新AI框架DreamSync:结合图像理解模型的反馈 改善文本到图像合成
**划重点:**
1. 🌐 DreamSync是由南加州大学、华盛顿大学、巴伊兰大学和谷歌研究团队引入的新型人工智能框架,致力于提高扩散型文本到图像(T2I)模型的对齐性和审美吸引力,无需人工标注、模型架构修改或强化学习。
2. 🚀 DreamSync通过生成候选图像,利用视觉问答(VQA)模型进行评估,并对文本到图像模型进行微调,成功解决了T2I模型中对齐和美感的挑战。该框架不依赖特定架构或标记数据,采用视觉语言模型(VLMs)鉴别生成图像与输入文本之间的差异。
3. 📈 DreamSync通过模型不可知的框架,结合VLMs的反馈,取得了在T2I模型上显著的对齐和视觉吸引力改进,超越了基准方法,拓展了在分布内外场景中的适用性。
来自南加州大学、华盛顿大学、巴伊兰大学和谷歌研究团队的研究人员推出了DreamSync,这是一种新型人工智能框架,致力于解决扩散型文本到图像(T2I)模型中对齐和审美吸引力的问题,而无需进行人工标注、修改模型架构或使用强化学习。
DreamSync的方法是通过生成候选图像,利用视觉问答(VQA)模型对其进行评估,然后对文本到图像模型进行微调。此过程无需特定的架构或标记数据,采用了模型不可知的框架,并利用视觉语言模型(VLMs)来识别生成的图像与输入文本之间的差异。该框架的关键步骤包括生成多个候选图像,使用两个专用的VLMs对它们进行文本忠实度和图像美感的评估,然后选择VLM反馈确定的最佳图像进行文本到图像模型的微调,迭代至收敛。
此外,框架还引入了迭代自举方法,利用VLMs作为教师模型对未标记数据进行标记,用于T2I模型的训练。
DreamSync成功提升了SDXL和SD v1.4T2I模型的性能。在TIFA上进行的实验显示,对SDXL进行三次迭代,文本忠实度提高了1.7%和3.7%,视觉美感提高了3.4%。将DreamSync应用于SD v1.4,文本忠实度提高了1%,TIFA上的得分绝对增加了1.7%,美感提高了0.3%。
在与SDXL的比较研究中,DreamSync在对齐方面表现更好,生成的图像具有更相关的组件和3.4个更正确的答案。在TIFA和DSG基准测试中,DreamSync实现了更卓越的文本忠实度,而不损害视觉外观,显示出随着迭代的逐渐改进。
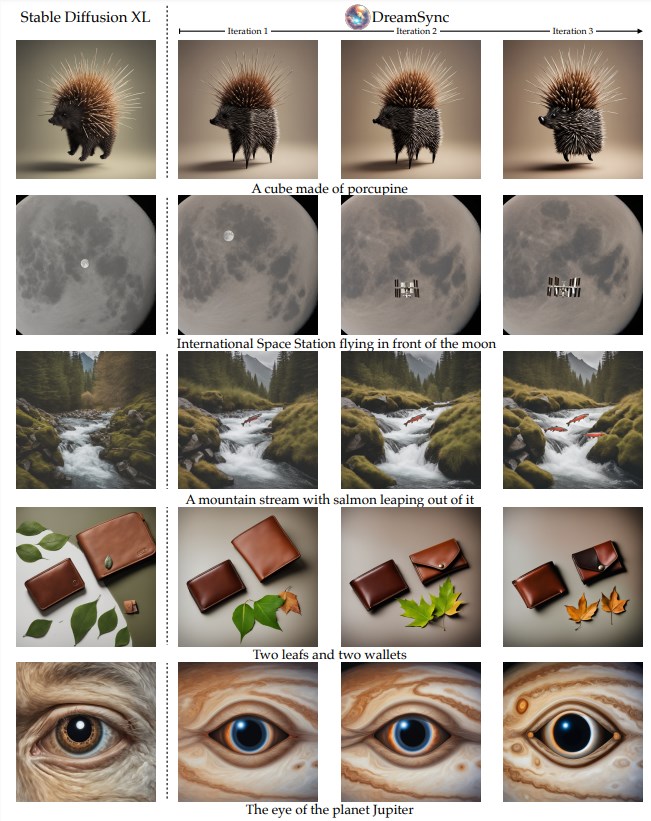
DreamSync是一个多功能的框架,在具有挑战性的T2I基准测试中进行了评估,显示出在分布内外场景中对齐和视觉吸引力方面的显著改进。该框架结合了来自视觉语言模型的双重反馈,并通过人类评分和偏好预测模型进行了验证。
未来,DreamSync的改进方向包括通过详细注释(如边界框)来巩固反馈,调整每次迭代的提示以针对文本到图像合成中的特定改进,探索语言结构和注意力图以增强属性-对象绑定,以及使用人类反馈训练奖励模型,以进一步使生成的图像与用户意图一致。同时,拓展DreamSync的应用到其他模型架构,并在不同场景中进行性能评估和额外研究也是未来持续调查的方向。
