谷歌多模态图像生成模型Instruct-Imagen 整合LLM和SD生态
站长网2024-01-05 14:15:560阅
谷歌的Instruct-Imagen模型展现了多模态图像生成领域的强大力量,成功整合了大型语言模型(LLM)和现有的自监督学习(SD)生态系统。
这一模型的核心优势在于其能够通过自然语言和输入内容智能地调用SD生态系统中的各种模型,实际上,相当于利用LLM将SD生态中的Lora和Controlnet等模型打造成智能Agents。

论文地址:https://browse.arxiv.org/html/2401.01952v1
具体而言,Instruct-Imagen引入了多模态指令,使任务表示可以普遍来自多种模态,包括文本、边缘、掩码、样式和主题等。这为模型提供了更全面的信息基础,使其能够更好地理解和执行任务。
研究者还提出了执行检索增强训练和多模态指令调整的建议,以适应预训练的文本到图像模型,从而更好地遵循多模态指令。这种方法的巧妙之处在于使模型能够更加灵活地适应各种任务,并提高了其性能和泛化能力。
Instruct-Imagen是一个统一的模型,专门设计用于处理异构图像生成任务,它超越了各自领域的多项最先进技术。这意味着Instruct-Imagen不仅能够在已知任务上表现出色,还能推广到看不见的复杂任务,而无需进行任何临时设计。
Instruct-Imagen的问世不仅是对多模态图像生成领域的一次重大推动,也为将语言和图像生成有机地结合提供了一种强大的解决方案。这一技术创新为实现更广泛、更智能的图像生成任务打开了新的可能性。
0000
评论列表
共(0)条相关推荐
半托管、平台化,跨境电商硝烟再起
"ShopLikeaBillionaire!"(像亿万富翁一样购物)Temu今年再次豪掷千万美元登上NFL(美式橄榄球联盟)超级碗联赛,连续6次植入30s广告。伴随着轻快的音乐,动画主人公载歌载舞,印着Temu小箱子如有魔法,不仅帮人换新衣,还把世界染成Temu标志性的橙色。令美国观众感叹:“到底要在超级碗看多少次Temu广告!”站长网2024-02-21 17:48:370000零一万物开源Yi-1.5模型 在编码、数学、推理方便表现良好
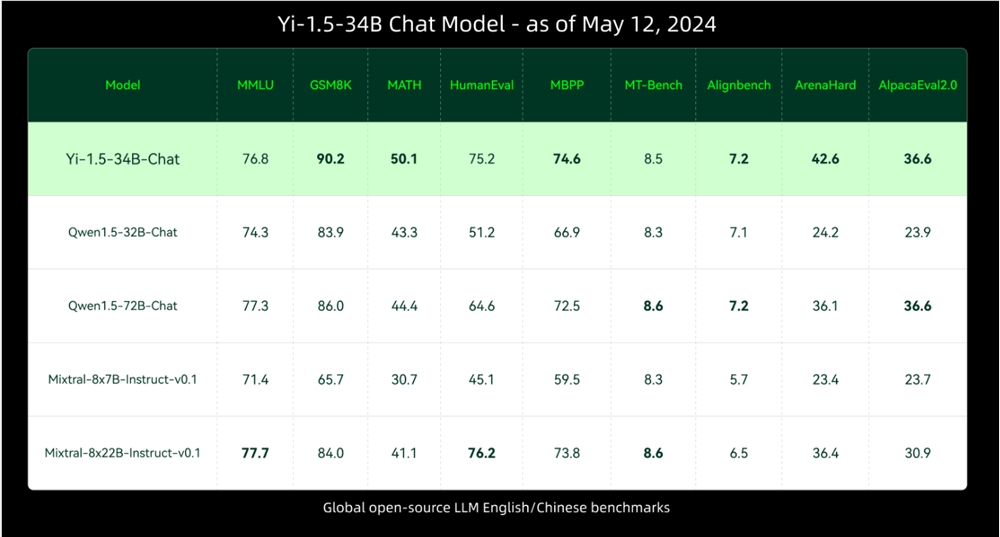
零一万物(01-AI)近日发布了其模型家族的新成员——Yi-1.5(6B、9B、34B),并宣布这些模型均采用Apache2.0许可开源。Yi-1.5是Yi模型的升级版,它在编码、数学、推理和指令遵循能力方面展现出更强的性能,同时保持了在语言理解、常识推理和阅读理解方面的卓越能力。主要特点:多种规模的模型:提供6B、9B和34B三种不同规模的模型,包括基础版和聊天版。站长网2024-05-13 12:13:320000贾跃亭全新品牌FX官宣!首款MPV车型谍照正式发布
快科技1月9日消息,FaradayFuture(FF)第二品牌FaradayX(FX)通过线上直播发布了两款原型车及品牌标志,FX首款车型为MPV,第二款为FX6,预计FX6具有SUV定位。据悉,FXMPV计划今年第二季度发布,FX6将在3月公布更多信息。FF已与中国四家一线主机厂签署协议,可能意味着FX品牌车型将以代工方式进入国内市场。0000董明珠:给躺平的人合适的岗位 他们可能会逐渐改变
近日,格力电器董事长董明珠在央视对话节目中分享了她对“躺平”员工的看法。她强调,为躺平的员工提供合适的岗位并发挥他们的长处至关重要。在对话中,主持人陈伟鸿提出了一个关于年轻员工躺平现象的问题,询问董明珠会给予这些年轻人怎样的建议。董明珠回应称:“我认为对于躺平的员工,应该为他们提供一个合适的岗位。在这个环境中,他们受到的文化影响可能会使他们逐渐改变。”站长网2024-03-05 11:48:520000现场参加了OpenAI的大会,我感觉属于上个时代的开发者被干掉了
OpenAI这场注定载入人类科技史册的发布会已过去一天,但显然它的后劲很大,人们依然在尝试理解它的意义。铺天盖地的分析和梳理很多,而一手信息同样重要。《硅星人》和现场参加了大会的开发者聊了聊,整理了这份自述,它可能可以帮助我们更好的理解发生了什么。站长网2023-11-10 17:05:110000