UltraFastBERT:推理过程仅用0.3%神经元,性能与类似的BERT模型相当
**划重点:**
1. 🧠 **创新介绍:** ETH Zurich研究人员成功开发了UltraFastBERT,通过使用快速前馈网络(FFFs)在推理过程中仅使用0.3%的神经元,实现了与其他模型相当的性能水平。
2. 🚄 **性能提升:** 通过简化的FFFs替代传统模型的前馈网络,UltraFastBERT在保持高效语言建模的同时,取得了显著的速度提升,甚至达到48倍到78倍的CPU上的推理速度提升。
3. 🛠 **潜在应用:** 该研究不仅提供了高水平的CPU和PyTorch实现,还建议通过混合稀疏张量和设备特定优化,以及通过多个FFF树的联合计算,进一步加速大型语言模型,如GPT-3。
近日,ETH Zurich的研究人员成功推出了一项创新性的技术——UltraFastBERT,该技术通过在推理过程中仅使用0.3%的神经元,实现了与其他类似BERT模型相当的性能水平。这一创新主要通过引入快速前馈网络(FFFs)来解决在推理过程中减少神经元数量的问题,相较于基准实现,取得了显著的速度提升。
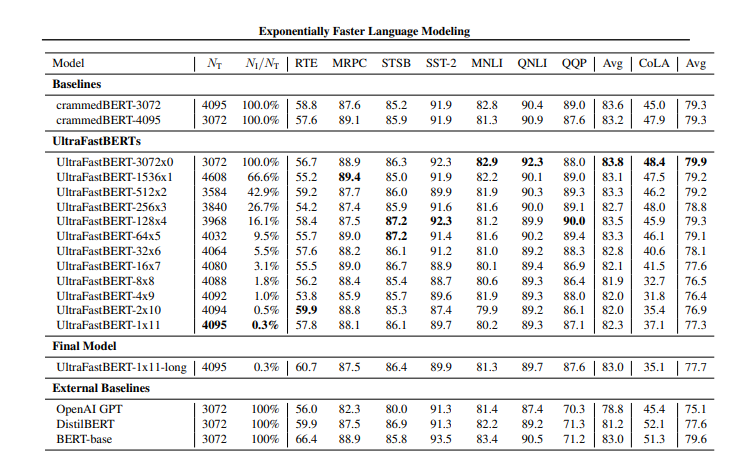
研究人员提供了代码、基准设置以及模型权重,支持了这一方法的有效性。他们建议进一步探索通过混合稀疏张量和设备特定优化,以及在大型语言模型中应用多个FFF树的潜在性能提升。
UltraFastBERT在推理过程中展现了高效的语言建模,通过将传统模型的前馈网络替换为简化的FFFs,使用一致的激活函数和所有节点输出权重,同时消除了偏差。多个FFF树协同计算中间层输出,允许多样化的架构。所提供的高水平CPU和PyTorch实现显著提升了速度,而研究还探讨了通过多个FFF树和替换大型语言模型前馈网络为FFFs,实现潜在加速的可能性。为设备特定优化,建议使用Intel MKL和NVIDIA cuBLAS。
UltraFastBERT不仅在推理中仅使用0.3%的神经元的情况下实现了与BERT-base相当的性能,而且在仅使用单个GPU进行一天训练的情况下,仍保持至少96.0%的GLUE预测性能。研究还展示了通过快速前馈层实现显著的速度提升,达到48倍到78倍的CPU上的即时推理速度提升,以及GPU上的3.15倍速度提升,表明在替换大型模型方面存在潜在可能性。
总体而言,UltraFastBERT是对BERT的修改,实现了在推理过程中仅使用少量神经元的高效语言建模。该模型通过FFFs实现了显著的速度提升,提供的CPU和PyTorch实现分别实现了78倍和40倍的速度提升。研究建议通过实现有条件神经执行的基元,进一步加速语言建模。尽管仅使用0.3%的神经元,UltraFastBERT的最佳模型与BERT-base的性能相当,展示了高效语言建模的潜力。UltraFastBERT展示了高效语言建模的潜在进展,为未来更快、资源友好的模型铺平了道路。
未来研究的建议包括使用混合向量级稀疏张量和设备特定优化实现高效的FFF推理,探索有条件神经执行加速语言建模的全部潜力,以及通过将前馈网络替换为FFFs优化大型语言模型的潜在性。未来的工作可能着重于在流行框架如PyTorch或TensorFlow中实现可重现的模型,并进行广泛的基准测试,以评估UltraFastBERT及类似高效语言模型的性能和实际影响。
论文地址:https://arxiv.org/abs/2311.10770
OpenAI 宣布新领导层以推动增长
划重点:⭐️OpenAI任命SarahFriar为首席财务官,KevinWeil为首席产品官⭐️Friar曾担任Nextdoor的CEO和Square的CFO,Weil曾在PlanetLabs担任产品和业务总裁⭐️新领导将助力OpenAI扩展运营,实现研究与市场需求的平衡站长网2024-06-11 18:06:510000Canalys:预计2023年全球智能手机市场出货量下滑收窄至5%
科技市场独立分析机构Canalys表示,2022年全球智能手机市场经历大幅下滑12%后,2023年市场呈现初步的复苏迹象。尽管预计2023年出货量仍下降5%,但下跌趋势已有所放缓。今年,中东、非洲和拉丁美洲等地区将重拾增长,增幅分别为9%、3%和2%。站长网2023-11-27 10:15:440000免费在线AI图像处理软件Clipdrop 集成 Stable Diffusion XL 图像生成模型
Clipdrop是一款免费在线的Ai图像处理应用,其母公司initML已被StabilityAI收购并集成了StabilityAI公司的新版图像生成模型StableDiffusionXL。站长网2023-07-27 16:23:010000AI 模型有助于确定患者癌症的起源部位
本文概要:1.麻省理工学院研究人员开发了一个机器学习模型,可以帮助确定患者癌症起源部位。2.通过分析约400个基因的序列,该模型能够准确分类至少40%的未知起源的肿瘤。3.这种方法可以提高患者的治疗选择,使更多人能够接受针对肿瘤起源部位的个体化治疗。站长网2023-08-08 15:19:490000跟安卓玩法一样了!苹果允许iPhone用户从网站下载App
快科技3月13日消息,上周苹果推送了iOS17.4正式版,允许欧盟用户通过第三方应用商店下载安装应用程序,俗称侧载”。不止于此,针对欧盟用户,苹果进一步调整了侧载功能,用户不仅可以从第三方应用商店下载应用,还可以从网站下载安装应用,这意味着iOS在欧盟的侧载方式跟安卓完全一样了。苹果方面确认,这项调整会在今年春季晚些时候上线,届时欧盟用户不需要依赖应用商店就能安装应用。站长网2024-03-13 11:51:4600057