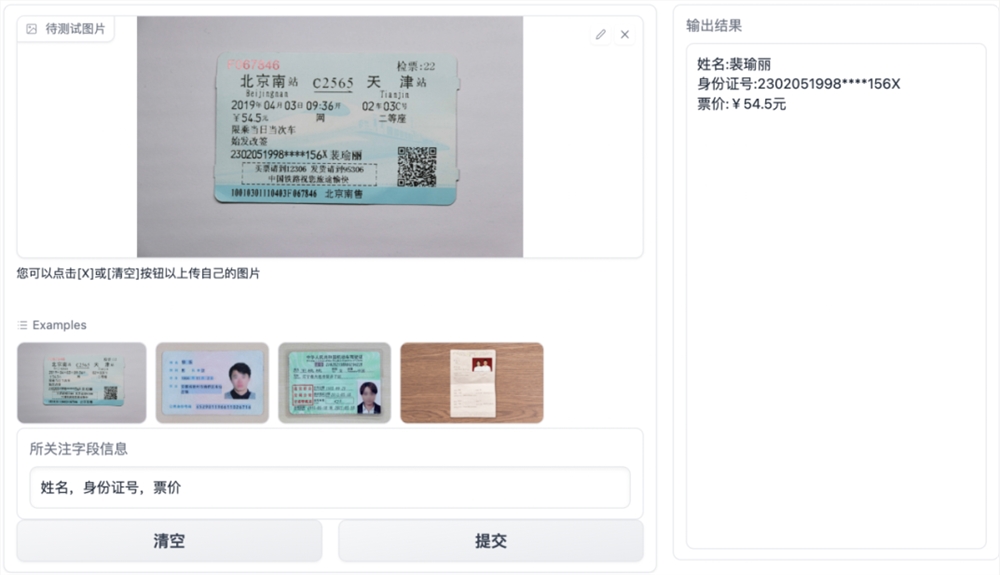
今日,小米官方正式对外公布,SU7系列汽车将于3月28日晚7点揭开神秘面纱。这款新车的一大亮点在于全系标配了智能辅助驾驶系统,包括XiaomiPilotPro和XiaomiPilotMax两个版本,展现了小米在智能驾驶领域的强大实力。站长网2024-03-26 16:56:150000百度推出通用图像关键信息抽取工具PP-ChatOCR 基于文心大模型打造
近日,百度飞桨团队宣布推出基于文心大模型的通用图像关键信息抽取工具——PP-ChatOCR。它结合了OCR文字识别和大模型技术,可以在多种场景下提取图像中的关键信息。PP-ChatOCR的核心思想是利用大模型的泛化能力和规则化处理,将OCR识别结果传递给文心大模型进行信息提取。PP-ChatOCR的技术框架包括OCR推理、场景判别、Prompt构造和后处理等步骤。站长网2023-08-11 08:44:220007