12秒内AI在手机上完成作画!谷歌提出扩散模型推理加速新方法
只需12秒,只凭手机自己的算力,就能拿Stable Diffusion生成一张图像。
而且是完成了20次迭代的那种。
要知道,现在的扩散模型基本都超过了10亿参数,想要快速生成一张图片,要么基于云计算,要么就是要本地硬件够强大了。
而随着大模型应用逐渐普及开来,在个人电脑、手机上跑大模型很可能是未来的新趋势。
由此,谷歌的研究员们带来了这篇新成果,名字就叫Speed is all you need:通过GPU优化加速大规模扩散模型在设备上的推理速度。

三步走优化加速
该方法是针对Stable Diffusion来做的优化,但同时也能适应其他扩散模型。面向的任务是从文本生成图像。
具体优化可以分成三个部分:
设计专门的内核
提升Attention模型效率
Winograd卷积加速
首先来看专门设计的内核,它包括了组归一化和GELU激活函数。
组归一化是在整个UNet体系结构中实现,这种归一化的工作原理是将特征映射的通道划分为更小的组,并对每个组独立归一,使组归一化较少依赖于批大小,并且能适应更大范围的批处理大小和网络架构。
研究人员以GPU着色器(shader)的形式设计了一个独特的核,能在没有任何中间张量的情况下,在单个GPU命令中执行所有内核。
GELU激活函数中,包含大量的数值计算,如惩罚、高斯误差函数等。
通过一个专用着色器来整合这些数值计算以及伴随的分割和乘法操作,使得这些计算能放在一个简单的draw call里。
Draw call是CPU调用图像编程接口,命令GPU进行渲染的操作。
接下来,到了提升Attention模型效率方面,论文介绍了两种优化方法。
其一是部分融合softmax函数。
为了避免在大矩阵A上执行整个softmax计算,该研究设计了一个GPU着色器来计算L和S向量以减少计算,最终得到一个大小为N×2的张量。然后将softmax计算和矩阵V的矩阵乘法融合。
这种方法大幅减少了中间程序的内存占用张量和总体延迟。
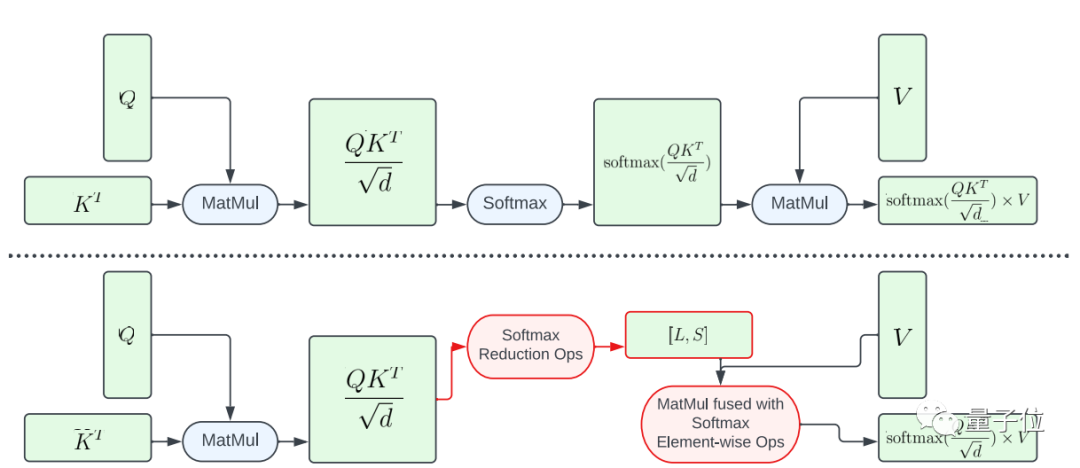
需要强调的是从A到L、S的计算映射的并行是有限的,因为结果张量中的元素比输入张量A中的元素数量要少得多。
为了增加并行、进一步降低延迟,该研究将A中的元素组成block,将归约操作(reduction operations)切分为多个部分进行。
然后在每个block上执行计算,然后将其简化为最终结果。
利用精心设计的线程和内存缓存管理,可以在多个部分实现使用单个GPU命令降低延迟。
另一种优化方法是FlashAttention。
这是去年火起来的IO感知精确注意力算法,具体有两种加速技术:按块递增计算即平铺、并在后向传递中重新计算注意力,将所有注意力操作融合到CUDA内核中。
相较于标准Attention,这种方法能减少HBM(高带宽内存)访问,提高整体效率。
不过FlashAttention内核的缓存器密集度非常高(register-intensive),所以该团队是有选择性地使用这一优化方法。
他们在注意力矩阵d=40的Adreno GPU和Apple GPU上使用FlashAttention,其他情况下使用部分融合softmax函数。
第三部分是Winograd卷积加速。
它的原理简单来说就是使用更多的加法计算来减少乘法计算,从而降低计算量。
但弊端也很明显,将会带来更多的显存消耗和数值错误,尤其是在tile比较大的情况时。
Stable Diffusion的主干非常依赖3×3卷积层,尤其是在图像解码器方面,这里90%的层都是由3×3卷积层构成的。
研究人员分析后发现,在使用4×4大小的tile时,是模型计算效率和显存利用率的最佳平衡点。

