谷歌AI提出视觉语言模型PixelLLM:能够进行细粒度定位和视觉语言对齐
**划重点:**
1. 🧠 谷歌研究团队与加州大学圣迭戈分校合作,提出了一种名为PixelLLM的智能模型,可实现细粒度定位和视觉-语言对齐。
2. 🌐 PixelLLM通过在语言模型的每个输出单词与像素位置之间建立密集对齐,成功解决了大语言模型在定位任务中的挑战。
3. 📈 在密集目标描述、位置条件描述和引用定位等视觉任务中,PixelLLM展现出卓越的性能,证明其在视觉-语言对齐和定位方面取得了最先进的结果。
谷歌AI研究团队与加州大学圣迭戈分校的研究人员合作,提出了一种名为PixelLLM的智能模型,旨在解决大型语言模型在细粒度定位和视觉-语言对齐方面的挑战。这一模型的提出受到了人类自然行为的启发,尤其是婴儿描述其视觉环境的方式,包括手势、指向和命名。
PixelLLM的独特之处在于,它通过在语言模型的每个输出单词与像素位置之间建立密集对齐,成功地实现了对定位任务的精准处理。为了实现这一目标,研究团队在单词特征之上添加了一个微型多层感知器(MLP),使其能够回归到每个单词的像素位置。低秩微调(LoRA)的使用使得语言模型的权重可以被更新或冻结,同时模型还能够接收文本或位置提示,以提供根据提示定制的输出。
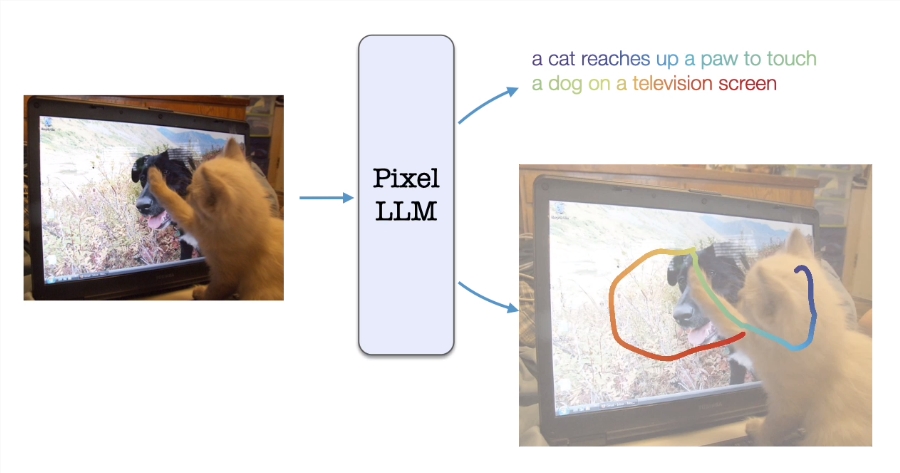
PixelLLM的整体架构包括图像编码器、提示编码器和提示特征提取器。大型语言模型被馈送以提示为条件的图片特征和可选的文本提示,输出形式为每个单词的定位和字幕。该架构具有输入或输出语言或位置的多样性组合,对于各种视觉-语言活动具有灵活性和适应性。
研究团队对PixelLLM进行了评估,应用于密集目标描述、位置条件描述和引用定位等视觉任务。令人瞩目的性能指标包括在RefCOCO引用定位上的89.8P@0.5,Visual Genome条件描述上的19.9CIDEr以及密集目标描述上的17.0mAP。通过在RefCOCO上进行的消融研究显示,与其他定位公式相比,PixelLLM在密集像素定位公式上取得了3.7点的增益。
PixelLLM的主要贡献总结如下:
1. 引入了一种新的视觉-语言模型PixelLLM,能够生成单词定位并生成图片字幕。
2. 该模型支持文本或可选的位置提示,除了图片输入。
3. 使用本地化叙述数据集进行每个单词的本地化训练。
4. 该模型能够适应各种视觉-语言任务,包括分割、位置条件字幕、引用定位和密集描述。
5. 在位置条件字幕、密集描述和引用定位与分割等方面,该模型展现出卓越的性能。
这一研究成果标志着在大型语言模型领域取得的一项重要进展,为实现更精确的视觉-语言对齐和定位打开了新的可能性。
项目体验网址:https://jerryxu.net/PixelLLM/
论文网址:https://arxiv.org/abs/2312.09237
Co-Star推出AIGC占星程序 起步价1美元
科技公司Co-Star开发了一款使用AI进行每日占星读数的程序。用户可以向该程序提出问题,并输入自己的出生日期、时间和地点,程序将生成基于占星知识的答案。Co-Star的方法类似于传统的占星术,但它使用AI生成每日读数,其中的文本内容来自于占星家和诗人团队编写的数据库。目前,该程序可免费使用,但服务的起价约为1美元。站长网2023-07-06 16:40:440002小米14获抖音电商年度大奖:刷新国产智能手机销量纪录
站长之家(ChinaZ.com)1月16日消息:近日,小米官方旗舰店在社交媒体上宣布,小米14在抖音电商平台上首发,成功获得了2023抖音电商金营奖年度品牌营销大奖。据获奖理由显示,小米14首发15分钟内,抖音电商GMV(交易总额)突破了亿元大关,这一成绩刷新了抖音电商平台年度国产智能手机销量记录。。站长网2024-01-16 16:17:020000蚂蚁集团CodeFuse代码大模型开源ModelCache大模型语义缓存
蚂蚁集团旗下CodeFuse代码大模型宣布开源了ModelCache大模型语义缓存,可以降低大型模型应用的推理成本,提升用户体验。站长网2023-11-06 16:29:240000爱奇艺限制投屏案引热议 原告呼吁:对所有受损会员合理补偿
快科技11月14日消息,11月初,爱奇艺限制投屏案二审判决,二审维持了一审判决,即爱奇艺方须在老会员有效期内持续提供高清投屏,且须补偿41天黄金会员时长。今日,爱奇艺限制投屏案朱元律师”微博发文表示:诉讼不是活动,补偿不是赠送,不接受爱奇艺方以活动赠送的方式履行生效判决。”朱元再次呼吁,请爱奇艺方能够作出公开回应,对所有同等受损情形会员作出合理补偿。站长网2024-11-17 10:40:540000抖音直播:低俗搭讪、恶俗PK等将直接封禁 不再进行警告
抖音直播发布《户外直播管理规范》,进一步加强对直播账号、内容的管理,从严整治户外低俗直播乱象。针对低俗搭讪、恶俗PK及恶意炒作几类行为,平台将不再进行警告等提示,视严重程度直接进行短期或长期封禁,包括但不限于以下几种情况:1、不经过对方同意直接上前搭讪拍摄,并坚持追拍、偷拍。2、在直播PK中执行刺激性互动游戏、刻意制造低俗恶俗PK氛围。站长网2023-08-02 15:02:200000