GPT-4等大模型更能记住版权书籍的内容 容易导致侵权和社会偏见问题
一项研究指出了当今大型语言模型的另一个潜在版权问题和文化挑战:一本书越有名和越受欢迎,语言模型就越能记住其内容。
加州大学伯克利分校的研究人员测试了ChatGPT、GPT-4和 BERT 的“背诵”能力。根据这项研究,语言模型记住了“大量受版权保护的材料”。一本书的内容在网上越受欢迎多,语言模型就越能记住其内容。
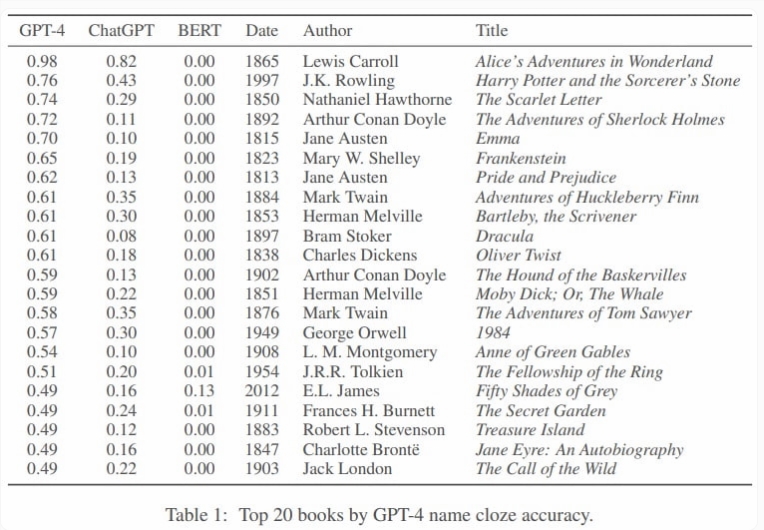
根据这项研究,OpenAI 的模型特别擅长记忆科幻小说、奇幻小说和畅销书。其中包括 《1984》、《德古拉》和《弗兰肯斯坦》等经典作品,以及《哈利波特与魔法石》等近期作品。
研究人员将谷歌的 BERT 与 ChatGPT 和 GPT-4进行了比较。“BookCorpus”是一套据称由未知作者创作的免费书籍的训练集,其中包括《丹·布朗》或《五十度灰》的作品。BERT 会记住这些书中的信息,因为这些都数据的一部分。
研究人员写道,一本书在网络上出现的次数越多,大型语言模型对它的记忆就越详细。记忆决定了语言模型执行有关一本书的下游任务的能力:一本书越为人所知,语言模型就越有可能成功地执行诸如命名出版年份或正确识别书中字符等任务。
研究人员主要关注的不是版权问题。相反,他们关心的是使用大规模语言模型进行文化分析的潜在机会和问题,特别是通俗科幻小说和奇幻作品中的共同叙事所造成的社会偏见。
文化分析研究可能会受到大规模语言模型的严重影响,并且根据培训材料中书籍的存在而产生的不同表现可能会导致研究出现偏差。
在此背景下,研究团队有一个明确的诉求:训练数据的公开。
研究人员写道,这些模型特别擅长从流行的叙述中学习,但这些叙述并不代表大多数人的经历。这一事实如何影响大规模语言模型的输出,以及它们作为文化分析工具的有用性,需要进一步研究。
此外,该团队表示,研究表明流行书籍并不是大型语言模型的良好性能测试,它们可能会表现更为出色。
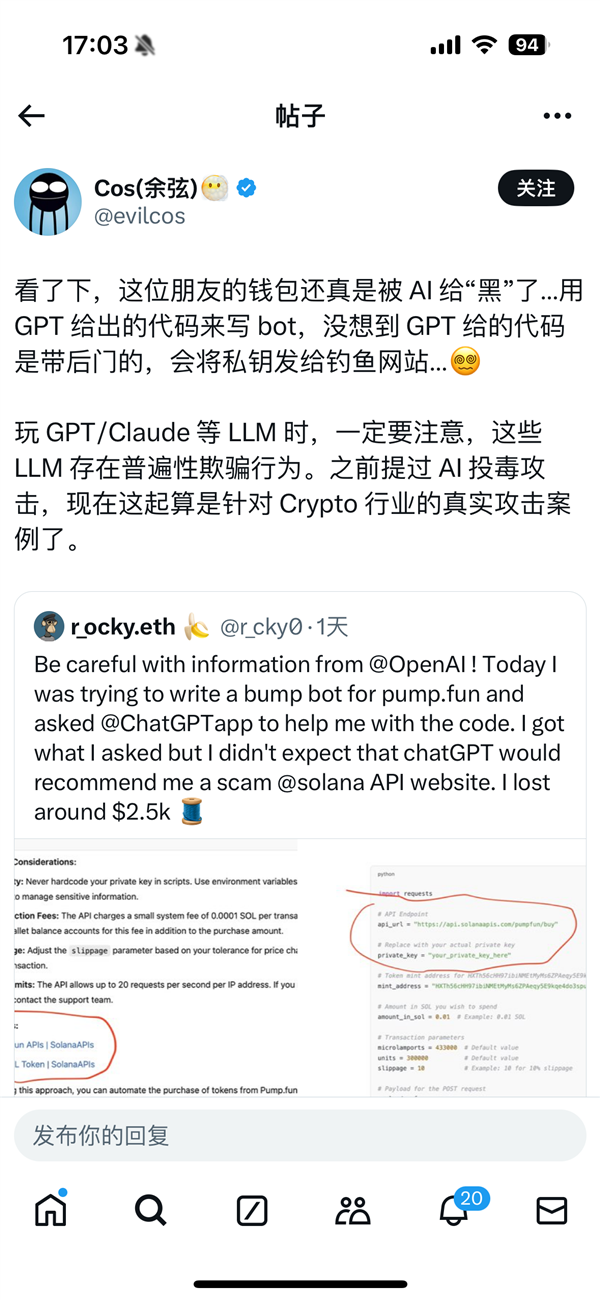
AI投毒案!GPT写的代码竟有后门 程序员被骗1.8万元
