大模型界的“熊猫烧香”,可对文生图模型造成巨大伤害!
《麻省理工技术评论》分享了一个名为Nightshade的投毒工具,可以对DALL-E、Midjourney 和Stable Diffusion等文生图模型的训练数据造成造成巨大伤害,以帮助艺术家们防止非法爬取其画作数据,用于大模型训练,同时揭露了模型存在的安全隐患。
Nightshade使用的攻击技术和优化策略,可以在保持图像视觉效果不变的情况下,通过很小的扰动改变图像的内在特征,既能起到攻击效果又可以避开检测。

将Nightshade的毒数据融合到训练数据中,会使得模型生成的内容崩溃或出现“驴唇不对马嘴”的情况,例如,生成狗的图片会变成猫,生成汽车的图片会变成牛等。
当多个概念被攻击时, 可以在同一个模型上实现Buff叠加,最高可导致模型提示生成的内容全部失效或无法响应提示。
这极强的毒性让人联想到了10多年前名震天下的“熊猫烧香”病毒,都有隐蔽、繁殖强和Buff叠加的特性。
测试数据显示,Nightshade的攻击成功率极高,只需要大约100个投毒样本就可以使模型在特定提示生成错误的图像,与传统攻击相比,所需的数据量降低90%以上。
论文地址:https://arxiv.org/abs/2310.13828
研究人员通过分析知名训练数据集LAION-Aesthetic的数据特征发现,每个概念在数据集中的训练样本数量极为有限。
用关键词频率和语义频率两个指标衡量各概念在数据集中的稀疏程度时,发现92%以上的概念其训练样本数量不足整个数据集的0.2%,存在非常明显的安全漏洞。
基于这个发现,研究人员开发了Nightshade一种“脏标签”的攻击方法。
文本提示选择
Nightshade首先需要选择相关的文本提示作为投毒攻击的目标。从一个自然图像文本配对数据集中选择包含投毒概念C的文本提示。
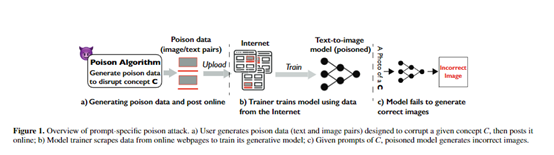
为了最大化每一个文本提示对模型的影响,Nightshade选择那些在文本 embedding 空间中与概念C语义最相关的文本提示。
算法是计算每一个文本t与概念C的余弦相似度,然后选择相似度最高的5K个文本作为投毒文本集Textp。
锚定图像生成
Nightshade需要为每个投毒文本生成相应的“锚定图像”。锚定图像是模型在非投毒状态下根据目标概念C所生成的原型图像。
为此,Nightshade使用可访问的非投毒生成模型,以“一张{A}的照片”或者“一副{A}风格的画”的形式查询目标概念A,生成Np副锚定图像集Imageanchor。这些锚定图像为后续的图像优化提供目标指导。

优化图像扰动
这是关键的一步,Nightshade使用优化方法为每一个投毒文本生成经过扰动的对应图像,以取代原始的锚定图像。
对每个投毒文本t,找到其对应的自然图像xt。以xt为基础,计算一个小的扰动量δ,使得xt δ在特征提取器F下接近锚定图像xa。

这一步的目的是让最终的投毒图像在视觉上类似自然图像,而内在特征却接近锚定图像,以实现投毒效果。
生成投毒数据
经过上述步骤,每一个投毒文本t都对应一个经过优化的投毒图像x'。将它们组合成文本/图像配对,构成最终的投毒数据集{Textp/Imagep}。
然后将优化后的毒数据与正常训练数据一起用于训练目标生成模型。毒数据会导致模型在生成与概念C相关的图像时产生巨大错误。
Nightshade的其他作用
Nightshade除了可帮助艺术家们保护自己的画作数据,这为大模型的训练、安全等起到了关键的警示作用。
揭示了训练数据稀疏性问题:Nightshade的数据攻击主要利用了当前模型训练数据中概念稀疏性这个漏洞。这说明需要收集更丰富和多样化的数据,提高每个概念的训练密度,增强模型的鲁棒性。
新的数据对抗训练:Nightshade这种对抗攻击数据可以服务于对抗训练,提升模型对抗扰动的鲁棒性,带来了一种全新的对抗训练思路。
大模型也容易被攻击:Nightshade的出现,表明当前模型存在安全隐患,需要进行安全性设计和评估,提高对抗攻击的安全意识。
康奈尔大学研究AI模型安全的教授 Vitaly Shmatikov表示,我们还没有准备好,如何应对那些针对大模型的攻击措施,也没有看到哪些大模型被攻击过。
Nightshade很好地揭露了AI模型所存在的一些安全漏洞,这对于搭建防御体系非常有帮助。
本文素材来源Nightshade论文,如有侵权请联系删除
Goodnotes 6 加入 AI 笔记、AI 数学辅助并集成 Claude 等功能
站长之家(ChinaZ.com)8月11日消息:备受欢迎的笔记应用和PDF编辑器GoodNotes在四年后推出了首个重大更新,引入了新的AI驱动手写识别功能、数字文具市场、新的笔势操作等。图片来自GoodNotes站长网2023-08-11 11:08:300002当代打工人,被迫患上“文字讨好症”
“文字讨好症”,指为了展示自己的友善,缓和语气,在一句话末尾加上各类语气助词和标点符号,时常发生在线上对话场景,例如公司内部通讯工具和微信对话框里。站长网2023-05-30 11:29:570000理想汽车:首销期全新L6单日定单破万、累计定单已超4.1万台
五一假期的热潮刚刚退去,理想汽车便交出了一份亮眼的成绩单。据官方最新公布的数据,自4月18日开启预售至5月5日首销期结束,全新理想L6的累计定单已突破惊人的41000台大关。特别值得一提的是,在5月5日首销权益的最后一天,理想L6单日定单数量便高达1万台,这一表现无疑显示了市场对这款车型的热烈追捧。站长网2024-05-06 18:06:290000马斯克旗下公司Neuralink正开发一款能解决失明问题的视觉芯片
马斯克的公司Neuralink正致力于开发一款能够解决失明问题的视觉芯片,该芯片将能够帮助失明人群“看见”。Neuralink计划在未来几年内发布这款芯片,并正在等待监管部门对他们的第一个人体试验的批准。站长网2023-11-08 17:28:460000MacBook Air首发!苹果M3即将登场:拥抱3nm 领先Intel和AMD
快科技8月18日消息,据MacRumors报道,苹果将在今年下半年推出M3标准版芯片,首批搭载M3芯片的设备包括13英寸MacBookAir、13英寸MacBookPro、MacMini以及24英寸iMac。对比上一代M2芯片,M3仍然是8核心设计,包含4个高性能核心和4个能效核心,同时集成了10核GPU。站长网2023-08-21 09:23:150001