AI为涂鸦注入生命:一句话让涂鸦变动画!人人都是“神笔马良”
你有没有想过,自己随手画的火柴人能栩栩如生地跳舞,像被赋予了“生命”一般?
现在,只需要简短的一句文本提示,LiveSketch就能让寥寥几笔涂鸦成真,输出生动活泼的的SVG动画片段,而且易于编辑和调整,可以通过文本控制动画的动作和幅度。
人人都是“神笔马良”的时代到了!
来看看Demo效果:
LiveSketch上周发布之后,腾讯AI实验室直接反其道而行之,推出Sketch Video Synthesis,主要功能是将视频中的主体转换为草图线稿风格的动画🥲,并且可以调整大小、填充颜色,还允许用户进行再编辑创作,比如叠加其他图像和涂鸦。
Live Sketch这类技术的背后原理是什么?与当下最流行的图像到视频的扩散模型Runway Gen-2有何不同?应用前景怎么样?“头号AI玩家”进行了一番探究。
一句话让涂鸦变动画,怎么做到的?明明是随意的涂画,AI竟然能准确分辨出人和动物的胳膊和腿,还能有节奏地活动,这些涂鸦是怎么“活”过来的🤔?概括来说,有两个核心逻辑:一是文本驱动视频生成。这依赖大型预训练的文本到视频模型的运动知识,比如哺乳动物和人类应该在地上行走和跑,鸟应该扇动翅膀飞,鱼应该在水里摆尾游动,各得其所。二是提升动作流畅性。为确保动作的自然流畅并保持涂鸦的原本质感,需要从两方面入手:精细的局部形变、涂鸦整体的仿射变形,以此来模拟和学习动作的细节。具体的工作原理,涵盖了以下几个精细化的步骤:1. 草图解析这一步可以理解为给涂鸦加上骨架和关节。每张涂鸦都会被解析成置于白色背景上的一组笔画,每条笔画由一个二维贝塞尔曲线(蓝色)组成,该曲线又由4个控制点(红色)定义。
这样就能够通过预测每一帧每个点的偏移量(绿色),使草图变形,以创建动态效果。即便线条非常潦草抽象,也依然能够准确识别并预测其运动轨迹。
从左到右线条越来越抽象
2. 动态预测那么系统是如何实现动态预测的呢?换句话说,骨架和关节有了,怎么才能让机器看懂并且控制涂鸦做出正确动作呢?这就需要利用嵌入在预训练的文生成视频模型中的动作知识,训练一个多层感知机(Multilayer Perceptron, MLP),又名“神经位移场”,通过调整草图控制点的位移来构建视频的所有帧,并对帧进行渲染。
而草图控制点的位移,会被分至两条路径处理——局部路径和全局路径。局部路径关注草图的细节和微调,通过多层感知机(MLP)预测每个控制点的位移。全局路径处理整体的运动和变化,如旋转、缩放或平移,通过预测全局变换矩阵实现,应用于所有控制点。这使得模型既能够专注于小的局部变化(如弯曲手臂),同时又能够创建大的全局运动或同步效果,例如当物体远离相机时缩小物体。3. 动画合成与输出结合两条路径的处理结果,加上用户的文本输入,系统会生成一连串代表草图变化的帧,形成平滑的动画序列,展示从初始至终态的过渡,最终输出为一段动画。从生成结果来看,如果在提示词中添加“A sketch of”(…的草图),或者“Abstract sketch / Line Drawing”(抽象素描/线条画),动态效果很可能会更好。
和Runway Gen-2比,怎么样?
同样是让图像动起来,LiveSketch的表现与市面上的其他视频生成模型有什么不同?
针对这个问题,LiveSketch团队与4种图像到视频扩散模型,包括Runway的Gen-2、ZeroScope、ModelScope、VideoCrafter1,以及一种为动画儿童人物画而定制的方法进行了比较。
可以看到,同一张静态素描画,不同模型或方法生成的视频效果大相径庭,但有一个共同点是都逊于LiveSketch,就连大名鼎鼎的Gen-2也败下阵来。
以跳舞的芭蕾舞者为例,Gen-2生成的视频出现了明显的风格和动作脱节,上一秒还是素描简笔画,下一秒就直接变成了写实的人体,且动作毫无连贯性可言。其他几种方法生成的视频效果更是抽象🥲。
总体来看,图像到视频的扩散模型无法保持草图的独特特征,且容易受到视觉伪影的影响。
Animated Drawings是专为人形骨骼和固定动画设计的方法,因此不太擅长处理简单抽象的草图,以及非人生物,比如鱼。
值得一提的是,最近,来自阿里的研究团队提出了一种名为Animate Anyone的方法,只需一张人物照片,再配合骨骼动画引导,就能生成动画视频。以往图像动画化与姿态迁移视频的局部失真、细节模糊等问题,也得到很大改善。
正如下面这张动图所展示的,无论是真人还是纸片人,都做着整齐划一、自然流畅的舞蹈动作。
就算是梅西来了,也得乖乖跳“科目三”。
不过,LiveSketch也并非没有局限性。
首先,目前,它只能通过简单地修改描述运动的提示,对生成结果进行一定程度的控制。这些修改和控制仅限于模型可以创建的小动作,且文本提示需要与初始草图的语义一致。
举个例子,你可以让猫摇尾巴、蜷缩成一团、走路,但可能很难让它进行后空翻。
其次,LiveSketch通常会将输入的草图描绘为单个对象,当主体包含多个对象时,则无法进行区分。
比如,我们期望篮球与玩家的手分离,以实现自然的运球动作,但目前还无法实现,因为平移参数是相对于篮球所属的对象的。这一限制或许可以通过进一步的技术发展来解决。
同样地,当被应用于场景草图时,由于系统对单个对象的假设,整个场景的移动显得很不自然。
虽然可以通过更改参数来平衡运动质量和草图保真度之间,但有时草图原本的特征依然会受到损害。比如,这里松鼠的动作没问题,但身体的纵横比却发生了明显的变化。
应用与商业化前景如何?
