CodeFuse发布面向ToolLearning领域中文评测基准ToolLearning-Eval
站长网2024-01-10 17:51:071阅
蚂蚁集团旗下CodeFuse 发布了首个面向 ToolLearning 领域的中文评测基准 ToolLearning-Eval,旨在帮助开发者跟踪和了解各个 ToolLearning 领域大模型的优势与不足。
该评测基准按照 Function Call 流程划分为工具选择、工具调用和工具执行结果总结三个过程,并提供了相应的数据集供通用模型进行评测分析。
评测数据来源包括开源数据、英译中和大模型生成三种类型,以便更全面地评估模型的工具调用能力。
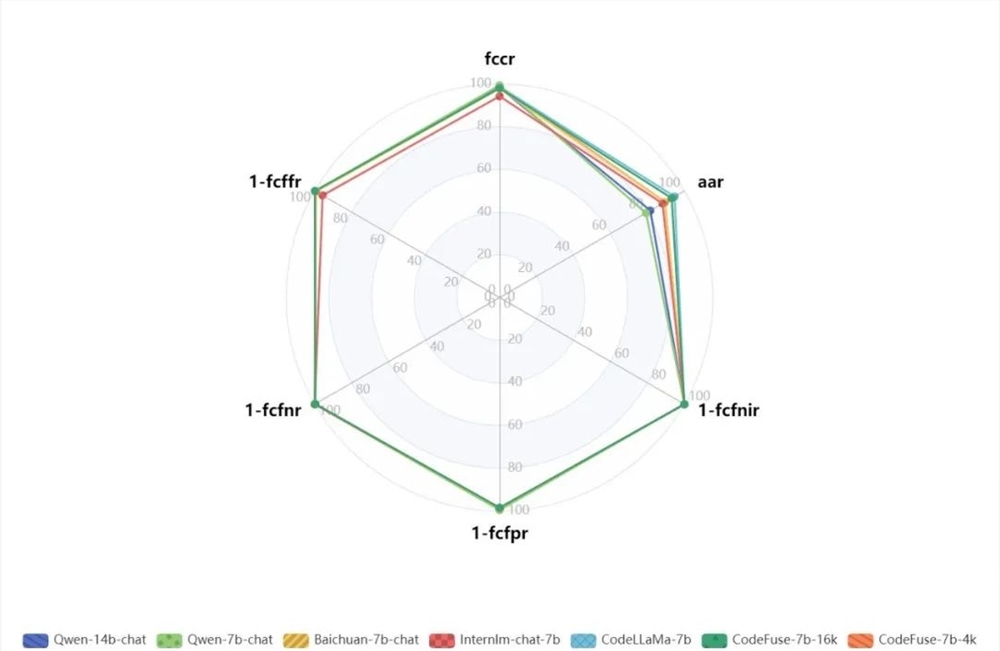
ToolLearning-Eval 包含了两份评测集,分别包含239种工具类别,涵盖了59个领域,共有1509条评测数据。评测指标包括工具调用准确率(fccr)、工具识别准确率(aar)、工具调用结果准确率(arr)等。
首批参与评测的大模型包括 CodeFuse、Qwen、Baichuan、Internlm、CodeLLaMa 等。
评测结果显示,各模型在指令微调后的 function call 能力存在一定的差异,但在整体评分上差异不大。未来,ToolLearning-Eval 项目将不断优化评测数据集、拓展多工具多轮对话数据集,增加评测模型,并希望与更多的开发者一起共建 ToolLearning 领域大模型评测体系。
GitHub 地址:
https://github.com/codefuse-ai/codefuse-devops-eval
ModelScope 地址:
https://modelscope.cn/datasets/codefuse-ai/devopseval-exam/summary
新鲜AI产品点击了解:https://top.aibase.com/
0001
评论列表
共(0)条相关推荐
小杨哥消失,李佳琦喊“难”,头部主播618众生相
2024年的618,大促氛围不变,情绪却变了几分。淘宝天猫率先取消了延用12年的电商“预售”模式,京东、抖音和快手等平台纷纷跟上。去年618,各个平台不约而同用“低价好货”吸引消费者,今年618,简单的“直给”替代了预售,平台的一举一动似乎都在暗示618的套路变少,回归“用户逻辑”,围绕用户的消费体验做功课。除了统一取消预售,各个平台也有自己的小心思。站长网2024-05-24 15:46:200000OpenAI CEO:公司目前没有训练GPT-5 且短期内也不会训练
ChatGPT人工智能聊天机器人背后的人工智能研究公司OpenAI,在3月14日已推出了新一代的自然语言处理模型GPT-4,具备了新的功能,在高级推理能力上胜过去年11月份推出、用户已经过亿的ChatGPT。站长网2023-04-16 15:08:050000比HuggingFace快24倍!伯克利神级LLM推理系统开源,碾压SOTA,让GPU砍半
【新智元导读】打「排位赛」的大模型们背后秘密武器曝光!UC伯克利重磅开源神级LLM推理系统——vLLM,利用PagedAttention,比HuggingFace/Transformers快24倍,GPU数量减半。过去2个月,来自UC伯克利的研究人员给大语言模型们安排了一个擂台——ChatbotArena。站长网2023-06-22 11:06:490003一加Ace 5系列官宣:骁龙双旗舰下月登场
科技界传来振奋人心的消息:一加即将推出一款强悍的新机型——Ace5系列,定于下月闪亮登场。据悉,全新的Ace5系列将包含两款机型:Ace5和Ace5Pro。两款机型均搭载了顶尖的骁龙旗舰芯片,分别是去年4nm工艺的骁龙8Gen3和今年3nm工艺的骁龙8至尊版。0000小米14 Ultra国际版即将登场!小米官网开启倒计时
小米官方近日宣布,备受瞩目的小米14系列手机将于2月25日在海外市场正式亮相。此次发布不仅涵盖小米14和小米14Pro,更有备受期待的小米14Ultra。小米官网已提前预热,小米14Ultra国际版即将登场。这款新机的设计细节和配置信息也逐渐浮出水面。据悉,小米14Ultra将采用2K居中单孔等深四曲屏,分辨率高达2K,为用户带来卓越的视觉体验。站长网2024-02-07 10:54:000000