Tanuki通过自动模型蒸馏 轻松构建LLM技术驱动的应用
Tanuki.py是一个用于构建LLM(Large Language Models)驱动应用的工具库。该库旨在通过自动模型蒸馏,实现应用在使用过程中的成本和延迟的逐渐降低,最多可达到90%的成本降低和80%的延迟降低。
Tanuki的使用非常简单,用户只需使用@tanuki.patch和@tanuki.align装饰器即可将LLM引入Python函数。@tanuki.patch用于将LLM嵌入函数体,而@tanuki.align用于通过测试驱动对函数的行为进行对齐。对齐的目的是确保LLM输出与期望的输出一致,从而提高可预测性。
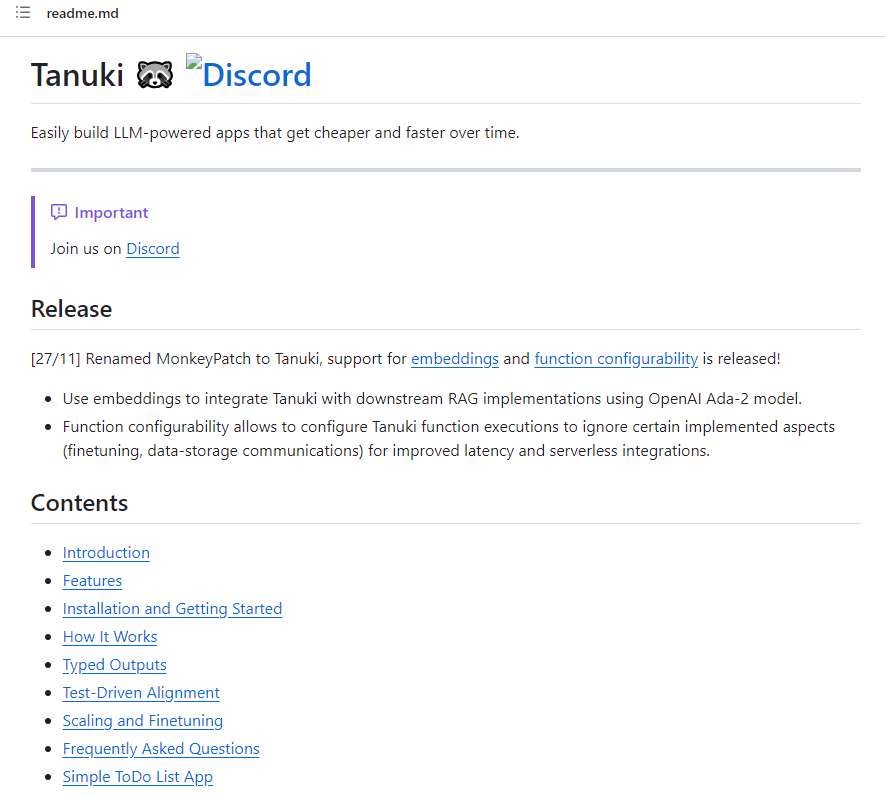
项目地址:https://github.com/Tanuki/tanuki.py
这个工具库的特色之一是对类型的支持。用户可以使用类型提示,如Python基本类型、Pydantic类、Literals、Generics等,确保LLM输出符合函数的类型约束,防止出现意外错误。
除了类型支持,Tanuki还提供了对RAG(Retrieval Augmented Generation)的支持,允许用户通过嵌入输出来集成下游RAG实现。这样,用户可以在降低成本和延迟的同时提高对长篇内容的性能。
在使用Tanuki构建LLM-powered函数时,用户可以通过对齐函数来验证期望的输出。这种测试驱动的对齐方法有助于确认函数是否符合预期行为,捕获行为细微差异,并支持迭代开发。
Tanuki的工作原理是在开发过程中调用tanuki-patched函数时,会使用n-shot配置的LLM生成类型化的响应。响应经过后处理,确保返回正确的类型。这些响应将作为未来训练数据存储,随着数据量的增加,将使用更小的模型进行蒸馏,从而实现更低的计算成本、更低的延迟,无需额外的MLOps努力。
Tanuki.py提供了一种简单而强大的方式,通过LLM构建应用,并通过自动模型蒸馏实现成本和性能的优化。其类型感知、RAG支持和测试驱动的对齐方法使其成为构建可靠、可预测、逐渐优化的LLM-powered应用的理想选择。
埃哲森收购教育初创公司Udacity,打造AI学习平台
##划重点:-🌐埃哲森宣布收购Udacity,以构建聚焦人工智能的学习平台。-💰尽管未透露收购价格,埃哲森宣布投资10亿美元建设名为LearnVantage的技术学习平台。-🚀Udacity创立于2011年,虽然此前有与印度edtech公司Upgrad的谈判传闻,最终被埃哲森收购。站长网2024-03-06 14:20:430000国家邮政局:2023年邮政行业寄递业务量累计完成1624.8亿件
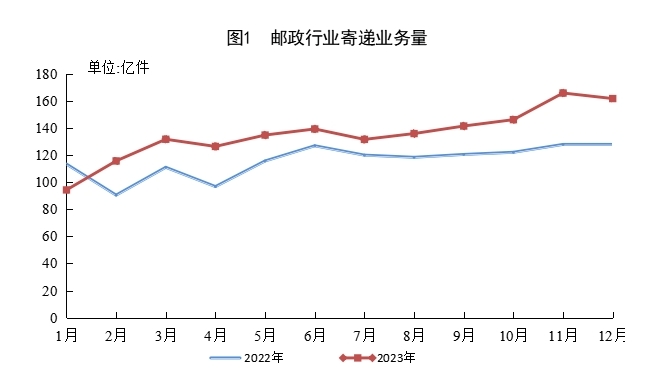
据国家邮政局消息,2023年,邮政行业寄递业务量累计完成1624.8亿件,同比增长16.8%。其中,快递业务量(不包含邮政集团包裹业务)累计完成1320.7亿件,同比增长19.4%。2023年,同城快递业务量累计完成136.4亿件,同比增长6.6%;异地快递业务量累计完成1153.6亿件,同比增长20.5%;国际/港澳台快递业务量累计完成30.7亿件,同比增长52.0%。站长网2024-01-22 10:30:340000Adobe推出20多个,企业版生成式AI定制、微调服务
3月27日,全球多媒体领导者Adobe在拉斯维加斯召开“Summit2024”大会,重磅推出了FireflyServices。FireflyServices提供了20多个生成式AI和创意API服务,支持企业自有数据对模型进行定制、微调,同时可以与PS、Illustrator、Express等Adobe其他产品相结合使用,大幅度简化创意流程。站长网2024-03-27 12:54:210000三星和 SK 加快人工智能半导体的开发以应对 ChatGPT
三星电子和SK海力士正在加快下一代半导体技术的开发,以适应人工智能(AI)时代的到来,而ChatGPT的出现更加加速了这个过程。据业内消息称,三星电子最近开发了业内首款支持ComputeExpressLink(CXL)2.0的128GBCXLD-RAM。站长网2023-05-15 17:52:390000苹果承认iPhone15存在烧屏问题 称iOS 17.1将修复
苹果公司于10月18日发布了iOS17.1RC版本更新,该更新特别针对苹果的iPhone15和iPhone15Pro系列机型。此次更新修复了一个关键问题,即“可能导致图像残留”的问题。自苹果推出iPhone15手机以来,用户反馈出现了严重的烧屏问题。一些用户猜测这可能是OLED显示屏的硬件问题。站长网2023-10-18 21:22:170000