视频编辑利器Pix2Video 无需训练微调
站长网2023-11-29 18:17:040阅
要点:
本文提出了一种基于预训练的图像扩散模型的视频编辑方法,实现文本引导的编辑,无需训练或微调,可推广到广泛编辑领域。
通过自注意力特征注入,该方法在每个扩散步骤中注入前一帧的特征,以保持外观的一致性,解决了视频编辑中的外观变化问题。
引入了潜在更新机制,通过能量函数提高一致性,增强了算法的时间稳定性,减少了时间闪烁的影响。
Pix2Video是一项基于预训练的图像扩散模型的视频编辑研究,致力于实现文本引导的编辑,无需繁琐的训练或微调。该方法通过自注意力特征注入,在每个扩散步骤中注入前一帧的特征,以确保编辑后的视频外观连贯一致,解决了编辑过程中可能出现的外观变化问题。
此外,为提高算法的时间稳定性,引入了潜在更新机制,通过能量函数增强一致性,有效减少了时间闪烁的影响。
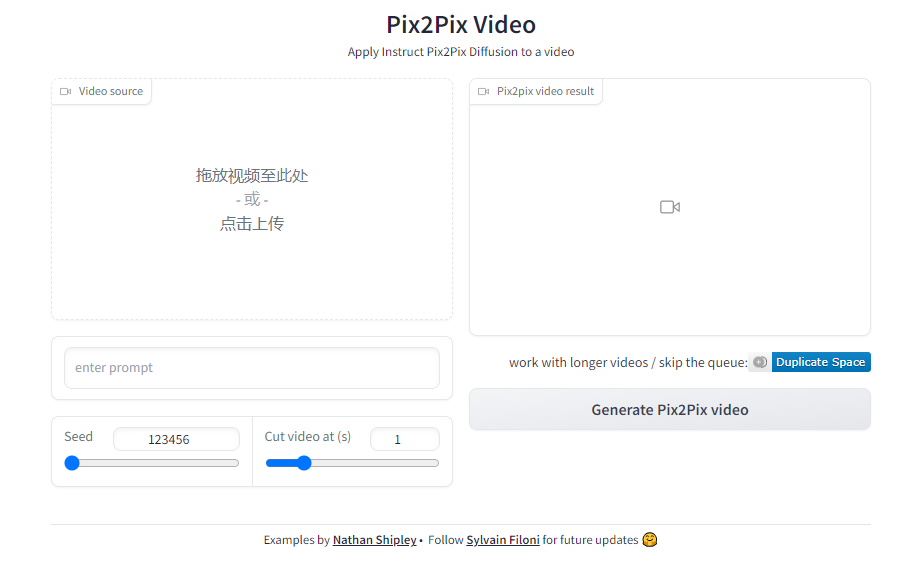
项目地址:https://huggingface.co/spaces/fffiloni/Pix2Pix-Video
大规模图像生成扩散模型在静态图像生成方面表现出色,但在处理视频编辑时面临挑战。为了应对这一挑战,Pix2Video采用了深度条件稳定扩散模型,通过对每帧进行深度预测,并将其作为模型的额外输入,以捕捉运动动态和几何变化。
自注意力特征注入是该方法的关键步骤,通过在解码器层执行特征注入,确保在保持外观一致性的同时避免高频结构变化。此外,为提高时间稳定性,潜在更新机制通过额外的指导来更新隐变量,通过能量函数增强一致性,降低了时间闪烁的影响。
Pix2Video的实验证明了其方法的有效性,并与四种不同的先前工作进行了比较,证明了文本引导的视频编辑是可能的,无需复杂的预处理或视频个性化微调。该研究为实时互动视频编辑领域提供了一种创新方法,具有潜在的应用前景。
0000
评论列表
共(0)条相关推荐
雷军确认小米15涨价:小米14将是最后一款3999元数字旗舰
小米CEO雷军近日在社交媒体上宣布,即将发布的小米15系列将告别之前的3999元定价,迎来价格的上涨。这一决定是在对去年所做承诺的延续,雷军曾表示小米14将是最后一款定价在3999元的小米数字旗舰手机。站长网2024-10-25 08:22:410000AI绘画工具助力时尚界,抖音博主打造葡萄时装秀获赞5.4万
近日,抖音博主“知伊”发布了一条名为“田园葡萄时装秀”的视频,引起了网友的广泛关注。视频中展示了穿着“葡萄服饰”的女子在田间走秀的场景,通过图片轮播的方式展现了这一独特的时装秀。这条视频在抖音上获得了5.4万的点赞数,而博主“知伊”的粉丝数量约为3500个。站长网2023-09-12 14:19:26000016万抖音网友围观AI谈恋爱 ChatGPT语音功能被网友玩坏了
ChatGPT语音功能被网友玩坏了!最近,抖音博主“新竹AI”让两个手机上的ChatGPT互相亲密交流,这场AI之间的恋爱对话被超16万网友围观。这段对话开始于男生AI的邀请,他提议一次浪漫的约会,包括前往酒吧放松、海边漫步欣赏海浪声音,以及在有情调的餐厅享受晚餐。他表达了愿意满足女生AI的喜好的决心。站长网2023-10-31 14:22:300000不是吹牛?华为P60用户靠卫星通信获救,一次真就续一生
相信目前绝大多数用户的手机都是不支持卫星通信的,毫不客气地说,即使有这个功能,很多人也只会当做一个新鲜玩意,试一试就行了,因为日常生活中是不会遇到那种极端情况,必须要用卫星才能和外界取得联系的。站长网2023-05-23 16:50:000000OpenAI推出大学教育版本ChatGPT Edu 数据将不用于训练模型
OpenAI宣布推出ChatGPTEdu,ChatGPTEdu是为大学而设计的版本,旨在负责地向学生、教职员工、研究人员和校园运营部署人工智能。搭载GPT-4o,ChatGPTEdu可以跨文本和视觉进行推理,使用先进工具如数据分析。这一新产品包括企业级安全性和控制,价格适中,适合教育机构使用。ChatGPTEdu特点包括了:站长网2024-05-31 19:11:500000