用视觉来做Prompt!沈向洋展示IDEA研究院新模型,无需训练或微调,开箱即用
用视觉来做Prompt,是种什么体验?
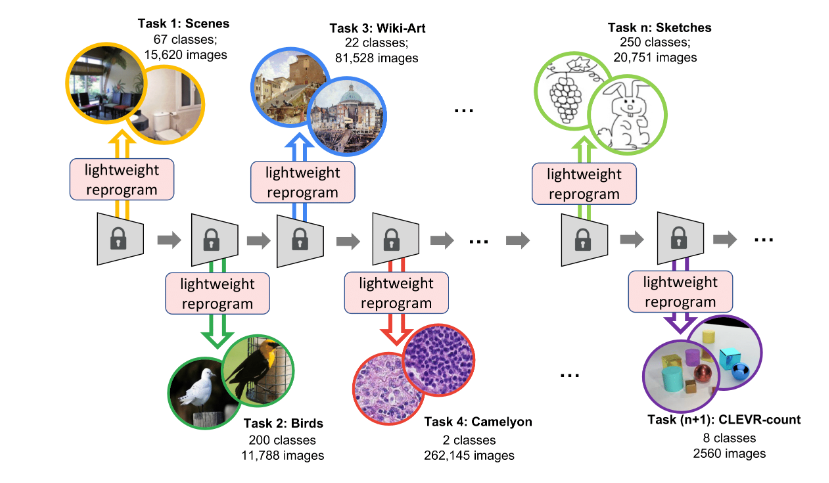
只需在图里随便框一下,结果秒秒钟圈出同一类别!
即便是那种GPT-4V都难搞定的数米粒的环节。只需要你手动拉一下框,就能找出所有米粒来。
新的目标检测范式,有了!
刚刚结束的IDEA年度大会上,IDEA研究院创院理事长、美国国家工程院外籍院士沈向洋展示了最新研究成果——
基于视觉提示(Visual Prompt)模型T-Rex。
整个流程交互,开箱即用,只需几步就可以完成。
此前,Meta开源的SAM分割一切模型,直接让CV领域迎来了GPT-3时刻,但仍是基于文本prompt的范式,在应对一些复杂、罕见场景就会比较难办。
现在以图换图的方式,就能轻松迎刃而解。
除此之外,整场大会也是干货满满,比如Think-on-Graph知识驱动大模型、开发者平台MoonBit月兔、AI科研神器ReadPaper更新2.0、SPU机密计算协处理器、可控人像视频生成平台HiveNet等等。
最后,沈向洋还分享了过去几年时间花时间最多的一个项目:低空经济。
我相信当低空经济发展到相对成熟时,同一个时间点,在深圳的天空中每天有10万架无人机,每天飞起来的有百万架无人机。
用视觉来做Prompt
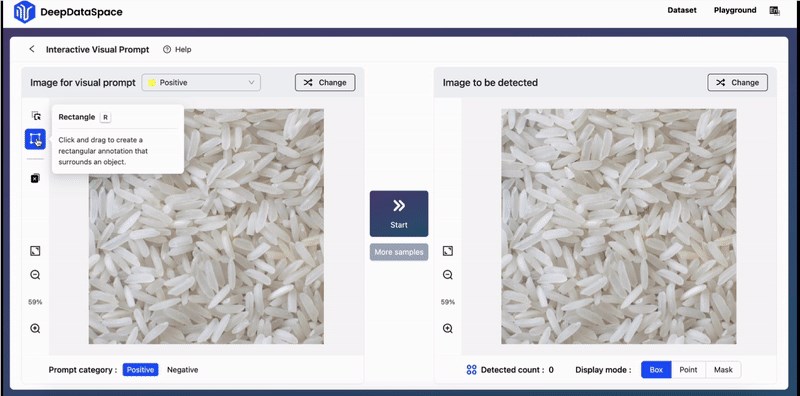
除了基础的单轮提示功能,T-Rex还支持三种进阶模式。
多轮正例模式
有点像多轮对话,以得出更为精确的结果,不至于出现漏检的情况。
正例 负例模式
适用于视觉提示带有二义性造成误检的场景。
* 跨图模式。
用单张参考图提示,来检测其他的图。

据介绍,T-Rex不会受到预定义类别限制,能够利用视觉示例指定检测目标,这样一来就克服有些物体难以用文字充分表达的问题,以提高提示效率。尤其像一些工业场景中的复杂组件等。
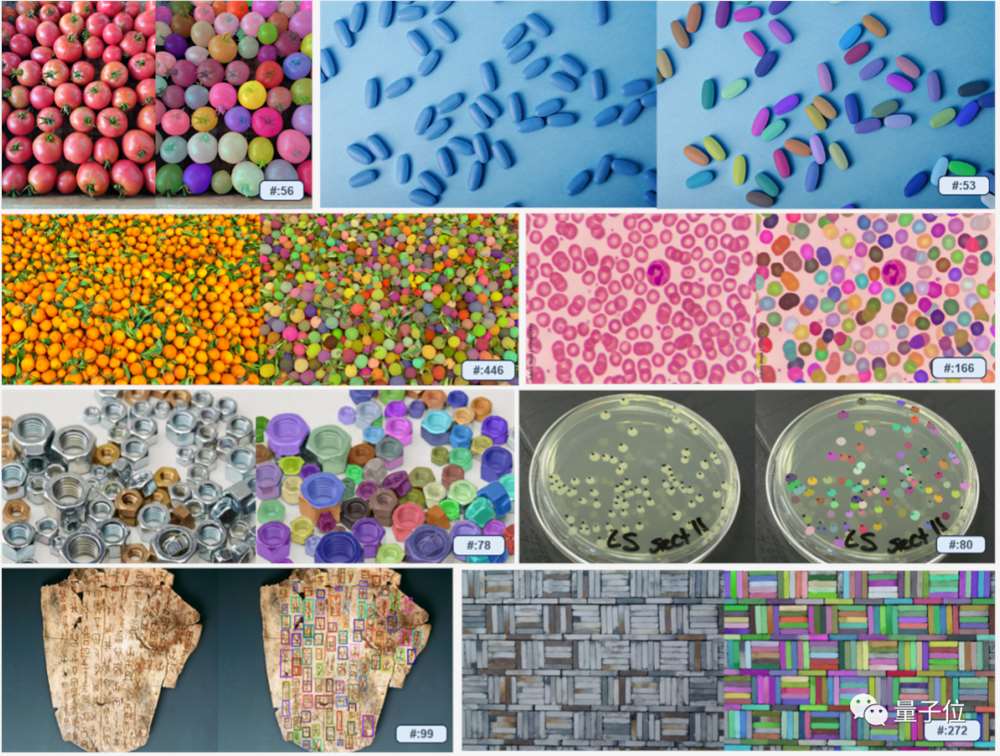
除此之外,通过与用户交互的方式,也可以随时快速地评估检测结果,并进行纠错等。