实验结果
为了评估提升效果,研究人员先在手机上进行了基准测试。

结果表明,两部手机在使用了加速算法后,生成图片的速度都明显提升。
其中三星S23Ultra的延迟降低了52.2%,iPhone14Pro Max上的延迟降低了32.9%。
在三星S23Ultra上端到端从文本生成一张512×512像素的图片,迭代20次,耗时在12秒以内。
论文地址:
https://arxiv.org/abs/2304.11267
雷军称想去阿勒泰散班味 希望能驾驶小米SU7亲自前往体验
7月17日,小米创始人雷军在社交平台发布了一段视频,表达了他想驾驶小米SU7前往阿勒泰放松心情的愿望,这一想法迅速引发了网友的广泛关注和讨论。雷军在视频中提到,阿勒泰最近非常热门,他也被其吸引,希望能亲自前往体验。同一天晚些时候,阿勒泰地区文体广旅局局长德丽达·那比通过视频回应了雷军,她不仅邀请雷军来访,还热情推荐了阿勒泰的自然风光和丰富的户外活动。站长网2024-07-18 11:44:420000人工智能将面孔识别技术带入动物界:AI 被用来识别鹅的面孔
站长之家(ChinaZ.com)11月6日消息:维也纳大学的生物学家SoniaKleindorfer博士,现任KonradLorenz行为与认知研究中心主任,最近发起了一项突破性研究。继承了著名的奥地利生物学家KonradLorenz研究灰雁鹅群行为的遗产,Kleindorfer博士及其团队开发了一种用于灰鹅面部识别的人工智能工具,旨在提高对鹅群个体识别的准确性。站长网2023-11-06 12:08:540000ImageReward奖励模型:让文本到图像合成更符合人类偏好
StableDiffusion等生成式AI模型在文本到图像合成方面越来越受欢迎。像CLIP或BLIP这样的文本图像评分方法可以评估模型生成的图像是否与文本提示匹配,但它们并不总是符合人类的偏好和感知。站长网2023-05-08 11:19:080006小米交卷大模型,全新小爱同学实测来了
果然只有雷军和小米,能抢走风口上大模型的热度。在雷军的年度演讲分享中,讲武大求学经历,分享学霸4年大学2年完课经验;讲被《硅谷之火》点燃,勤奋练习写最好的代码,开启第一次创业的往事;最后加入金山、创办小米,一路坚持梦想、实现梦想、不断成长的知行合一……于是雷军超燃演讲刷屏之下,自家大模型前脚刷新的纪录、引发的热议,都被盖过了。站长网2023-08-19 13:07:110000土味网红“Giao哥”转型,从互联网小丑变成人生导师
谁也没想到,几年过去了,giao哥竟讲起了成功学。也许你没看过他的直播,但你一定听过他曾经那句“一给我里giaogiao”;还有他的经典表情包“我太难了”。因此走红的giao哥,在短视频上凭借土味内容短期内揽获百万粉丝。不过现在他变了,不再是把自己当笑料吸引眼球的giao哥,而是坐在霸道前讲着人生哲理的展亚鹏。“如果不是为了生活,谁愿意去扮小丑。”站长网2023-10-31 13:56:330000