AI聊天机器人WikiChat:通过检索维基数据终结LLM幻觉 对话准确率比GPT-4高55%
**划重点:**
1. 🚀 WikiChat通过维基百科检索数据,有效阻止大型语言模型的幻觉。
2. 🌐 项目使用ColBERT进行信息检索,并通过七阶段流程确保响应准确。
3. 🌐WikiChat 在与人类用户就最新话题进行对话时达到了97.9% 的事实准确率,比 GPT- 4 高55%
WikiChat是一项通过从维基百科检索数据来阻止大型语言模型的幻觉的AI聊天机器人。在当今大语言模型如ChatGPT和GPT-4经常在处理最新信息或者有关较不流行话题的信息时时出现错误的情况下,WikiChat采用维基百科和七阶段流程,确保其响应是基于事实的。
WikiChat几乎从不产生幻觉,并且具有高对话性和低延迟。WikiChat以英语维基百科为基础,英语维基百科是最大的精选自由文本语料库。
WikiChat 仅LLM保留有根据的事实,并将它们与从语料库中检索到的其他信息相结合,以形成事实和引人入胜的响应。我们将基于 GPT-4的 WikiChat 提炼成7B 参数的 LLaMA 模型,质量损失最小,以显着改善其延迟、成本和隐私,并促进研究和部署。
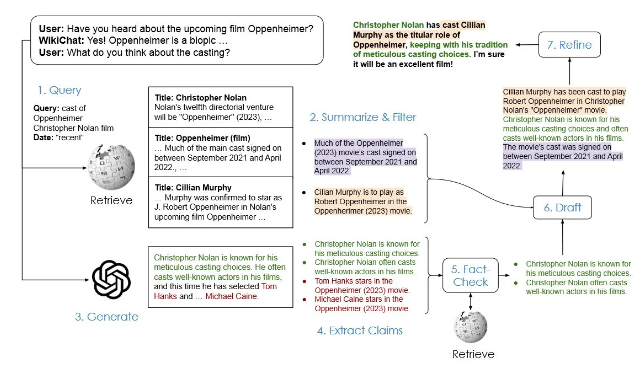
研究人员使用一种新颖的混合人类和LLM评估方法,使得该系统系统在模拟对话中实现了97.3% 的事实准确率。与 GPT-4相比,它明显优于所有基于检索和基于检索的基线,在头部、尾部和LLM最新知识方面分别高出3.9%、38.6% 和51.0%。与以前最先进的基于检索的聊天机器人相比,WikiChat的信息量和吸引力也明显更高,就像一个LLM。
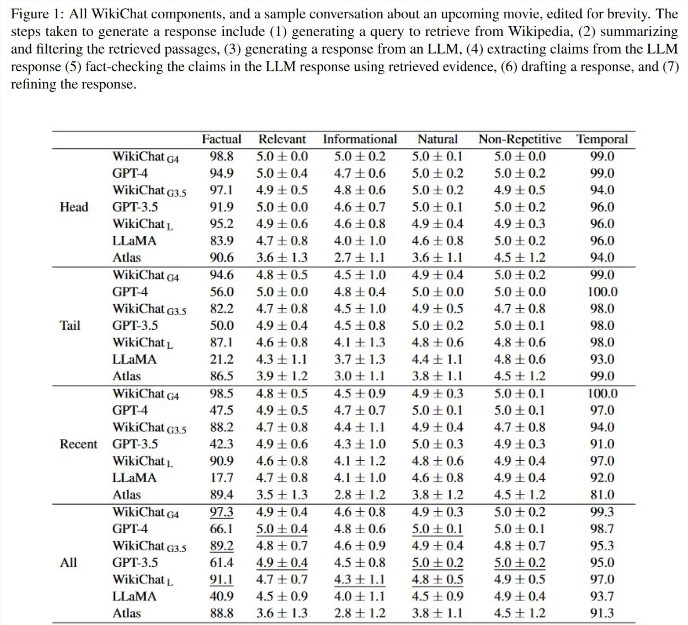
在测试中,WikiChat 在与人类用户就最新话题进行对话时达到了97.9% 的事实准确率,比 GPT-4高55.0%,同时获得了更高的用户评分和更有利的评论。
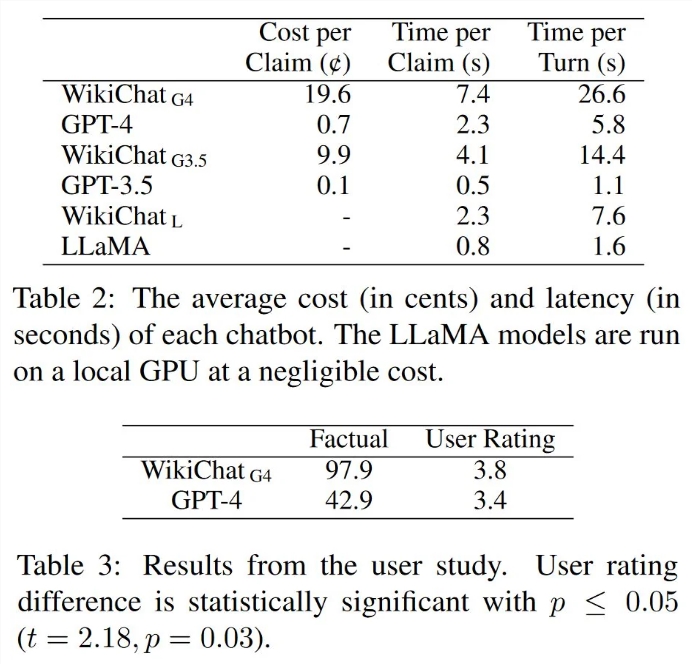
通过WikiChat,我们有望有效应对大型语言模型的幻觉问题,使得这些模型在提供信息时更加可靠和准确。
项目网址:https://top.aibase.com/tool/wikichat
论文网址:https://arxiv.org/abs/2305.14292v2
