AI生成视频:有点惊艳,有点离谱
AI生成的视频,正在入侵互联网。
此前,我们已经见识了完全由AI制成的科幻预告片《Trailer:Genesis》,以及用AI合成的《芭比海默》预告片。这两部脑洞大开的片子,让我们见识了AI的神奇。
现在,越来越多AI视频工具正在被开发出来,批量制造短视频和电影片段,其生成效果让人惊叹,使用门槛却低到“令人发指”。
比如用Pika生成的这个:
用Runway Gen-2生成的这个:
以及用Neverends生成的这个:
不需要复杂的代码,也不需要深奥的指令,只需要一句话,或者一张图片,AI就能自动生成动态视频。如果想修改,同样只需要一句话,指哪改哪。喜欢做视频的同学,再也不用四处找素材、熬夜剪辑了。
在创投圈,视频生成类AI正在取代大语言模型,成为近期最热门的赛道。前段时间出圈的Pika,给这团火又添了一把柴。
AI视频这阵风,能吹多久?
AI生成视频,这次有点东西
用AI生成一段视频不是什么难事,区别在于生成什么样的视频。
经常剪视频的人可能知道“一键成片”,在剪映等视频工具里输入脚本,系统可直接生成与脚本匹配的视频;在一些数字人平台上传一张照片,AI生成一个数字人,在口播时能自动对口型。
这是AI,但不是我们今天讨论的AI。
本文提到的AI生成视频,指的是生成有连续逻辑的视频,内容之间有关联性与协同性。它不是根据脚本把图片素材拼接成视频形式,也不是用程序驱动数字人“动手动嘴”。它更接近于“无中生有”,实现难度更高。
比如以下这段视频,就靠一句指令生成:
视频中的汽车、树叶、光影,是AI靠自己的知识储备和经验“画”出来的,或者说是“瞎编”的。当然,是根据用户的要求“瞎编”。
再看以下这段视频,就靠一张静态图片,AI自动拓展成视频。
图片中的人物、船只、水流本来都是静止的,AI将它们变成了动态。
AI还可以对原视频进行扩充,把场景“补”齐,比如从只有上半身扩充到全身,以及构造出人物背后的全景。这跟最近很火的AI扩图有点像,AI根据自己的理解,以小见大,以树木见森林。
以上三种生成视频的方式,就是现在流行的AI视频“三件套”:文生视频、图生视频、视频生视频。简言之,无论是文字、图片还是视频,都能作为原始素材,通过AI生成新的视频。
从技术角度,这依托跨模态大模型。在输入端,输入自然语言、图像、视频等形式的指令,最后都能在输出端以视频的形式呈现。
生成只是第一步,后续还能用AI修改。
请看X网友发布的一段视频:
这个视频体现了两个重要的功能:一键换装,一键增减物品。这也是Pika在1.0版本上线时重点介绍的功能。在Pika的宣传片中,只需要一句话输入指令,就能给猩猩戴上墨镜,给一位行走中的女士换装。
这其中的厉害之处不在换装,而在换装的方式——用自然语言的方式下指令,且整个过程非常丝滑,毫无违和感。通过AI,人们能够轻松编辑并重构视频的场景。
AI还能改变视频风格,动漫、卡通、电影,通通不在话下,比如将现实中的实拍镜头转换为卡通世界,它的效果跟P图软件的滤镜有点像,但更高级。
现在用AI生成的视频,已经能达到以假乱真的效果,国内还有一批公司在研发更新的技术。
这两排人物,每排的六个人动作都一模一样,就像“一个模子里刻出来的”。没错,它们就是通过人物静态图片,绑定骨骼动画生成的。
这是阿里研究院正在进行的一个项目,叫Animate Anyone,它能让任何人动起来。除了阿里,字节跳动等公司也在研发类似技术,且技术迭代很快。
效果很好,但别高兴太早
用简单的自然语言让AI生成定制化的视频,给行业带来的兴奋跟去年的ChatGPT差不多。
文生视频的原理与文生图像类似,但由于视频是连续的多帧图像,所以相当于在图像的基础上增加了时间维度。这就像快速翻动一本漫画书,每页静止的画面连起来,人物和场景就 “动”起来了,形成了时间连续的人像动画。
华创资本投资人张金对「定焦」分析,视频是一帧一帧构成的,比如一帧有24张图片,那么AI就要在很短时间内生成24张图片,虽然有共同的参数,但图片之间要有连贯性,过渡要自然还是很有难点。
目前主流的文生视频模型,主要依托Transformer模型和扩散模型。通过Transformer模型,文本在输入后能够被转化为视频令牌,进行特征融合后输出视频。扩散模型在文生图基础上增加时间维度实现视频生成,它在语义理解、内容丰富性上有优势。
现在很多厂商都会用到扩散模型,Runway的Gen2、Meta的Make-A-Video,都是这方面的代表。
不过,跟任何技术一样,刚开始产品化时让人眼前一亮,同时也会有一些漏洞。
Pika、Runway等公司,在宣传片中展示的效果非常惊艳,我们相信这些展示是真实的,也的确有人在测试中达到类似的效果,但问题也很明显——输出不稳定。
不论是昨日明星Gen-2,还是当红炸子鸡Pika,都存在这个问题,这几乎是所有大模型的通病。在ChatGPT等大语言模型上,它体现为胡说八道;在文生视频模型上,它让人哭笑不得。
瀚皓科技CEO吴杰茜对「定焦」说,可控性是文生视频当前最大的痛点之一,很多团队都在做针对性的优化,尽量做到生成视频的可控。
张金表示,AI生成视频确实难度比较大,AI既要能理解用户输入的语义,图与图之间还要有语义连贯性。
AI生成视频的评估标准,通常有三大维度。
首先是语义理解能力,即AI能不能精准识别用户的指令。你让它生成一个少女,它生成一个阿姨,你让一只猫坐飞机,它让一只猫出现在飞机顶上,这都是理解能力不够。
提示词为 A cat flying a plane,Cartoon style
其次是视频生成效果,如画面流畅度、人物稳定性、动作连贯性、光影一致性、风格准确性等等。之前很多生成的视频会有画面抖动、闪烁变形、掉帧的问题,现在技术进步有所好转,但人物稳定性和一致性还有待提高。我们把一张马斯克的经典照片输入给Gen-2,得到的视频是这样的:
马斯克的脸怎么变得这么有棱角了?还有,这个手是怎么回事......