T-Rex主要由三个组件组成:图像编码器、提示编码器以及框解码器。
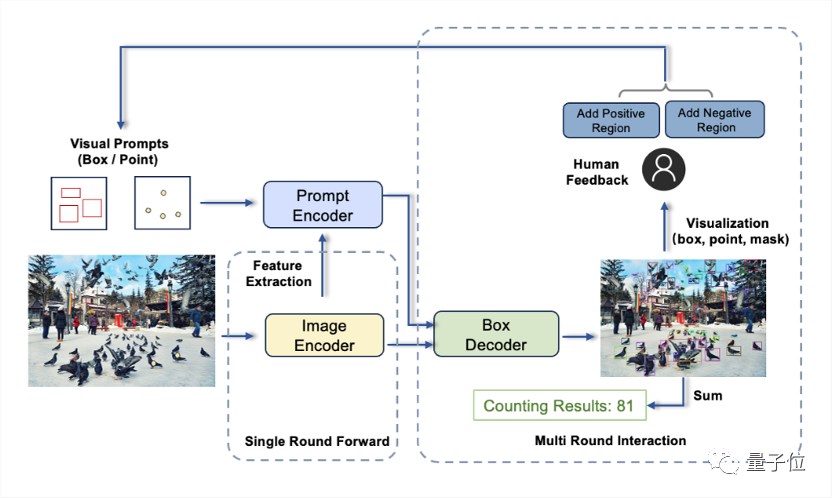
这项工作来自IDEA研究院计算机视觉与机器人研究中心。
该团队此前开源的目标检测模型DINO是首个在COCO目标检测上取得榜单第一的DETR类模型;在Github上大火(至今狂揽11K星)的零样本检测器Grounding DINO与能够检测、分割一切的Grounded SAM。更多技术细节可戳文末链接。
整场大会干货满满
除此之外,IDEA大会上还重点分享了几个研究成果。
比如Think-on-Graph知识驱动大模型,简单来说就是将大模型与知识图谱结合。
大模型擅长意图理解和自主学习,而知识图谱因其结构化的知识存储方式,更擅长逻辑链条推理。
Think-on-Graph通过驱动大模型agent在知识图谱上“思考”,逐步搜索推理出最优答案(在知识图谱的关联实体上一步一步搜索推理)。每一步推理中,大模型都亲自参与,与知识图谱相互取长补短。
MoonBit月兔,这是由Wasm驱动,专为云计算与边缘计算设计的开发者平台。
它不仅提供通用程序语言设计,还整合了编译器、构建系统、集成开发环境(IDE)、部署工具等版块,来提升开发体验与效率。
此前发布的科研神器ReadPaper也更新至2.0,发布会现场演示了阅读copilot、润色copilot等新功能。
发布会最后,沈向洋发布《低空经济发展白皮书——深圳方案》,在其智能融合低空系统(Smart Integrated Lower Airspace System,SILAS)中,提出时空进程(Temporal Spatial Process)新概念。
T-Rex链接:
https://trex-counting.github.io/
—完—
复旦大学云上科研智算平台上线 支持千亿参数大模型加速运行
在今日的复旦大学智能计算平台暨首届科学智算高端论坛上,国内高校最大的科研智能计算平台CFFF的“切问”一号和“近思”一号在复旦大学正式上线。这一新型的“大科学装置”能够高效地进行超千卡的并行智能计算,并支持千亿参数的大模型加速运行。在上线仪式上,复旦大学与阿里巴巴集团、中国电信分别签署了战略合作协议,共同建设全国高校中算力最强的专用高性能智能计算平台。站长网2023-06-28 09:26:540000618大促将至,数码产品价格“大跳水”,推荐这几款骁龙8 手机
