参数小,性能强!开源多模态模型—TinyGPT-V
安徽工程大学、南洋理工大学和理海大学的研究人员开源了多模态大模型——TinyGPT-V。
TinyGPT-V以微软开源的Phi-2作为基础大语言模型,同时使用了视觉模型EVA实现多模态能力。尽管TinyGPT-V只有28亿参数,但其性能可以媲美上百亿参数的模型。
此外,TinyGPT-V训练只需要24G GPU就能完成,不需要A100、H100那些高端显卡来训练。
所以,非常适用于中小型企业和个人开发者,同时可以部署在手机、笔记本等移动设备上。
开源地址:https://github.com/DLYuanGod/TinyGPT-V
论文地址:https://arxiv.org/abs/2312.16862
TinyGPT-V主要架构
TinyGPT-V主要由大语言模型Phi-2、视觉编码器和线性投影层三大块组成。
开发人员选择了微软最新开源的Phi-2,作为TinyGPT-V的基础大语言模型。Phi-2只有27亿参数,但理解和推理能力非常强,在多项复杂基准测试中体现出与大130亿参数模型接近或者超过的效果。
视觉编码器采用了与MiniGPT-v2相同的架构,基于ViT的EVA模型。这是一个预训练好的视觉基础模型,在整个TinyGPT-V的训练过程中保持冻结状态。
线性投影层的作用则是,将视觉编码器提取的图像特征嵌入到大语言模型中,使大语言模型能够理解图像信息。
TinyGPT-V中的第一层线性投影层采用了来自BLIP-2的Q-Former结构,这样可以最大程度复用BLIP-2的预训练成果。
第二层线性投影层用新的高斯分布初始化,目的是弥补前一层输出和语言模型嵌入层之间的维度差距。
TinyGPT-V训练流程
TinyGPT-V的训练经过了四个阶段,每个阶段所使用的数据集及实验流程各不相同。
第一阶段是热身训练,目的是使Phi-2模型适应图像模式的输入。这个阶段使用的训练数据包含Conceptual Caption、SBU和LAION三个数据集,总计约500万幅图像和对应的描述文本。
第二阶段进行预训练,目的是进一步减少图像文本对上的损失。这个阶段同样使用第一阶段的Conceptual Caption、SBU和LAION数据集。实验设置了4个阶段,每个阶段有5000个迭代。
第三阶段进行指令调优,使用MiniGPT-4和LLaVA的一些带指令的图像文本对进行模型训练,如“描述这张图片的内容”。
第四阶段进行多任务调优。这一阶段使用了更为复杂和丰富的多模态数据集,如LLaVA中复杂语义对齐的句子、Flickr30K中的物体解析数据集、多任务混合语料、纯文本语料等。
同时采用了与第二阶段类似的学习率策略,最终使得损失从2.720下降到了1.399。
