DeepMind提出语言模型训练新方法DiLoCo 通信量减少500倍
要点:
DeepMind的研究团队提出了分布式低通信(DiLoCo)训练语言模型的方法,采用分布式优化算法,使语言模型在连接性较差的设备集群上训练,性能超过完全同步模型,通信开销减少500倍。
DiLoCo借鉴联邦学习文献,采用一种变体的联邦平均(FedAvg)算法,结合动量优化器,通过将内部优化器替换为AdamW和外部优化器替换为Nesterov Momentum,有效应对传统训练方法的挑战。
DiLoCo通过限制共位要求、降低通信频率和设备异构性等三个关键因素,实现了在多台设备可用但连接较差的情况下,分布式训练变压器语言模型的鲁棒性和效果,并在C4数据集上展现出与完全同步优化相媲美的性能。
DeepMind的最新研究在语言模型训练领域取得突破,提出了分布式低通信(DiLoCo)方法。这一方法采用分布式优化算法,使得语言模型可以在连接性较差的设备集群上训练,不仅性能超越完全同步模型,而且通信开销降低了500倍。为了实现这一创新,研究人员借鉴了联邦学习文献,提出了一种基于动量优化器的联邦平均算法的变体,通过替换内部和外部优化器,成功应对传统训练方法的工程和基础设施挑战。
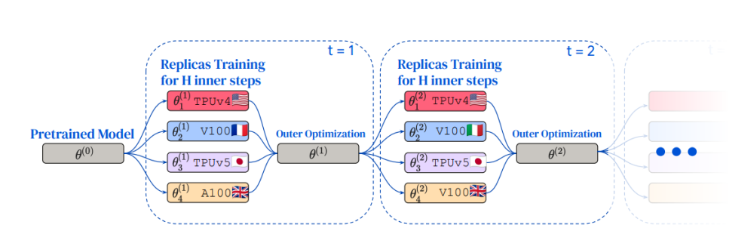
DiLoCo方法的关键优势体现在三个方面:首先,对设备的共位要求较低,减轻了后勤负担;其次,通信频率降低,工作者不需要在每一步都进行通信,大大减少了通信开销;最后,设备异构性的引入增强了灵活性,同一集群内的设备可以不同类型,提高了适应性。
在DiLoCo的训练过程中,通过复制预训练模型,每个工作者独立且并行地在自己的数据片段上训练模型。随后,工作者平均其外部梯度,外部优化器更新全局参数,这一过程重复多次。值得注意的是,每个复制品可以在不同的全局位置使用各种加速器进行训练。
在C4数据集上的实验证明,DiLoCo在8个工作者的情况下展现出与完全同步优化相当的性能,同时通信开销降低了500倍。此外,DiLoCo对每个工作者数据分布的变化表现出卓越的稳健性,并且能够适应训练过程中资源可用性的变化。
综合而言,DiLoCo方法为分布式训练提供了一个强大而有效的解决方案,特别是在多台设备可用但连接性较差的情况下。这一创新性的方法不仅克服了基础设施挑战,还展示出卓越的性能和适应性,标志着语言模型优化领域的重大进展。
今日AI:Suno《宫保鸡丁》杀入全球AI音乐榜前十;AI太烧钱? Stability AI CEO辞职;Domo AI上线照片转视频功能;Viggle让静态图片跳舞
欢迎来到【今日AI】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/🤖📱💼AI应用DomoAI上线新功能只需一张照片和视频即可让人物动起来【AiBase提要:】⭐️只需一张照片和一个动态视频就可以让静态的图像跳舞站长网2024-03-25 19:13:160000嘀嗒出行再向港交所提交上市申请 2023年收入约8.151亿元
近日,顺风车行业巨头嘀嗒出行(DidaInc.)再次向港交所递交了主板上市申请,这次是在3月19日完成的。此前,该公司已经于2020年10月8日、2021年4月13日、2023年2月20日和2023年8月30日先后四次递交上市申请,但均未能成功。而此次申请,嘀嗒出行得到了中金公司、海通国际及野村国际的联合保荐支持。站长网2024-03-20 10:01:000002华为余承东:AITO 问界 M9 搭载的黑科技包括 AI 大模型
在华为nova11系列及全场景新品发布会上,AITO问界M5系列华为高阶智能驾驶版(问界M5智驾版)正式上市,包含两种版本、四种车型,售价27.98万-30.98万元。据介绍,问界M5智驾版将成为首个同时搭载HUAWEIADS2.0?阶智能驾驶系统和鸿蒙智能座舱3.0的车型,提供无限接近L3的智能驾驶体验。站长网2023-04-18 09:12:040000Sora刷屏视频出现多处失误 OpenAI回应:正在积极改进
站长之家(ChinaZ.com)2月19日消息:自2月18日OpenAI发布文生视频AI工具Sora以来,其影响已逐渐渗透到科技圈、资本圈和影视圈等多个领域。众多专家和业内人士纷纷对其展开深入探讨,同时针对Sora目前存在的问题和不足也进行了深入研究。站长网2024-02-19 08:53:220000即将复播!董宇辉成东方甄选高级合伙人
东方甄选近日发布直播预告,宣布12月18日晚8点,俞敏洪和董宇辉将在东方甄选直播间见面。此次直播预告还透露了一个重要信息,即董宇辉的身份已经升级为东方甄选高级合伙人。此前,对于董宇辉的未来发展,俞敏洪在直播中表示,董宇辉未来一定会拥有话语权。而在12月16日晚的直播中,俞敏洪和董宇辉共同回应了近期风波以及外界关心的问题。站长网2023-12-18 11:19:590000