论文网址:https://arxiv.org/abs/2311.17946
小米高管上手小米14 最快在本月底正式发布
小米产品经理魏思琪透露,她已经拿到了小米14新品的试用机会,并对其中的人像样张赞不绝口。据悉,小米14预计将成为小米史上性能最强劲的旗舰手机,最快在本月底正式发布。小米14将搭载高通骁龙8Gen3,与高通骁龙8Gen2相比,骁龙8Gen3增加了一个性能核心,减少了一个能效核心,并且超大核升级为CortexX4,使得安兔兔总成绩超过了200万分。站长网2023-10-09 09:53:540001微软与Mistral AI达成技术合作,加速模型训练和开发
**划重点:**1.🚀微软将通过Azure云服务为MistralAI提供基础AI算力,加速模型训练和开发。2.🌐微软通过Azure云服务向客户提供MistralAI的基础大模型,丰富选择,包括最新旗舰大模型MistralLarge。3.👥合作开发大模型,提供部署、微调等服务,加强MistralAI在大模型领域的竞争力。站长网2024-02-27 09:21:070000AI日报:百度“橙篇”APP上线;知网状告秘塔AI搜索;Midjourney推全新图像编辑器;清华大学推万字AI系统LongWriter
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/1、百度AI原生应用“橙篇”APP上线集成智能搜索、AI热点推荐等功能站长网2024-08-16 15:59:350000新加坡发布管理用个人数据训练AI模型的指南草案
新加坡发布了关于如何管理个人数据用于训练人工智能(AI)模型和系统的指南草案。该指南旨在解释企业使用个人数据训练AI模型和系统时新加坡法律的适用情况,包括研究和业务改进的例外情况。该指南强调了数据的准确性和透明性,并鼓励企业在训练AI模型时使用自己的数据,以确保数据的真实性和相关性。这样做可以提供更多的上下文信息,并减轻与准确性和知识产权侵权等潜在风险相关的担忧。站长网2023-07-20 19:04:370003马斯克硬刚OpenAI,用户惨遭池鱼之殃
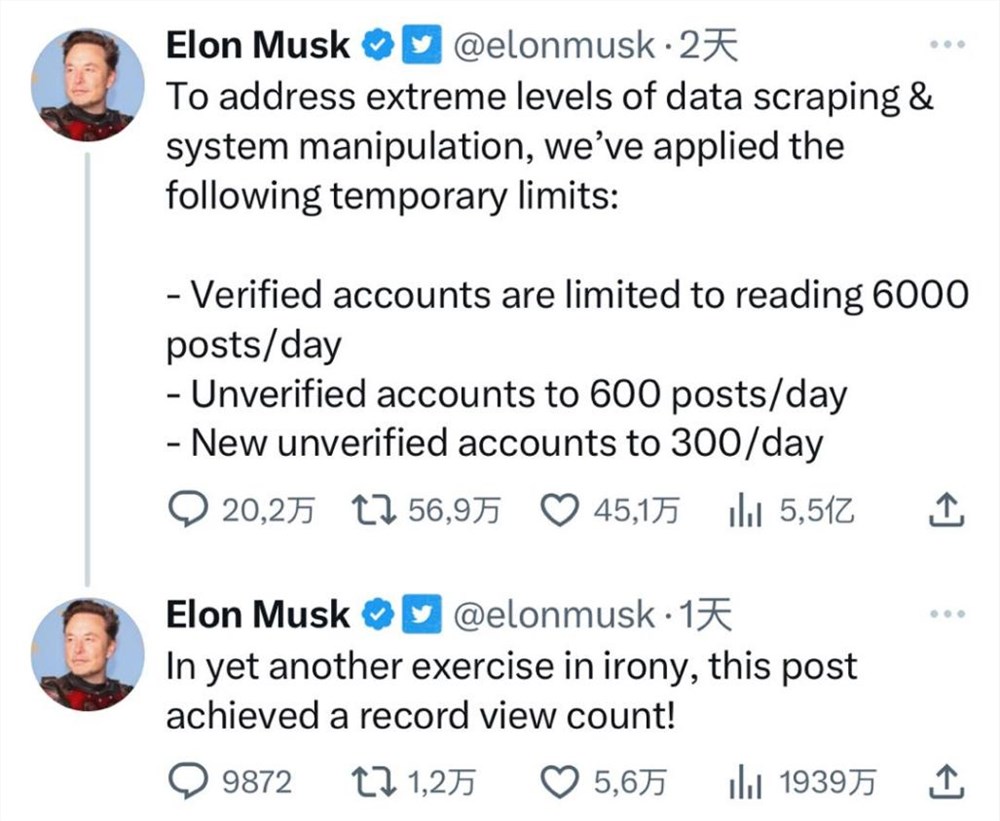
只听说过社交媒体想方设法让用户多停留的,没听说过主动给人加个上限的。如今开眼了,埃隆·马斯克正在给所有推特用户加“未成年人保护”,而这一切,居然是被AI逼的?如今推特用户每天最多能浏览多少推特,不取决于手速或者舍不舍得熬夜,而是有一个明确的数字:已验证(也就是付费的“蓝鸟”服务)账户10000条、未验证账户1000条,而新注册的未验证账户只有500条。站长网2023-07-04 17:13:080001