不到一年,「SeaArt」如何从内部工具走向千万访问量toC产品
SeaArt,是AI图片网站里相对独特的存在,由成都一家游戏公司孵化成立,却在图片领域做得顺风顺水。2024年3月份,SeaArt全球访问量突破1000万,在全球AI产品网站流量总榜上排名53位。我们随后也对该产品进行了拆解,从产品设计来说,SeaArt最吸引人的一点是通过设计不同门槛的功能,形成了一个拥有内容生产到内容消费的社区生态,满足不同用户需求,降低运转的负载。站长网2024-06-27 18:43:510001迪士尼成立特别小组探索通过人工智能的使用来削减成本
站长之家(ChinaZ.com)8月9日消息:据路透社报道,华特迪士尼公司已组建了一个特别小组,以研究人工智能在其各个业务单位中的潜在应用,包括降低成本和提升客户体验。尽管好莱坞编剧和演员的持续罢工使一些人工智能技术成为焦点。站长网2023-08-09 09:13:260000微软因安全问题暂时禁止员工使用ChatGPT
**划重点:**1.🌐微软暂时禁止员工使用ChatGPT,引起关注。2.💰尽管是OpenAI最大的投资者,微软提到ChatGPT是第三方服务,存在安全隐患。3.⚡️禁用行为被迅速撤销,微软称之为失误,强调推荐使用更安全的BingChatEnterprise和ChatGPTEnterprise。站长网2023-11-10 18:01:200000百度造车调整,小米没提造车
最近的新能源汽车市场真是云波诡谲。先是前几天比亚迪喊在一起,众品牌响应,但长城汽车言辞激烈不想在一起;昨天到今天又有三件事值得关注:恒大汽车融资了,雷军onemorething没提小米汽车,百度不再独立造车了。重点聊聊百度和小米的造车。01百度造车之变:因资质,还是梦醒站长网2023-08-16 15:02:140000AI视频类工具又出黑马!Tonic可自动选择并转换视频中的片段
近日,一款名为Tonic的AI视频平台引起不少用户的关注,它在结合AI视频和内容消费方面表现出色。这一平台具有极低的视频AI转换成本,同时呈现出卓越的效果。Tonic的独特之处在于,它能够自动选择并转换视频的一小段,实现与原视频内容的完美融合。下载地址:https://apps.apple.com/cn/app/tonic-ai-video-editing/id6448806466站长网2023-12-20 11:09:560000