LeCun发文质疑LLM推理能力 大模型涌现离不开上下文学习
站长网2023-11-24 18:05:530阅
要点:
LeCun认为,大语言模型(LLM)缺乏规划推理能力,其涌现能力主要源自上下文学习而非真正的推理。
研究表明,针对复杂规划任务,如国际规划大赛中的问题,LLM的性能较差,其推理能力在特定领域受限,而涌现能力主要体现在简单任务和事先知道答案的情境中。
论文指出对LLM的规划任务研究存在问题,包括对计划知识和实际执行计划的混淆,以及对任务领域知识的需求,最终得出LLM缺乏自主规划和真正推理的结论。
近期,LeCun在推特上引发了关于大语言模型(LLM)推理能力的讨论,强调LLM缺乏真正的规划推理能力,其涌现能力实际上是上下文学习的结果。研究通过多个实验验证LLM在复杂规划任务上表现不佳,强调其能力受限于任务复杂度。
研究团队在GPT-4上进行的实验显示,在国际规划竞赛中,LLM的自主生成可执行计划的成功率相当有限。对于声称展示了LLM规划能力的论文,文章指出其往往混淆了从LLM中提取的计划知识和实际可执行计划,最终认为LLM缺乏真正的规划和推理能力。
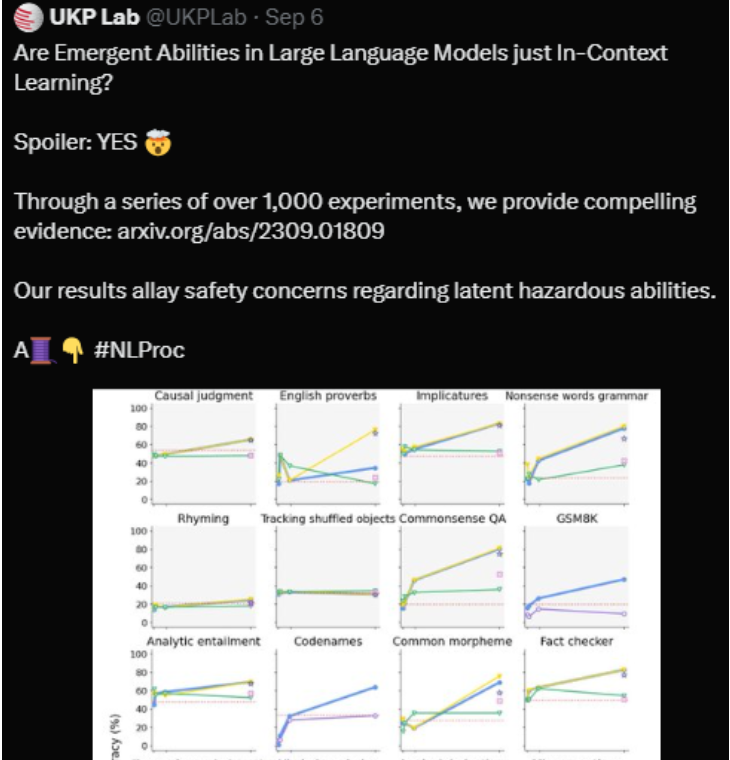
文章还提到,对于LLM的规划任务研究存在一些问题,包括领域知识和实际执行计划的混淆。研究团队通过混淆规划问题中的动作和对象的名称来降低近似检索的有效性,挑战LLM的经验表现。
尽管进行了微调和不断提示的尝试,但改进LLM的规划能力仍然困难,且可能只是将规划任务转化为基于内存的检索。最终,文章总结认为,LLM的涌现能力主要体现在任务简单且问题已知的情境中,而在复杂规划任务和推理方面存在局限。
这一讨论对于理解大语言模型的真实能力,特别是在推理和规划领域,提供了重要的见解。随着对LLM的研究的不断深入,对其真实能力的理解也在逐渐清晰,为未来自然语言处理研究方向提供了有价值的参考。
0000
评论列表
共(0)条相关推荐
腾讯QQWindows 9.90体验版上线 采用全新登录以及交互界面
昨日,腾讯QQWindows9.90体验版上线,适用于Windows7SP1及以上版本,全新体验版的WindowsQQ新增了对64位系统的支持,基于NT架构,正式实现了macOS、Linux和Windows三个平台的统一。新版QQ采用了全新登录界面以及交互界面,支持表情分类和黄脸超级表情,还具备夜间模式一键开启等功能。站长网2023-07-04 15:58:100000Nature新规:用ChatGPT写论文可以,但不能列为作者
Nature针对ChatGPT代写学术文章、被列为作者等问题,给出了两项原则:任何大型语言模型工具都不能成为论文作者;如在论文创作中用过相关工具,作者应在“方法”或“致谢”或适当的部分明确说明。目前,上述要求已经添进作者投稿指南中。站长网2023-05-01 10:19:340000荣耀Magic V2发布 赵明称折叠手机进入毫米级时代
荣耀公司在昨日举行的新品发布会上,正式推出了荣耀MagicV2。这款手机采用了第二代骁龙8领先版,并通过新材料和新技术的应用,将机身厚度和重量进一步降低,展现了荣耀公司在技术创新和产品设计上的不懈追求。站长网2023-07-13 21:47:410000海艺AI:一个免费且高效易用的AIGC绘图工具
海艺AI是一款国产AI绘画工具,通过AI技术提供高效易用的绘图功能。它具备12000多种风格的模型库和专业功能,如图生图、局部重绘、LoRA、ControlNet等,让用户可以进行高质量的创作。官网地址:https://www.seaart.ai/home站长网2023-07-27 11:52:0400032ChatGPT 联合创始人 Greg Brockman 在 UND 谈论人工智能的未来
站长之家(ChinaZ.com)9月28日消息:当UND校长AndrewArmacost和GregBrockman进行对话时,他估计大约有550人在听众席上。这场访谈在UND纪念联盟大厅举行,围绕着Brockman的过去和人工智能的未来展开。「我们很高兴你能来到这里,」Armacost在开始谈话时说。站长网2023-09-29 10:03:350001