另外,画面主体的动作幅度一大,就很容易“露馅”,比如转动身体的少女一会儿是瓜子脸一会儿是大饼脸,或是奔跑中的马甩出“无影腿”。
还有一点是产品易用度。AI生成视频最大的变革之一,是大幅降低了使用门槛,只用输入很少的信息就能实现丰富的效果,过去视频工作者用PR、AE制作视频,要在复杂的操作界面点击各种按钮,调节大量参数,现在你只用打字就可以了。
产品是否易用,是技术能否大规模普及的一个重要前提。AI扩图最近被人们“玩坏”,也是因为操作简单,但效果感人。当普通小白也能像P图一样P视频,那离爆款产品诞生就不远了。
就当前而言,以上三项指标已有很大进步,尤其是刚上线不久的Pika1.0,各方面表现均衡。但输出不稳定依然是共性问题。
视频时长也是一大限制。现在主流的文生视频产品,正常生成的视频时长一般在3到4秒,最长的没有超过30秒。生成视频的时间越长,对AI的理解、生成能力要求越高,露馅的概率也越大。
因此很多人不得不使用“续杯”的方式,同时还得结合其他素材,才能实现理想效果。而在《芭比海默》《Trailer:Genesis》这两部预告片中,作者用到了Midjourney(处理图像)、Gen-2(处理视频)、CapCut(剪辑视频)等多种工具。
吴杰茜表示,当前市面上的AI文生视频产品,生成的视频时长最多也就十多秒,瀚皓科技即将推出的产品试图做到生成任意时长,比如15秒短视频、1分钟左右的短剧,这也能成为一个差异化的特色。
所以就当前而言,想靠AI直接生成一整部大片,还有点早。
争抢AIGC的最后一块拼图
在AIGC的各大细分赛道中,AI文生视频被认为是最后一块拼图,是AI创作多模态的“圣杯”。整个行业的热潮,已经逐步从文生文、文生图,转向了文生视频领域。
成立于2018年的美国公司Runway,一度引领AI生成视频浪潮。它在2023年2月推出的Gen-1,主打视频转视频,能改变视频风格;3月推出的Gen-2,实现了用文字、图像或视频片段生成新视频。
Gen-2将生成视频的最大长度从4秒提升到了18秒,还能控制“镜头”,用“运动笔刷”随意指挥移动,一度是文生视频领域最先进的模型。
Runway的创始团队有很强的影视、艺术背景,因而客户主要是电影级视频编辑和特效制作者,他们的技术被用在了好莱坞大片《瞬息全宇宙》中。2023年下半年,Runway完成一笔过亿美元的融资,公司估值超过15亿美元。
最新玩家是Pika,这家公司由两个在美国读书的华人女博士退学创办,公司成立仅8个月,员工4人。Pika进展神速,11月底发布的全新文生视频工具Pika1.0,在各大社交媒体迅速走红。再加上创始人爽文大女主的人设,被国内媒体疯狂报道。
一位AI创业者对「定焦」说,Pika采用了差异化的打法,主打动画生成,规避了AI生成视频在逼真度和真实性方面的缺陷。另外Pika在正式推出1.0版本之前,已经在discord积累了一定数量的用户。
除了这两家公司,AI视频领域的玩家还有Stability AI,它最知名的产品是文生图应用Stable Diffusion,11月刚发布了自己的首个文生视频模型Stable Video Diffusion;Meta发布了Make-A-Video;Google推出了Imagen Video、Phenaki。
中信建投制图
国内的进展相对慢一些,还没有明星产品出现。已经推出或正在研发文生视频应用的公司有右脑科技、生数科技、万兴科技、美图等。
其中,右脑科技的视频功能在8月开启内测申请。这是一家年轻的公司,2022年9月才成立,已获得获得奇绩创坛、光速光合的投资。生数科技在2023年3月才成立,由瑞莱智慧RealAI、蚂蚁和百度风投联合孵化。
也有一些公司擅长蹭热点,无论主动或被动。