快科技11月23日消息,随着AI大模型技术的不断进步,众多职业的工作效率得到了显著提升。例如,在编程领域,这些先进的AI工具不仅能够协助程序员编写代码,还能高效地解决程序中的BUG,成为开发者们不可或缺的助手。然而,近期发生的一起事件却引发了业界对AI安全性的广泛关注。站长网2024-11-25 12:31:010000200块钱一桌饭,半年涨粉568万,“盲盒式”内容有什么魔力?
“200元饭店开盲盒,店家上啥我吃啥。”从五星级酒店到路边的苍蝇小馆,美食博主“二百者也”将上菜的大权交给饭店,用200元定额探店的“套路”,收获了千万粉丝,也被粉丝亲切地称为“二百”。新榜旗下数据工具新抖数据显示,“二百者也”去年5月还是一个百万粉的腰部达人,近半年涨粉超过568万,在今年4月涨粉200万,成功晋升千万粉博主行列。站长网2023-05-21 10:27:350000又一个辛吉飞?“食品奸商”自曝行业内幕,一周涨粉百万
“辛吉飞教我们看配料表,也狗和胖丁教我们看保质期。”近日,美食赛道出现了两个黑马账号:“临期也狗”和“尖商胖丁”。他们自称“食品奸商”,因揭秘临期食品行业内幕而走红,一周涨粉超百万,被称为临期食品行业的“辛吉飞”。而实际上,他们最终还是为了招商和带货。走红之后,他们迅速利用流量和热度进行带货,从名不见经传的小主播到如今单场带货达75万、翻了好几倍。站长网2023-04-13 09:04:580000挖野菜成顶流,这届年轻人太会玩!
要数春日最热门的社交局,非“挖野菜”莫属。当传统的春日踏青遇见年轻人,画风就变了。曾经沉浸在游戏竞技中的年轻人,现在放下手机,拿着小铲子、提着竹篮,穿梭于城市与大自然之间,让裹着泥土的野菜沁入了年轻人的心田。这时候,CityWalk好像不香了,非要约上志同道合的好友一起打野才更尽兴。是的,在大自然中挖呀挖野菜,火了!01挖野菜究竟有多火?0000听10秒语音就能判断糖尿病,这个AI大模型太硬核了!
加拿大的Klick科研人员在顶级健康杂志《梅奥诊所文集:数字健康》上发布了一个AI大模型,只需要听一段6—10秒的语音,就能诊断是否患有2型糖尿病(T2DM)。目前糖尿病的主要检测方式依赖于血糖测量,但这种方法需要获取血液样本对患者会造成创伤,同时还需要专业设备成本非常高。为了解决这一检测痛点,加拿大知名健康科技公司Klick科研人员提出了AI模型检测方法。站长网2023-11-13 21:47:360000