实际上,让随手画的涂鸦动起来,这种堪比“神笔马良”一样的功能,早就已经证明自己的商业化可行性了。
前微软人机交互专家曹翔博士创立的小小牛科技就是这样一家公司,他们自研的Wonder Painter技术,可以把静态2D图像自动转换为交互式3D动画。
比如,在绘画界面随便画一个穿裙子的姑娘,然后她就可以摇身一变成为动画中的人物,直接开始跳舞:
这项技术已经以游戏的形式,应用在了一些线上营销活动中。
未来,这类技术或许还能在艺术创作、儿童教育等领域大放异彩,大大降低艺术创造的门槛,提升教育的趣味性和互动性。
它允许设计师和创作者将静态图像转化为动画片段,仅通过更改描述动作的文本提示,就可以精细调整动画的动态效果,而无需传统动画的繁琐流程。
如此一来,不仅能提高动画创作的效率,还能拓宽非动画专业人士实现视觉叙事的可能性,让设计师能够将静态的草图或概念以更加生动和动态的方式呈现,从而加深受众的沉浸感和情感联结。这对于讲故事、插图、网站、演示文稿等领域都非常有用。
在生成式AI引导的这一轮产业变革中,动画是最早受到影响的行业之一。
但从目前来看,技术投入成本和方向不够明朗,相关人才缺乏,尚未形成成熟的商业模式;有很多流程使用AI可能比人工更贵,或是更低效等因素,也在制约着AIGC技术在动画行业的应用。
(LiveSketch还处于Paper阶段,没有Code可以部署,GitHub传送门:https://livesketch.github.io/)
Meta要求在平台上发布使用AI处理的政治广告需明确披露
划重点:-Meta将要求广告商在其平台上发布的政治广告中是否包含任何使用人工智能生成或数字修改的内容进行披露。-Meta的政策要求广告商披露其广告活动的资金来源,并将广告存储在Meta的公共广告库中长达七年。-Meta将禁止在2024年美国总统选举的最后一周期间播放任何新的政治、选举或社会问题广告,但对其他国家的选举不适用此规定。站长网2023-11-30 12:06:240000从敌对到盟友?马斯克180亿美元支持特朗普第三次总统竞选
据《华尔街日报》报道,尽管马斯克和特朗普两人几年前有过争执,但马斯克现在似乎全力支持特朗普,并以真金白银的方式表达他的支持。据说,马斯克每月将向一个新的超级政治行动委员会(PAC)捐款约4500万美元,以资助特朗普的第三次总统竞选。站长网2024-07-18 10:48:580001摩根士丹利:随着 Edge AI 走向主流,苹果处于最有利的位置
在人工智能(AI)成为2023年的热门话题之际,投资公司摩根士丹利的一份新报告得出结论,尽管苹果对其AI技术的发展讳莫如深,但该公司已准备好在消费者开始广泛采用基于AI的工具时获得利润。摩根士丹利认为,苹果在AI领域的进展超出了公众的预期,并可能在2024年成为「EdgeAI(边缘AI)」领域的六大「关键受益者」之一。站长网2023-11-09 18:08:120006Anthropic推出Claude2.1:支持第三方 API 的测试版本
站长之家(ChinaZ.com)11月22日消息:据国外报道,虽然OpenAI正经历着生存危机,但Anthropic却在人工智能领域迈出了重要一步。这家由谷歌支持的初创公司,由前OpenAI工程师创立,近期宣布推出了Claude2.1,一款具有突破性的聊天机器人。站长网2023-11-22 14:57:170001腾讯宣布上线吃瓜地图 帮助瓜农增加收入
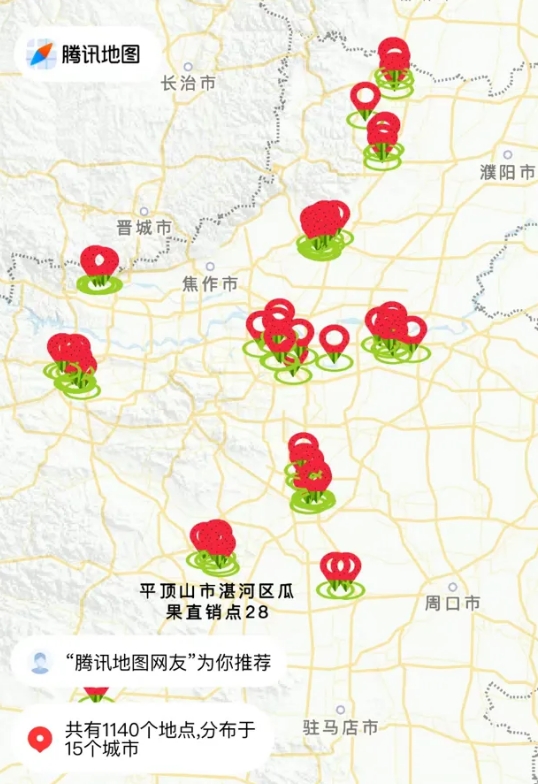
腾讯地图联合大河报和河南省各地城管系统推出了“河南夏日瓜果地图”,覆盖了全省15个地市的1140余个瓜果销售点位。用户只需打开腾讯地图App或小程序,搜索“河南吃瓜地图”,即可快速找到最近的销售点,方便地购买新鲜瓜果,同时也帮助瓜农增加收入。站长网2024-07-12 11:58:080000