Pika被媒体热炒那几天,A股上市公司信雅达股价暴涨,连续6个交易日接近涨停,累计接近翻倍。这仅仅是因为Pika创始人郭文景为信雅达的实控人郭华强之女,而这两家公司没有任何业务往来,信雅达也没有AI视频生成类相关产品和业务。
炒概念,一直都是资本市场的惯常操作。
360集团在2023年6月发布大模型产品时,顺带也演示了文生视频功能,号称“国内首个实现文生视频功能的大模型产品”“ 全球最先进的人工智能技术之一”。当然,这些自封的称号有多少人会信、这些产品有多少人会用,我们不得而知。
在图片领域有优势的美图,也在Pika上线后一周内,发布了视觉大模型MiracleVision4.0版本,主打的功能就是AI视频。不过,这些功能目前尚不可用,得到2024年陆续应用到美图秀秀等产品中。
AI行业太嘈杂,我们常常搞不清,哪些公司是做产品,哪些是来炒股的。
抛开这些杂音,AI文生视频技术本身是好的,有望推动生产力革命,加速AIGC技术产业化的进程。中信证券认为,文生视频有望率先在短视频和动漫两个领域落地,短视频制作中的传统实拍模式有望被生成式技术替代。
或许用不了多久,短视频就不再需要真人出镜、拍摄和录制。这不仅仅指口播场景,而是任何你能想象得到的场景,以及大量你想象不到的形象。随之而来的,是AI生成的视频大举入侵互联网,AI像流水线一样批量制造短视频,短视频的游戏规则也要变了。
中兴通讯推出GPT无线AR眼镜 采用与GPT同类的AIGC算法
在日前开幕的上海世界移动通信大会上,中兴通讯展示了一款全新的智能眼镜nubiaNeoAir。nubiaNeoAir是一款支持语音指令的无线AR眼镜,采用了与GPT同类的AIGC算法。它搭载了多个AI大模型能力的GPT模型,可以实现即时问答、与人工智能语音助手进行聊天和语音查询等智能交互功能。站长网2023-06-30 19:25:090000ChatGPT联动脑机接口 成功用脑电波发邮件
最近,Araya团队在脑机接口实验中成功地使用了ChatGPT,并利用EEG数据训练AI模型来操纵Gmail。该目标是为了开发BMI技术,以帮助残障人士参与社交互动和沟通,并且该技术还可以应用于提高客户服务场景的响应速度。这一成果让一些网友惊叹科幻成真了,但也有一些网友表示并不惊奇,因为非侵入式的脑机接口在好几年前就已经存在了,即使没有使用AI。站长网2023-05-16 16:23:080000卢伟冰回应小米15系列供不应求:已安排加速生产
小米集团的新款旗舰手机系列——小米15系列,自10月31日开售以来,受到了市场的热烈反响,起售价为4499元。小米集团总裁卢伟冰分享了消费者在小米之家体验新机的盛况,并透露小米15系列自发布以来持续热销。面对网友关于新机供不应求的评论,卢伟冰回应称,公司已经安排加快生产速度以满足市场需求。0000FF首款车搞起了Web3,软件实现资产化
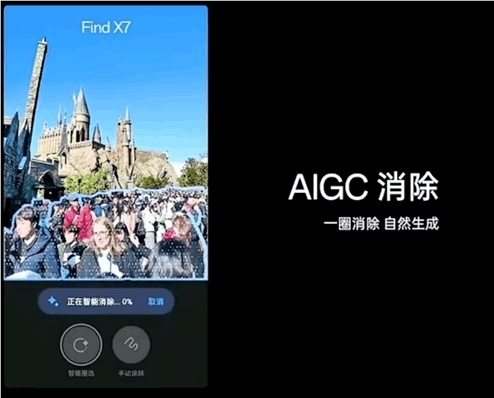
当回国还是个未知数时,遥在美国的贾跃亭近期的活跃度却明显提升。这与其创办的法拉第未来FF91即将交付有很大关系。北京时间5月31日上午9点,法拉第未来(以下简称FF)召开了FF91&FaradayFuture2.0终极发布会,在这次发布会上,FF91亮相且由创始人贾跃亭亲自驾驶上路。站长网2023-06-01 15:54:530000实测OPPO大模型手机:路人甲一抹就没,电话粥一键总结
都说2024会是AIAgent元年,杀手级应用将要出现。但就在开年,已经看到不一样的思路。与其做单个Agent应用,不如把系统能力提升为Agent级。不仅让大模型加持智能助手,还能让系统工具也具备AIGC能力。比如一键消除照片中的人群:让AI总结打电话内容:而且语音摘要处理全程加密,生成内容完全存储在本地。如上效果,都来自OPPO最新发布的FindX7系列。站长网2024-01-13 10:15:550000