尽管目前骁龙8Gen2的表现备受大家好评,成为2023年众多高端手机的标配芯片,但其相对比较高昂的价格属实不大适合普通消费者。倘若不需要追求极致性能,去年下半年发布的骁龙8也是个不错选择,它采用了台积电4nm制程工艺,并且安兔兔跑分与骁龙8Gen2只相差20万,因此,在日常使用中,二者流畅性差距非常小。站长网2023-05-24 08:22:590000南加州大学提出通道式轻量级重编码CLR 解决大语言模型灾难性遗忘问题
要点:1.南加州大学和GoogleResearch提出了通道式轻量级重编码(Channel-wiseLightweightReprogramming)方法,用于解决持续学习问题,通过在固定任务不变的模型背骨干中添加轻量级可训练模块,对每层通道的特征图进行重编程,以适应新任务,仅占0.6%的额外参数。站长网2023-10-13 14:04:220000Redmi Note12T Pro今日10点开启预售 配备144Hz LCD原色屏
今日10点,RedmiNote12TPro手机将正式开启预售。其最大的亮点是采用高素质LCD原色屏幕,支持144Hz刷新率、7挡变速调节以及全程DC调光防频闪等。此外,RedmiNote12TPro搭载了台积电4nm制程的天玑8200-Ultra芯片,采用小米自研性能调度技术,跑分超过90万。内存组合为LPDDR5UFS3.1,最大提供12GB512GB版。站长网2023-05-30 09:15:460000网易游戏发布未成年暑期限玩通知:游戏总时长不超过24小时
网易游戏官方今日正式宣布,为确保未成年人在暑假期间能够合理安排学习与娱乐时间,特别制定了暑期游戏时间限制政策。根据新规,未成年玩家将仅能在每周五、周六、周日的晚上20点至21点期间登录游戏,整个假期内的游戏总时长严格控制在不超过24小时。这一举措彰显了网易对未成年人健康成长的深切关怀与责任担当。站长网2024-07-03 15:41:140001