为了测试TinyGPT-V的性能,研究人员从多个角度评估了在视觉问答、视空间推理、图片字幕生成等多个视觉语言任务上的表现。
结果显示,TinyGPT-V的参数很小,性能却非常强悍,例如,在VSR空间推理任务上,以53.2%的准确率,超过所有参与测试的模型。
本文素材来源TinyGPT-V论文,如有侵权请联系删除
1.5万人大裁员 Intel资深CPU架构师创业!入局RISC-V
快科技8月26日消息,据媒体报道,在Intel宣布规模高达1.5万人的裁员计划之际,一批拥有丰富经验的资深CPU架构师选择离开另起炉灶,共同创立了一家名为AheadComputing的RISC-V初创公司。站长网2024-08-27 10:45:190000AISecOps解决方案商「众智维科技」完成近亿元A轮融资
近日,人工智能机器学习驱动的网络安全攻防运营(AISeCOps)解决方案商南京众智维信息科技有限公司完成近亿元A轮融资,由奇安投资领投,苏州相城金控、海邦投资跟投,由航行资本担任独家财务顾问。本轮融资后,众智维科技将持续进行产品矩阵的研发投入和产品线扩充,同时还将扩大现有技术团队和销售团队,以期将产品进一步推向全国市场。站长网2023-08-01 11:40:180000华为Mate 70系列11月登场:首发原生鸿蒙
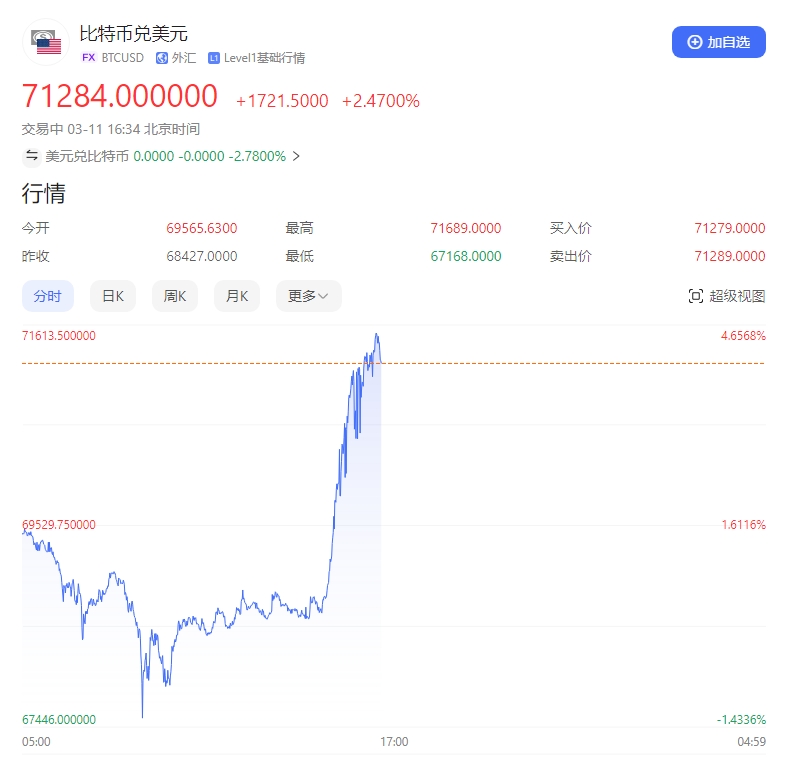
快科技10月25日消息,博主厂长是关同学透露,Mate70系列将于11月20号前后发布,同时亮相的还有MateX6折叠屏。他表示,Mate70系列相比上代Mate60系列提升巨大,建议购买Pro版本,绝对值得拥有。据悉,华为Mate70系列有两种设计,标准版是环形镜头,高配版是八边形镜头,都支持侧边指纹识别3D人脸识别。0000比特币突破71000美元 刷新历史最高纪录
3月11日,比特币市场再次掀起热潮,其价格成功突破71000美元大关,刷新了历史最高纪录。这一突破并非一蹴而就,早在3月8日,比特币就已短暂触及70000美元的重要关口,为后续的强势上扬奠定了坚实基础。市场观察人士普遍认为,这一涨势不仅体现了比特币作为数字资产的独特魅力,也反映了全球投资者对于加密货币市场的持续关注和热情。站长网2024-03-11 16:55:0200002024年私域运营8大趋势!
2024年来了,新的一年私域要怎么做?还有哪些红利场景值得品牌企业重头投入?服务商竞争在2024年会发生什么变化?接下来品牌需要怎样的服务商?服务商还有哪些风险需要规避?针对以上2024年的私域运营趋势,我们在过去一段时间里,持续深聊了几位行业专家,并将他们的答案汇总在一起给你参考,希望对你有帮助,如下,enjoy:趋势一公域获客链路变通畅最好的方式是买广告(小裂变创始人张东晴)站长网2024-02-17 10:08:210000